OpenPipe发布了开源框架AutoRL,旨在简化使用强化学习(RL)为任何特定任务专门化训练开源模型(如Qwen)的过程。
AutoRL的训练流程是,用户首先用一句话定义任务,随后AutoRL会自动生成30个示例场景。Agent使用GRPO算法在25个训练样本上进行训练,最后在剩余的5个测试样本上与SOTA模型(如Sonnet 4)进行性能对比测试。
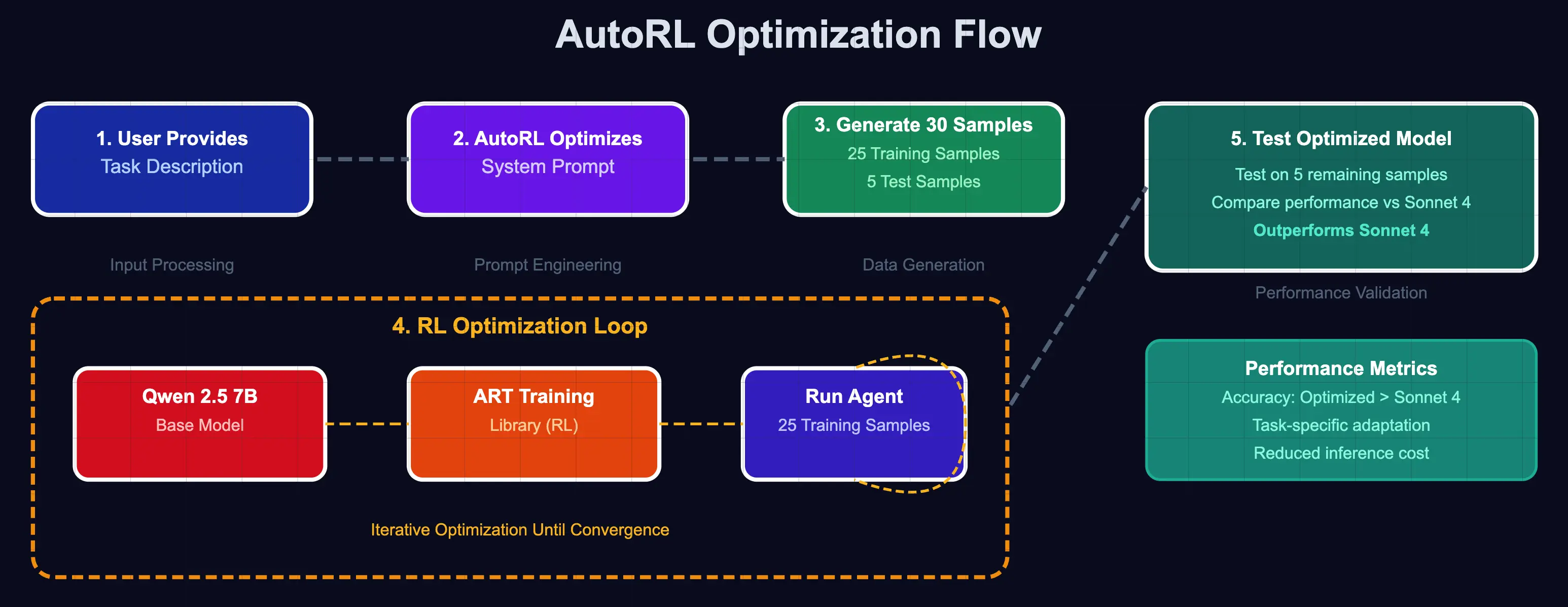
该框架构建于OpenPipe的ART(Agentic Reasoning & Tool-use)之上,并使用RULER作为其奖励函数。
点此查看更多介绍。