视觉理解机V0.3.0是基于理解机框架的计算机视觉解决方案。
视觉理解机提供了面向图像的UDF和UDT,可以很方便的处理大规模的图像数据。视觉理解机本身是一个框架,具体的机器学习能力由理解机的PyTorch插件实现。
本次发布提供的PyPI包
ligavision==0.3.0liga-pytorch==0.3.0liga-tv==0.3.0
本次发布提供的七个可执行的Notebook
可以直接在Gitee预览这七个Notebook。 https://gitee.com/komprenilo/liga-pytorch
主要分为两类,由于Gitee无法渲染Google Colab的链接,这里直接给出链接:
- 图像分类(convnext为例):点我在Gitee预览 / 点我前往Google Colab执行
- 物体检测(ssd为例):点我在Gitee预览 / 点我前往Google Colab执行
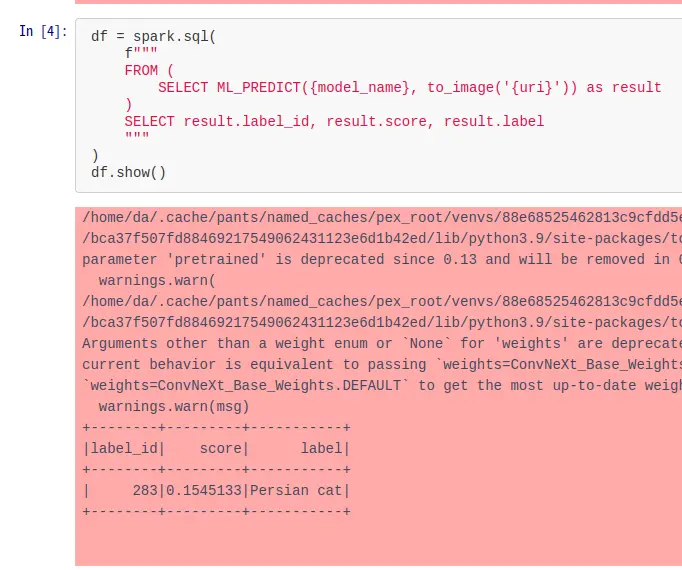
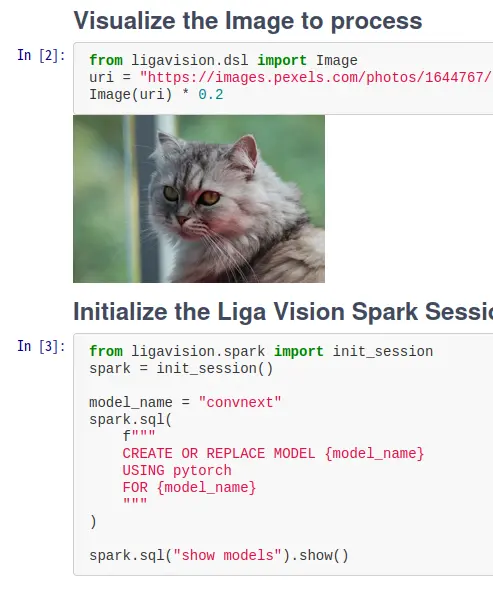
图像分类:使用SQL识别波斯猫
创建一个用于图像分类的模型
直接用SQL就可以知道该图像里面的猫是波斯猫