清华大学研究团队发表的《LLM As DBA》论文介绍了用大模型管理数据库的技术。

论文地址:Arxiv
根据论文的内容,该团队开发了一款名为 D-Bot 的大语言模型工具,可以帮助对数据库进行管理。D-Bot 从文本来源中持续获取数据库维护经验,并为目标数据库提供合理、有根据的及时诊断和优化建议。
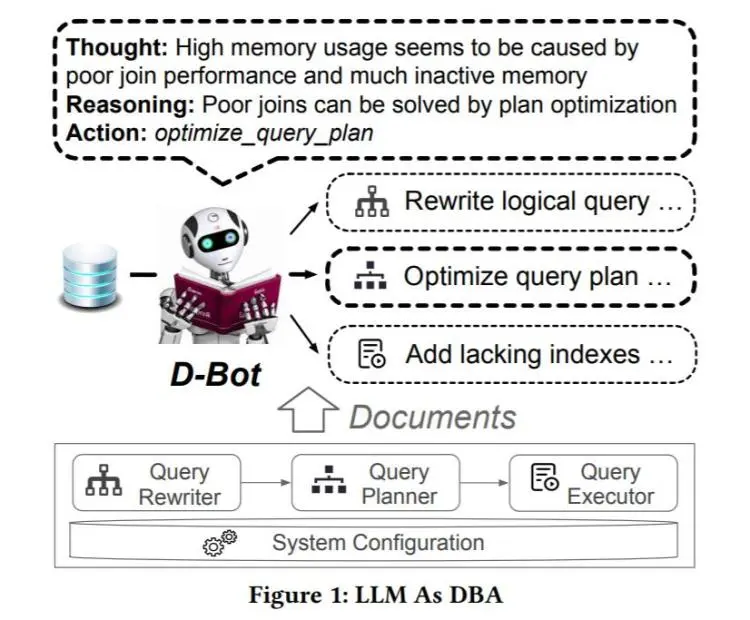
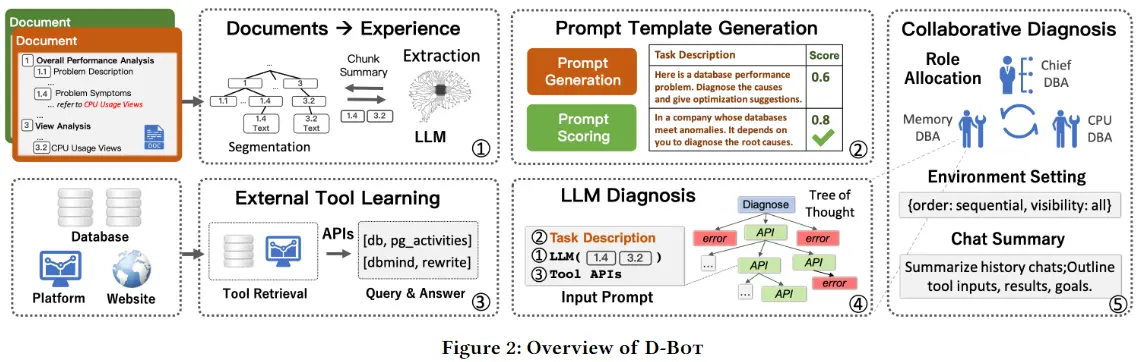
论文显示,该研究可以有效解决数据库管理员在管理大量数据库实例时的困难和繁琐问题。
清华大学研究团队发表的《LLM As DBA》论文介绍了用大模型管理数据库的技术。
论文地址:Arxiv
根据论文的内容,该团队开发了一款名为 D-Bot 的大语言模型工具,可以帮助对数据库进行管理。D-Bot 从文本来源中持续获取数据库维护经验,并为目标数据库提供合理、有根据的及时诊断和优化建议。
论文显示,该研究可以有效解决数据库管理员在管理大量数据库实例时的困难和繁琐问题。
6年,是一家专注于集成电路及AI的专业投资机构,起源于清华大学计算机系FIT楼实验室,由清华大学校友共同创办。卓源资本致力于打造中国最领先的泛集成电路及AI领域的投资机构,创始团队累计管理与投资规模超过30亿人民
巨大的机遇。此外,开源PHP继“Gitee”平台后,今年还将推出其自己的“Hugging Face”平台,届时JIANG或将成为第一批开源的中国本土的大模型之一。 本次发布会的主讲人为知未智能的联合创始人兼CTO段清华,毕业于北京大学计
于2019年的智谱AI,是国内最早一批研发大模型的企业,由清华大学知识工程实验室(KEG)技术成果转化。 智谱清言在线体验:https://chatglm.cn/ 百川智能(百川大模型) 8 月 31 日,前搜狗 CEO 王小川创立的百川智能宣布率先通
医药对话大模型ChatDD-FM 100B。水木分子成立于今年6月,由清华大学智能产业研究院(AIR)孵化,专注于生物医药垂直行业大模型的研发与应用。 根据介绍,水木分子提出的ChatDD,基于大模型能力,能够对多模态数据进行融合
彭博 (Bloomberg) 发布了一篇研究报告,详细介绍了新型的大规模生成式 AI 模型 BloombergGPT 的开发。这种大型语言模型(LLM)专门针对各种金融数据进行了训练,以支持金融行业内多样化的自然语言处理(NLP)任务。 公告称,基于
