

过去数月,MetaGPT [1] 的智能体(Agents)软件公司实例让人印象深刻,它迅速在 GitHub 获得了30k star,也获得了数十个全球专业媒体与大V报道。但智能体软件公司只是智能体社会(Agent Society)的一个缩影。智能体社会或许会有软件公司、电商公司、游戏公司,也会拥有大量的独立智能体提供生产力。现代人工智能之父 Jürgen Schmidhuber 也非常认可智能体社会的理念,他与其团队对MetaGPT做出了显著贡献,列入了 MetaGPT 作者名单。
早在1986年,马文·明斯基以《心智社会》(Society of Mind, SOM)[2] 之作引领了人工智能领域的一场思想革命。他提出了一个极具创见的理论:心智不需由具有智能的单独部件构成,反而是由一系列简单部件的相互作用集结而成的复杂系统,正是这种集结,催生了我们所认识的智能和意识。这一理念对于构建自主智能体以及其后续发展,产生了不可估量的深远影响。
随着人工智能技术至2023年的飞跃,我们现在可以设想,如果每个微小部件本身都拥有一定程度的智能,它们将如何相互作用,产生何种层次的集体智能。2023年上半年关于自然语言心智社会(NLSOM, Language Agent Society)的研究论文 [3] 中,来自阿卜杜拉国王科技大学、瑞士人工智能实验室、牛津大学以及苏黎世联邦理工学院等知名研究机构的科学家们共同探讨了智能体社群的可能性。
他们提出,构建成由语言驱动的智能体社区,能够协同完成单一智能体无法或难以独立完成的任务。研究中提出了一系列实验构想,这些实验构想不仅仅是概念验证,它们被视作迈向一个包含万亿级智能体社会的先导,这个社会可能也会包括人类成员。


在2023年的 CogX Festival 上,Jürgen 向听众展示了他对于大型语言模型(LLMs)的深刻见解。他在讨论智能体(Agents)相关的话题时,提到了构建自我改进系统的多种途径,包括通用图灵机(Universal Turing Machine)[4] 和哥德尔机(Gödel machines)[5]。他指出,目前的大语言模型为我们提供了一种全新的思维模式 — 通过使用通用符号语言(例如:自然语言或编程代码)作为接口,来串联不同的模型。这些模型能够与其他语言模型进行交流,共同构建起一个自然语言心智社会(NLSOM)的范例。


