Pika 发布了一款突破性的音频驱动视频生成模型(Audio-Driven Performance Model),能近乎实时地生成具有逼真表情和完美唇形同步的视频,速度提升 20 倍且成本大幅降低。
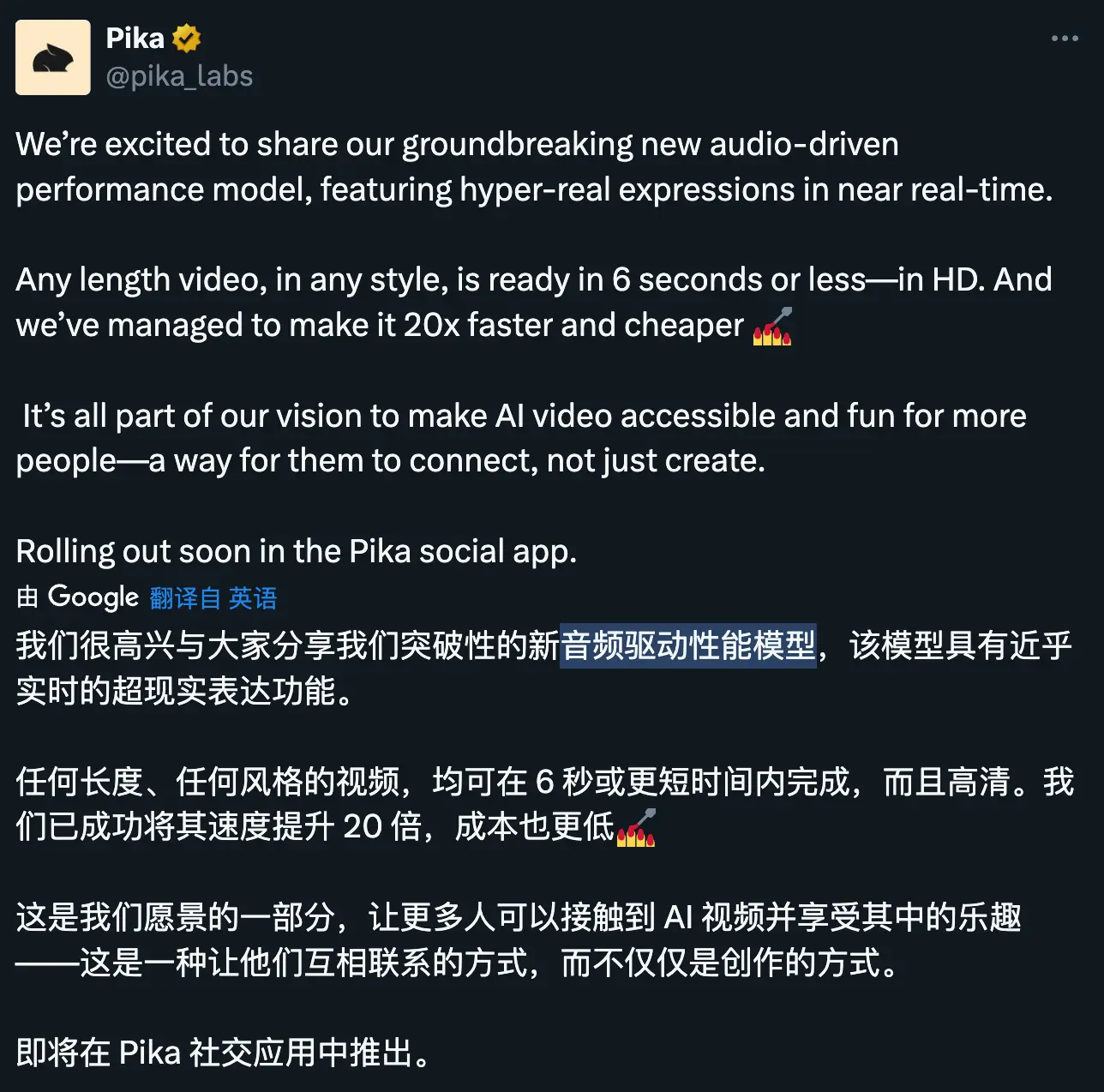
据介绍,该模型支持任意长度和风格的视频制作,并能在 6 秒或更短的时间内完成高清视频的生成。新模型在速度上提升了 20 倍,同时成本也大幅降低。

