Pigsty v2.3.1 现已发布。这个版本中PGVECTOR迎来 v0.5 史诗级更新,添加了新的 HNSW 索引支持。也对新发布的 PostgreSQL 16 RC1 提供了支持。此外,官方文档现在提供中文版本,现有文档也进行了丰富与完善。最后,还有例行的软件版本更新与问题修复。
HNSW 版 PGVECTOR?
PGVECTOR 是一个非常实用强大的 PostgreSQL 扩展插件,允许你在现有的关系型数据库 PostgreSQL 上拥有完整的向量数据存储检索能力。
9月1号,PGVECTOR 发布了一个重大版本更新 v0.5 ,引入了一种全新类型的索引:HNSW 。在 ANN Benchmark 中,召回率和性能表现上相比原有的 IVFFLAT 索引都有巨大的提升,在综合性能表现上相比专业向量数据库毫不逊色! 此外,在距离的计算性能上相比 0.4.4 有显著提升(特别是L2欧式距离)。最后是 IVFFLAT 索引的并行创建能力:可以让耗时的索引创建操作加速N倍!
向量数据库的利弊权衡
向量数据库索引算法也有一个 “不可能三角”:质量、效率、成本
质量:查询结果的召回率(正确程度)
效率:查询的响应时间
成本:查询所需的内存大小//索引构建速度
对于向量数据库的典型场景 —— 语义搜索而言。最重要的属性毫无疑问是召回率,这会直接影响终端用户的体验。性能通常来说不是大问题,够用就行:模型编码耗时通常在几十毫秒到上百毫秒,把10毫秒的查询优化到1毫秒对用户体验来说毫无意义;吞吐可以通过无限拖从库的方式解决。内存使用/构建速度通常是最不重要的 —— 对用户无感知,而且只要能跑起来,以目前的内存价格,加钱加资源能解决的问题通常不算什么问题。
经典的暴力全表搜索算法有着无可替代的最好质量,但是性能很差,所需内存资源极少(顺序扫一遍,轮流载入内存)。PGVector 原先使用的 IVFFLAT 索引有着很好的性能,但召回率表现一般,内存使用一般。而现在新增的 HNSW 索引,在召回率和性能上都有优秀的表现,最大的缺点在于索引构建速度慢/内存使用量高。
HNSW 算法几乎是专用向量数据库的标配,因为它在质量、性能上都有优异的表现。虽然有索引构建速度慢的缺陷,但它也有几个额外的好处:
-
“增量维护”:使用 HNSW索引,你可以在空表上创建索引并随时添加向量,而不会影响召回率!这与 IVFFLAT 不同:IVFFLAT在构建索引之前首先需要加载向量数据,使用 Kmeans 以找到最佳中心点,才能有最好的召回率。当你更新了许多数据时,可能需要重建索引,才能有最好的召回效果。
-
更新和删除:pgvector 的 HNSW 实现允许更新和删除,你可以使用标准的 UPDATE / DELETE 语句。许多 HNSW 向量数据库实现都不支持这一功能!