Jürgen Schmidhuber 教授是瑞士人工智能实验室 (IDSIA) 的科学主任,以及阿卜杜拉国王科技大学人工智能中心 (AI Initiative, KAUST) 的主任。他的工作对强化学习(Reinforcement Learning),元学习(Meta Learning),以及神经网络(Neural Network)等重要人工智能方向有着深刻的影响。
截止目前,Schmidhuber 教授的谷歌学术引用为21万,其中作为共同发明人的长短时记忆(LSTM)论文单篇引用过9万。他在15岁就希望能开发一种比它聪明并且能够自我完善的人工智能,然后他就可以退休了。DeepMind 创始初期四人中的两人以及他们招募的第一个人工智能博士都来自 Jürgen Schmidhuber 的实验室。
在 Jürgen 构想的这一社会中,所有的交流都是透明且易于解释的。他提到了一个被称作“Mindstorm”的概念,即当给定一个问题时,这个自然语言心智社会能够协同合作进行解答。
在这个过程中,社会中的每个成员可能会有不同的想法和视角,它们将收集并整合这些不同的思路,从而做出集体决策。
这种方式特别适合于解决那些单个智能体无法有效解决的问题。Jürgen 进一步举例说明,这种问题可以是编程性质的,如使用 Python 语言解决一个具体的编程难题。通过这种协同作用,智能体社会的智能集结,将能够实现超越个体能力的解决方案。