Pika 以生成逼真视频的 AI 技术而知名。而据公开信息,郭文景是 Pika Labs 的联合创始人与 CEO。她与联合创始人兼 CTO Chenlin Meng 均为斯坦福大学 AI Lab 博士生,在 2023 年 4 月从斯坦福辍学、创立了 Pika Labs,致力于开发基于文本生成短视频的 AI 工具。
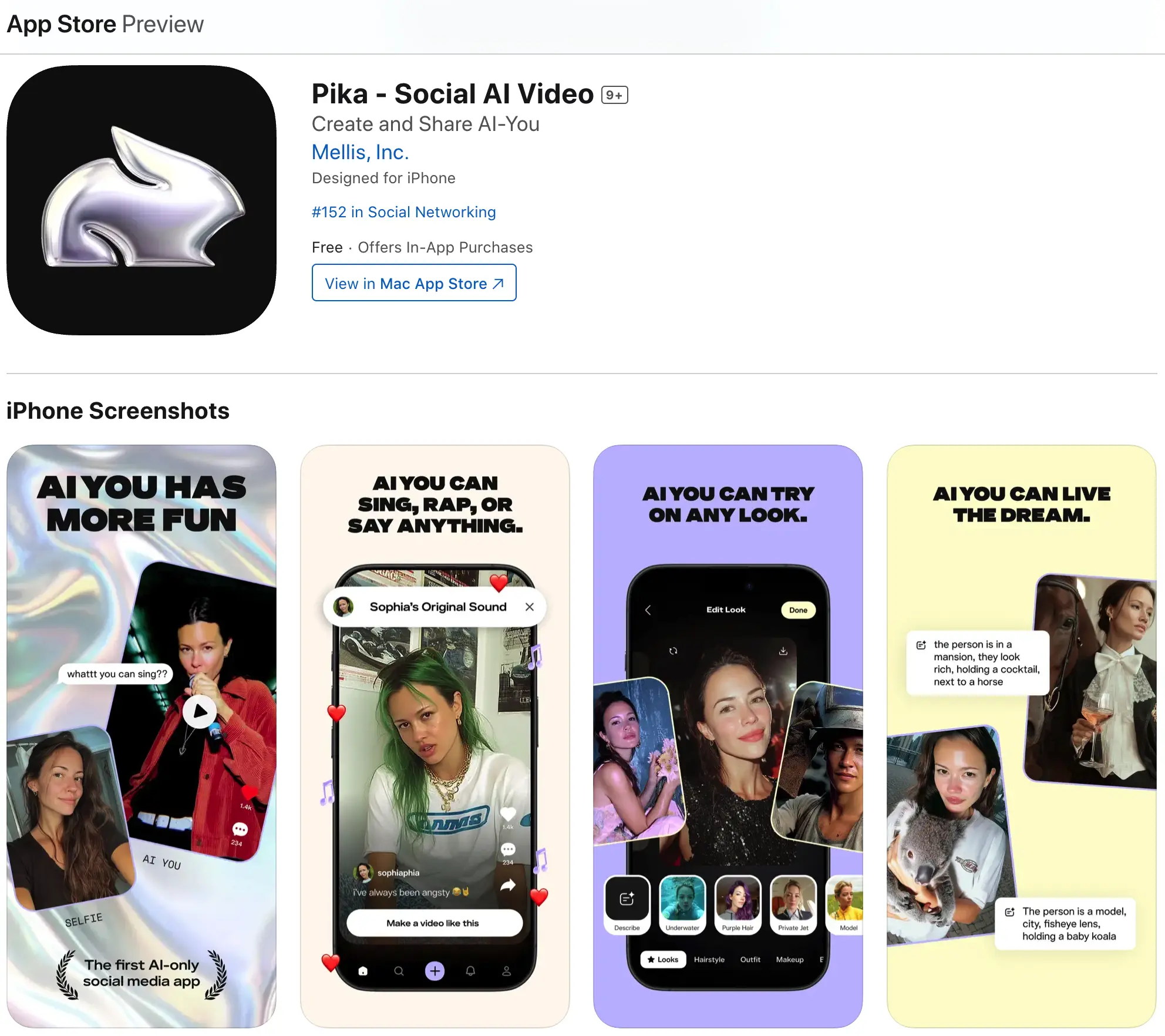
Pika 的核心产品为「文生视频」模型,号称用户一句话描述,就能生成风格多样的动画短视频。