这意味着 HNSW 索引几乎不需要什么额外的维护工作:你可以并发写入/更新,增量维护,在不影响读写请求的前提下新建索引,也不用担心数据的变化会影响索引的质量。数据是持久化的,受到PITR时间点恢复的保护,并且可以使用标准 WAL 基础设施可无缝复制到从库上。
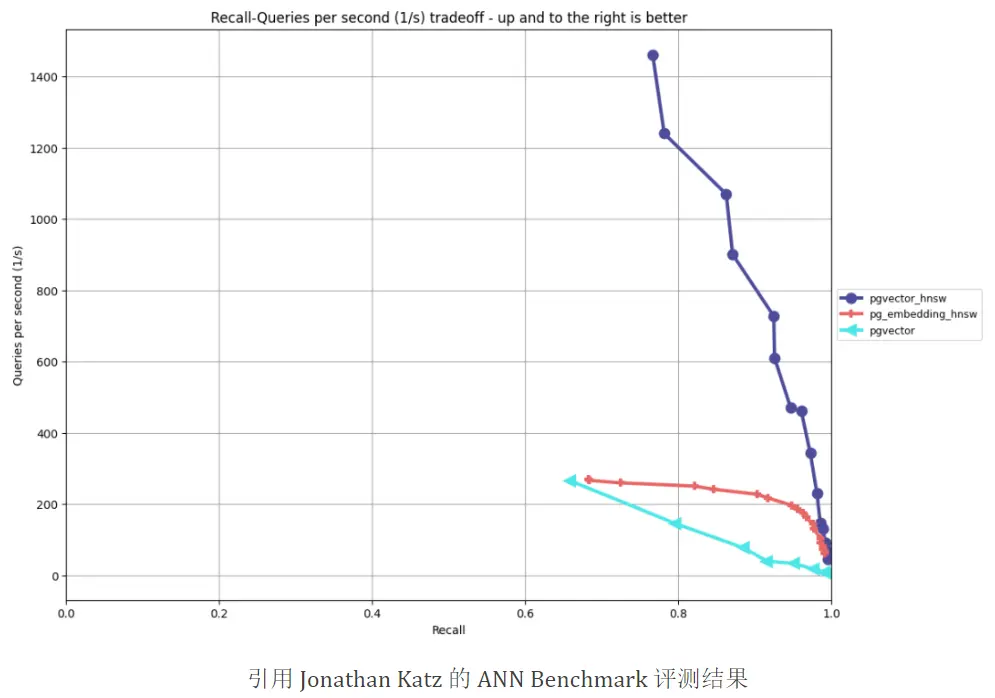
PGVector 的 HNSW 实现性能表现优异,根据 Jonathan Katz 的测试结果,显著优于 pg_embedding (基于磁盘的实现) 的表现。各种 PostgreSQL 的向量扩展分叉恐怕要面对巨大的生存竞争压力了。
与此同时,原有的 IVFFLAT 索引也有一系列改进:你现在可以并行创建 IVFFLAT 索引了。视并发程度可以加速几倍到十几倍不等。而距离度量函数的性能也进行了优化,例如 L2 距离计算在 ARM64 下有 36% 的性能提升。
PGVECTOR 的战略卡位
实现一个向量数据类型/索引功能只需要几千行代码,而实现 PostgreSQL 这样功能完备稳定可靠的数据库需要的是百万行级的代码,复杂度根本不可同日而语。一个合格的向量数据库 首先得是一个合格的数据库,而从零开始做到这一点并不容易。错误的路线将耗费百倍力气做无用功,PGVector 选择站在巨人的肩膀上,而不是造土法轮子重新发明一个数据库,这是明智而务实的做法。
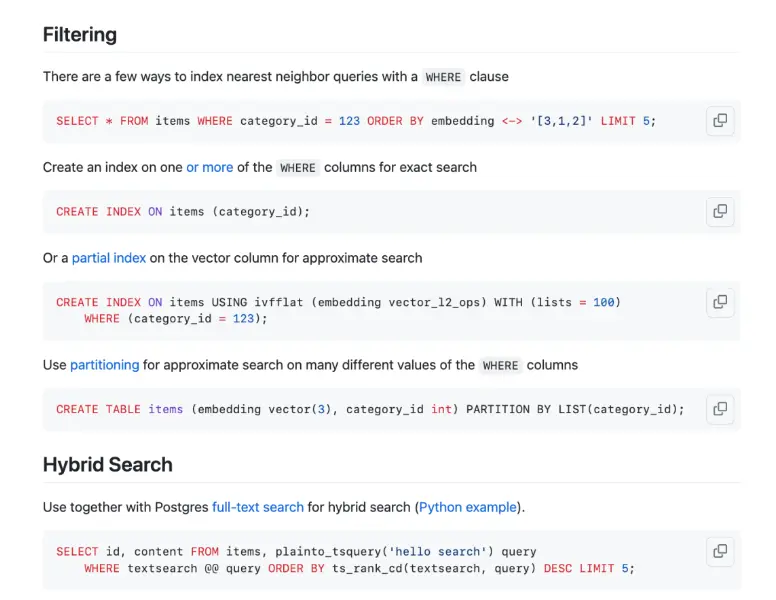
例如,你可以将向量功能与各种 PostgreSQL 提供的功能组合使用:使用表达式索引只索引一部分感兴趣的内容,实时查看索引创建进度,不阻塞读写请求在线创建/重建索引,使用多个进程并发创建索引。
当然,也可以将 Vector 模糊搜索 / 语义搜索 与 PostgreSQL 原有的全文检索/倒排索引功能组合使用,提供可解释性更佳的搜索结果。也可以继续使用标准 SQL 对元数据/各种字段进行精准的过滤,将精确搜索与模糊搜索相结合。并避免在多个专用数据组件中来回搬运数据的烦恼。

专用向量数据库本来唯一能拿的出手的亮点特色就是性能,然而 pgvector 的 HNSW 实现让这唯一的亮点都面临挑战,恐怕我们很快就会看见地理数据库、文档数据库、时序数据库、分布式数据库的历史再一次上演。
PostgreSQL 16 RC 1
PostgreSQL 16 的第一个候选发布版本 RC1 于9月1号释出!正式发布日期为 9月14日。
