智元机器人宣布开源全球首个基于机器人动作序列驱动的具身世界模型EVAC (EnerVerse-AC),以及具身世界模型评测基准EWMBench。
根据介绍,EVAC 是一个能够动态复现机器人与环境复杂交互的世界模型,标志着从传统仿真到生成式模拟的跃迁。
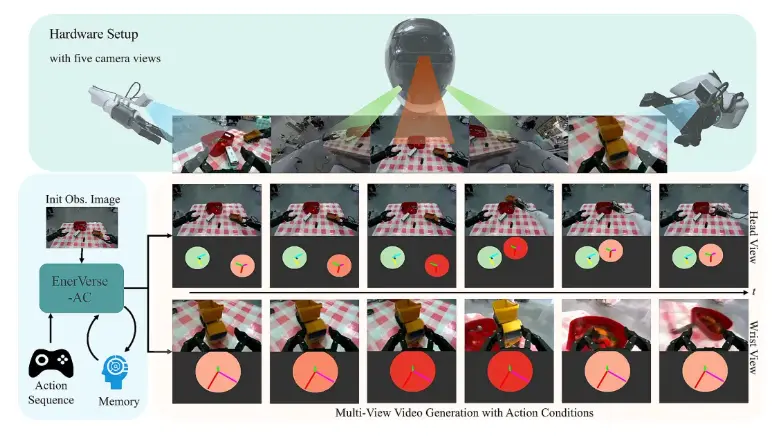
EVAC基于前序工作 EnerVerse 架构持续演进,创新型引入多级动作条件注入机制,实现 “物理动作 - 视觉动态” 的端到端生成,其核心能力体现在以下几个方面:
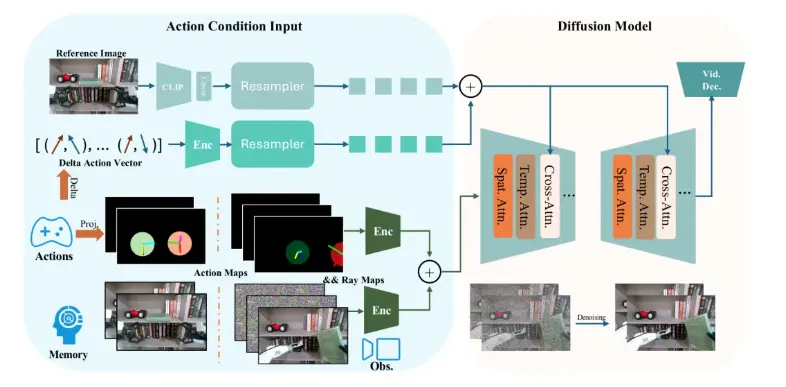
- 机器人动作与像素的高精度对齐:将机械臂 6D 位姿(x,y,z,roll,pitch,yaw)与末端执行器行程投影为action map,确保物理动作与图像帧的像素级对齐,精准建模 “抓取”、“放置”、“碰撞”、“推拉”、“快速抛掷”、“缓慢摇晃” 等复杂动力学行为;
- 动态多视图建模:引入Ray Map编码相机运动轨迹,支持头部 、腕部等多视角协同生成一致且连贯的视觉场景,赋予机器人更全面的环境生成能力。;
- 卓越的长时序一致性:采用 Chunk-Wise 自回归扩散架构与稀疏记忆机制(Sparse Memory),EVAC能够实现单视图稳定生成长达 30 个连续片段、多视图下亦可维持 10 个连续片段的无漂移稳定输出,保证了模拟过程在时间轴上的连贯性与真实性;
- 数据高效利用:融合 Agibot-World 数据集 + 失败轨迹(如抓取滑脱、路径碰撞)提升生成质量,该策略能有效抑制幻觉现象,使模型能更合理、更全面地建模机器人与环境的交互动态。
针对机器人操作场景的复杂性与特殊性,EWMBench构建了立体化的评估体系,从场景一致性、动作合理性 与 语义对齐与多样性 三大核心指标进行分析:
- 场景一致性Scene Consistency:评估生成场景中背景/物体/视角等稳固度与真实性,采用微调过的DINOv2特征进行量化。
- 动作合理性Motion Correctness:利用HSD (Symmetric Hausdorff Distance), nDTW (normalized Dynamic Time Warping) 和 Dynamics Score 三重互补指标协同精确评估生成动作的合理性与动力学真实度。
- 语义对齐与多样性Semantic Alignment & Diversity:结合MLLM(多模态大模型)和CLIP从全局指令对齐度、关键步骤语义准确性、逻辑合理性等多个层次对生成视频进行语义理解评估。
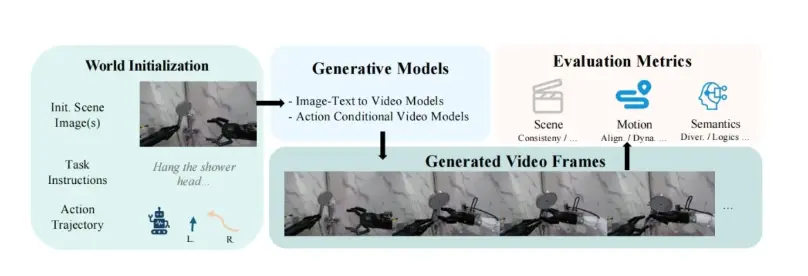
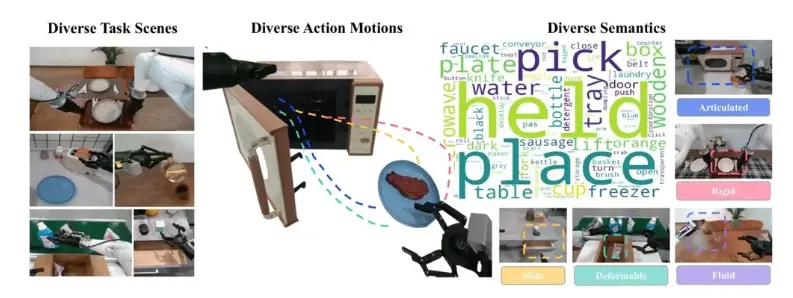
相较于当前主流视频生成评测基准 VBench,EWMBench 在评测结果与人类主观判断的一致性方面表现更优,能够更真实、细致地反映具身世界模型在交互理解、动作还原与视觉一致性等核心维度的实际能力。