昆仑万维宣布开源百亿级大语言模型「天工」Skywork-13B系列,并配套开源了600GB、150B Tokens的超大高质量开源中文数据集。昆仑万维「天工」Skywork-13B系列目前包括130亿参数的两大模型:Skywork-13B-Base模型、Skywork-13B-Math模型。
除模型开源外,Skywork-13B系列大模型还将开源600GB、150B Tokens的高质量中文语料数据集Skypile/Chinese-Web-Text-150B。公告称,这是目前最大的开源中文数据集之一。同时,昆仑万维「天工」Skywork-13B系列大模型即将全面开放商用;开发者无需申请,即可商用。
“此次Skywork-13B系列大模型将全面开放商用许可,用户在下载模型并同意并遵守《Skywork模型社区许可协议》后,无需再次申请授权即可将大模型进行商业用途。希望用户能够更便捷地探索Skywork-13B系列大模型技术能力,探索在不同场景下的商业化应用。”
Skywork-13B-Base模型
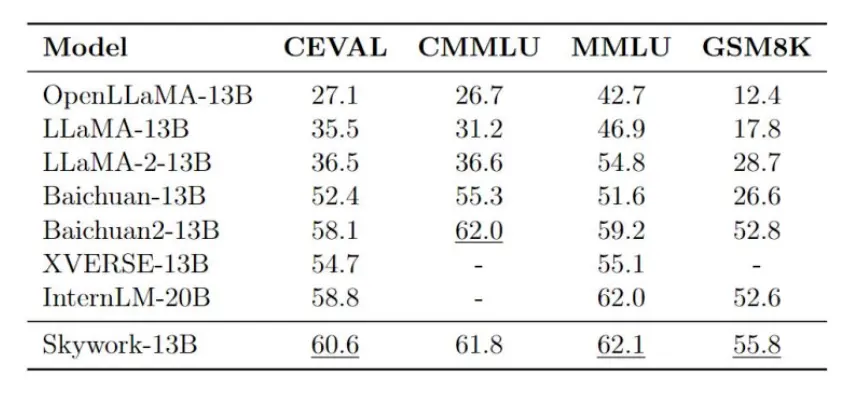
Skywork-13B-Base模型是Skywork-13B的基础模型,其经由3.2万亿个多语言高质量数据训练,在CEVAL、CMMLU、MMLUGSM8K等评测与基准测试上都展现了同等规模模型的最佳效果。
Skywork-13B-Math模型
Skywork-13B-Math模型经过专门的数学能力强化训练,在GSM8K等数据集上取得了同等规模模型的最佳效果。
Skypile/Chinese-Web-Text-150B数据集
该数据集是根据昆仑天工团队方面经过精心过滤的数据处理流程从中文网页中筛选出的高质量数据。本次开源的数据集大小约为600GB,总token数量约为150B,目前开源最大的中文数据集之一。
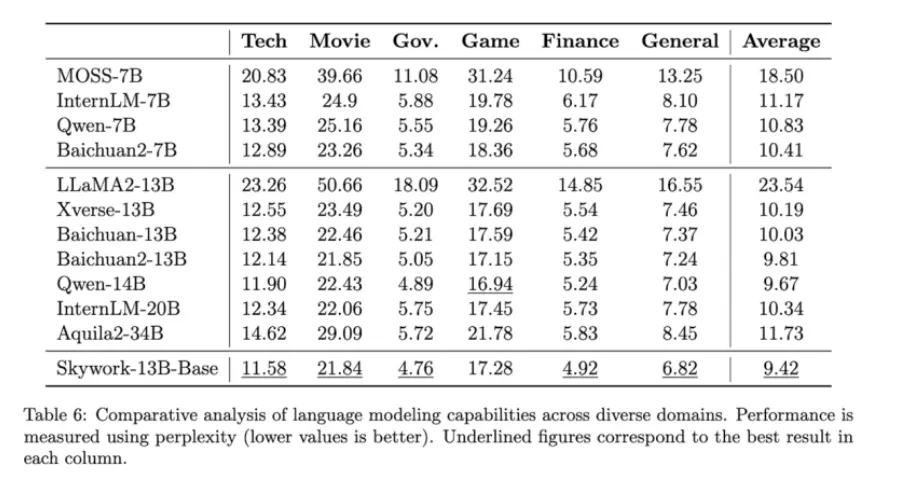
一些评测结果如下所示:
更多详情可查看官方公告。