Pigsty 也许是最先提供 PostgreSQL 16 支持的发行版:从 16 beta1 就支持了。尽管目前仍然没有正式发布,但你已经可以拉起 PostgreSQL 16 的高可用集群。PostgreSQL 16 有一些比较实用的新功能:从库逻辑解码与逻辑复制,针对I/O的新统计视图,全连接的并行执行,更好的冻结性能,符合 SQL/JSON 标准的新函数集,以及在HBA认证中使用正则表达式。
Pigsty 特别关注 PostgreSQL 16 中的可观测性改进,新的 pg_stat_io 视图,让用户可以直接从数据库内访问到重要的 I/O 统计指标,对于性能优化,故障分析具有非常重要的意义。在以前,用户只能在数据库/BGWriter上看到有限的统计指标,想要更精细的统计数据,只能关联操作系统层面的I/O指标进行分析。现在,你可以从后端进程类型/关系类型/操作类型三个维度,对读/写/追加/回刷/Fsync/命中/逐出等行为进行深入的洞察。
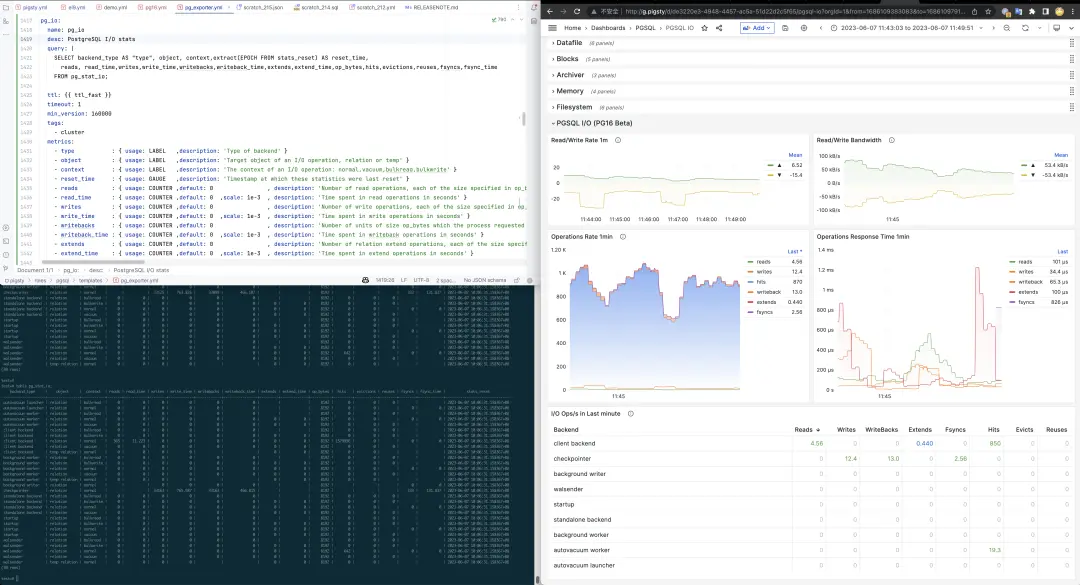
另外一个非常有价值的可观测性改进点是,pg_stat_all_tables 与 pg_stat_all_indexes 会记录最后一次顺序扫描 / 索引扫描的时间。尽管这个功能在 Pigsty 的监控系统中可以通过扫描统计图表实现,但官方提供直接的支持肯定更好:用户可以直观地得出一些结论:比如某一个索引是不是没用上可以考虑移除。此外,n_tup_newpage_upd 指标可以告诉我们表上有多少行在更新时不是在页内原地更新,而是移动到了一个新的页面上,这个指标对于优化 UPDATE 性能,调整表填充因子具有重要的参考价值。
在 Pigsty v2.3.1 中,EL 8 / EL 9 的离线软件包中已经默认收录了 PostgreSQL 16 RC1 的RPM包。并将在下个 Release 中立即跟进 PostgreSQL 16 的正式版本。
中文文档
从 v2.0 开始,Pigsty 的官方文档就一直只有英文。不过从这个版本开始,中文文档又回来了!多亏了 GPT-4 提供了高质量的中英互译。原有的英文文档,也新增了许多补充内容。
此外,原有 Github Pages 托管文档的地址是 https://vonng.github.io/pigsty/ ,现在则有了一个新的专用域名 https://doc.pigsty.cc 。针对墙内用户访问不便的问题,还提供了镜像的官方站点: https://pigsty.cc ,这里的中英双语文档都也都已经更新至 v2.3.1 最新版本。