合作伙伴一同高速发展。 智谱 AI 成立于 2019 年,是由清华大学计算机系技术成果转化而来的公司,致力于打造新一代认知智能通用模型。公司合作研发了双语千亿级超大规模预训练模型 GLM-130B,并构建了高精度通用知识图谱
OSC 请你来轰趴啦!1028 苏州源创会,一起寻宝 AI 时代 澳大利亚国立大学、牛津大学和北京人工智能研究院的研究人员,合作开发了一种名为“3D-GPT”的新型人工智能系统,该系统可以简单地根据用户提供的基于文本的描述生成
,以及配套的多任务基准测试HuggingBench。 这两项资源的推出,将为开源资源的推荐、分类和溯源带来全新的解决方案。两项资源均已在Hugging Face社区开源,同时,为了确保资源的的可持续性和实验结果的可复现性,研究团队在G
复旦大学和阶跃星辰将要出一款端到端多模态 SVG 生成模型:OmniSVG,核心是支持从简单图标到复杂动漫角色的生成。 OmniSVG 主页:https://omnisvg.github.io/ 论文地址:https://arxiv.org/abs/2504.06263v1 OmniSVG 支持三种生成模式:
多元共进|2023 Google 开发者大会精彩演讲回顾 新加坡国立大学下一代搜索技术联合研究中心(NExT++)近日公布新计划——开发一款可以突破输入端多模态理解限制的大模型 NExT-GPT。 项目主页:https://next-gpt.github.io/ 论文地址
,斯坦福大学的最新研究警告我们,依赖这些由大型语言模型驱动的 AI 疗法聊天机器人,可能会给用户带来 “显著风险”。这项名为《表达污名与不当反应阻碍大型语言模型安全替代心理健康提供者》的研究,将在即将召开的
行动,操作系统公司、云服务商紧密合作,在极短时间内推出修复补丁并完成了大规模更新,把可能造成的损失降到了最低。 推动产业升级:开源打破了企业闭门造车的局限,促进了开放式创新。不同组织可以共享基础技
务及科技中介服务等。 根据官网介绍,智谱 AI 是由清华大学计算机系技术成果转化而来的公司,致力于打造新一代认知智能通用模型。公司合作研发了双语千亿级超大规模预训练模型 GLM-130B,并构建了高精度通用知识图谱
深言科技与清华大学 NLP 实验室共同研发的语鲸LingoWhale-8B模型已面向社会开源。 深言科技(DeepLang AI)由清华大学计算机系自然语言处理实验室(THUNLP)与北京智源人工智能研究院(BAAI)共同孵化,是国内最早开展大模型研发