另一个变化是,Pigsty的公开Demo https://demo.pigsty 现在也使用机构签发的正规 HTTPS 证书,而不是 Pigsty 自签名的证书了。
测试环境
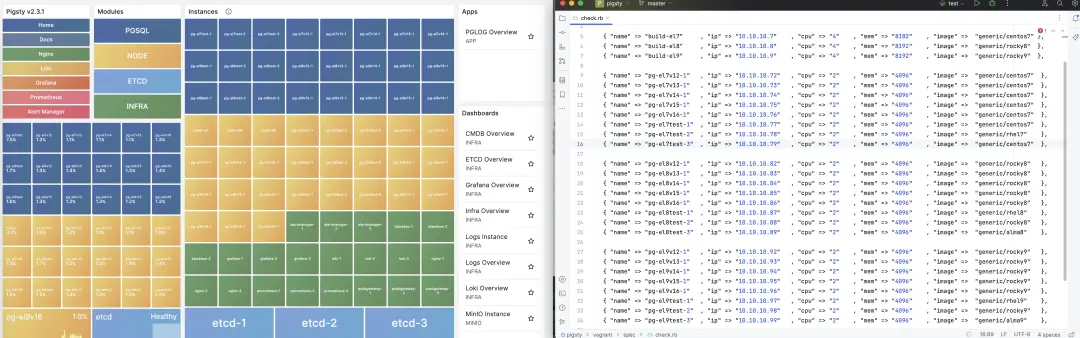
在以前,Pigsty 的测试一直是个头疼的问题:需要对五个受支持的PG数据库大版本(PG 12,13,14,15,16),三个操作系统的大版本(EL7,EL8,EL9),以及几种操作系统的兼容发行版变体(RHEL,CentOS,Alma,Rocky)之间的排列组合进行测试。
所以在 v2.3.1 中,提供了一个新的配置文件 check.yml ,一次性拉起 30 台不同操作系统、不同大版本、不同规格的数据库集群进行测试。这个配置文件(check.yml),也演示了不同大版本的安装方式,具有一定的参考价值。
问题修复
Pigsty v2.3.1 修复了 v2.3.0 中的两个问题。
第一个问题与 Watchdog 有关:当你希望在极端情况下避免脑裂,可以将 patroni_watchdog_mode 参数设置为 required ,在这种情况下,Patroni 的服务现在将自动执行 modprobe softdog 与 chown postgres watchdog 操作,确保 Patroni 拥有 watchdog 的使用权限。
第二个问题是关于从上游下载软件包的:当你下载的软件包中使用了通配符 '*' 时,现在会使用单引号扩起转义,避免受到目标目录中已有软件包的影响。
软件更新
此外,在离线软件包中,一些软件包也更新到了最新的版本。例如,Grafana 升级到了 v10.1 ,引入了一些有趣的新特性。Loki / Promtail 升级至 2.8.4 ,提供 MongoDB 兼容性的中间组件 FerretDB 升级到了 1.9,PG日志分析组件 pgbadger 升级至了 1.12.2,TimescaleDB 扩展升级至了 2.11.2。
Pigsty v2.3.1 的默认软件包中还添加了 SealOS,这是一个快速部署 Kubernetes 集群的精简二进制软件。Pigsty 会在后续版本中对 Kubernetes,以及 Kubernetes 中的数据库有进一步的支持。