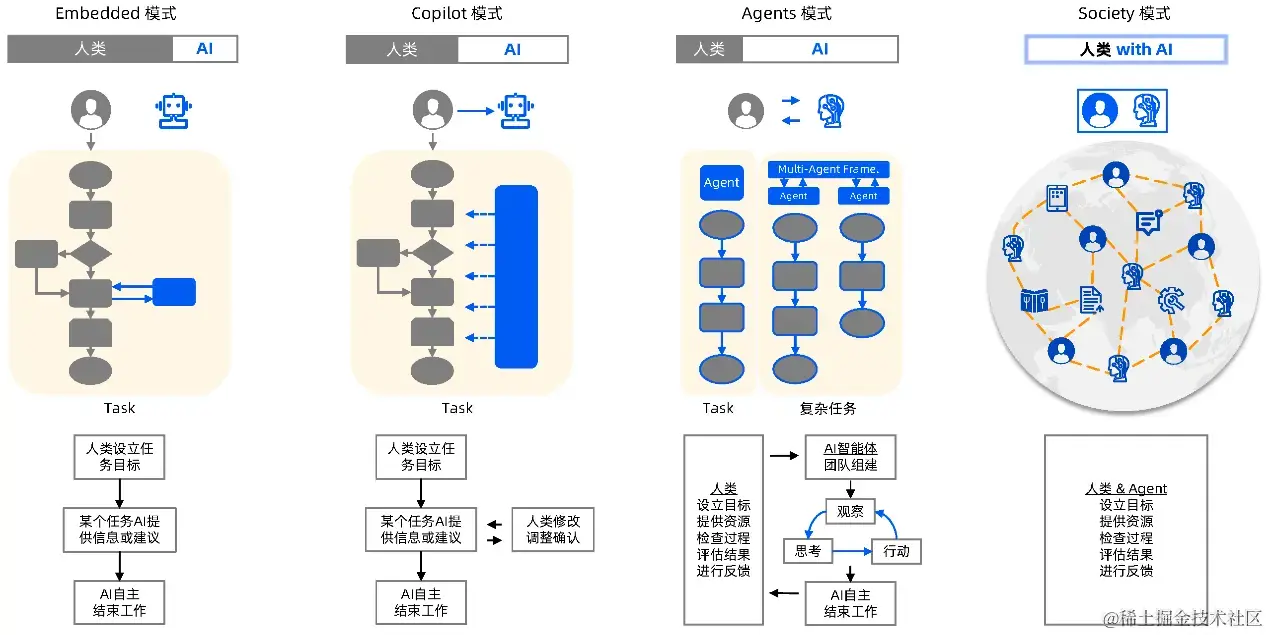
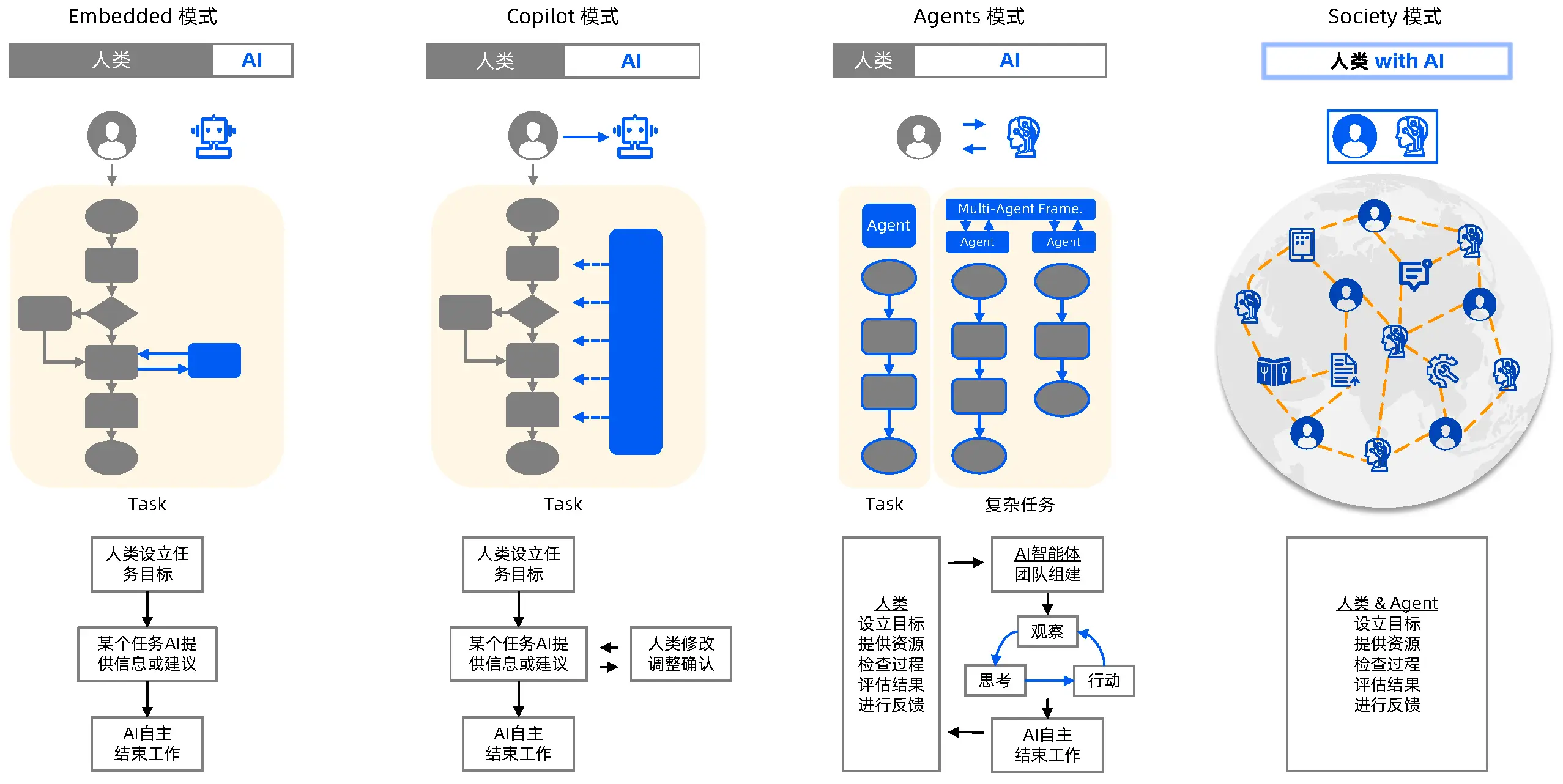
此次 MetaGPT 项目的迭代获得了 Jürgen 直接指导,其团队也在代码、写作、工程上做了大量支持。
接下来,本文将详细解析MetaGPT论文的更新内容,以便让读者能够更加深入地理解其细节。
1、论文与框架更新
论文 3.1 节更新:阐述了MetaGPT框架中的角色专业化设计和角色分工概念,说明了单个智能体在MetaGPT中的行为模式和SOPs下的组织方式。
论文 3.2 节更新:介绍MetaGPT框架中的通信机制,包括结构化通信接口设计和发布-订阅机制。
论文 3.3 节更新:引入了可执行反馈机制,它是一种在代码执行过程中进行持续迭代和自我纠正的机制。
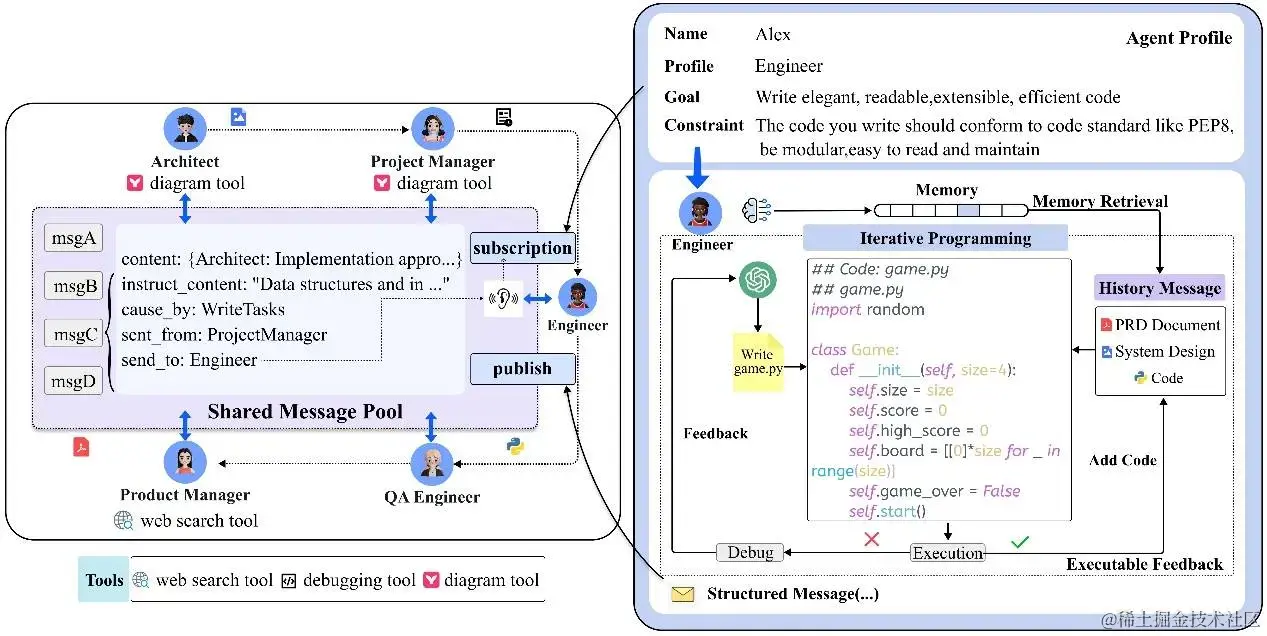
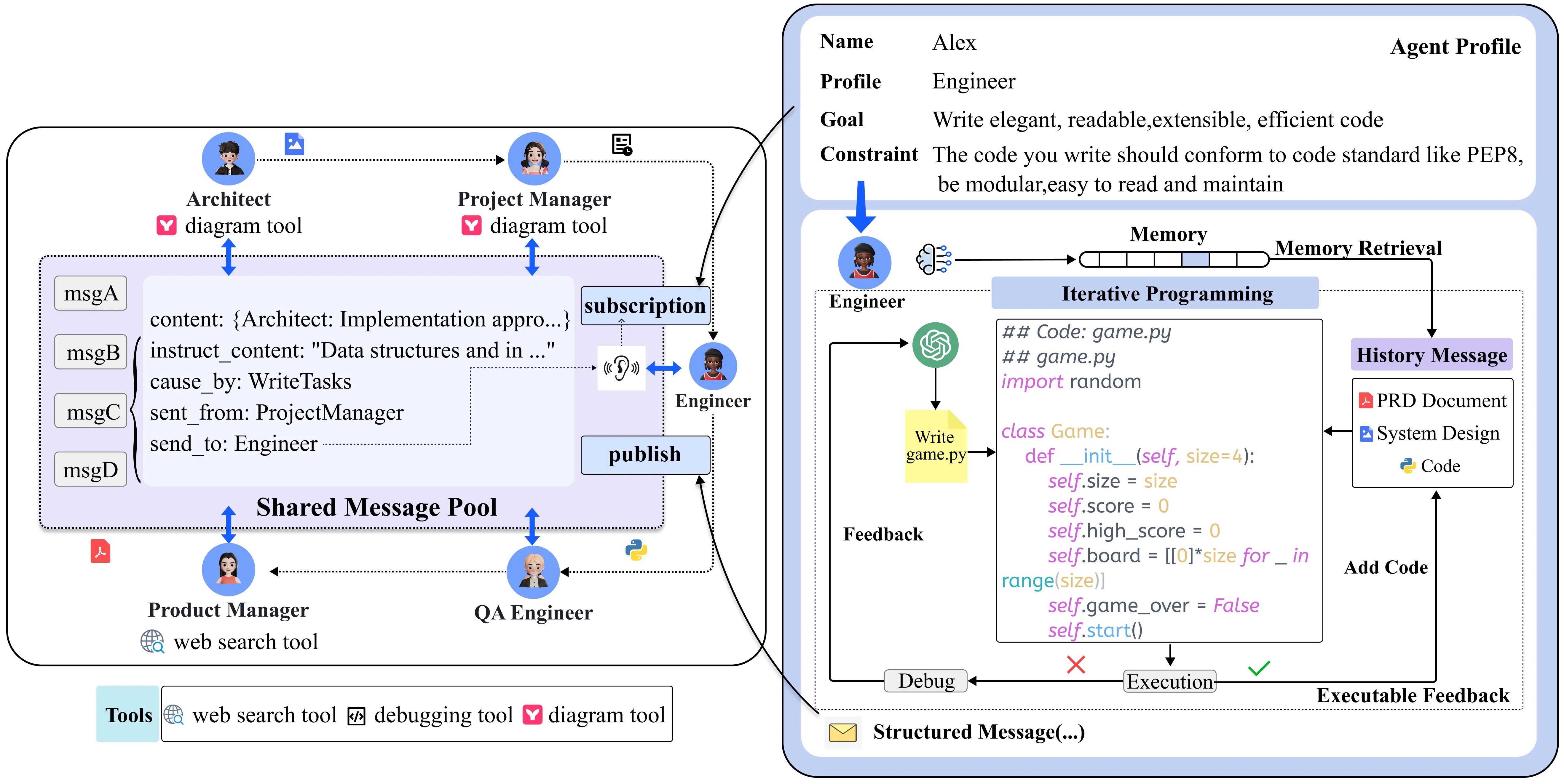
Fig.2. 通信协议示例(左)和运行中可执行反馈的迭代编程示例(右)。左图:Agents使用共享消息池发布结构化消息。它们还可以根据自己的配置订阅相关消息。右图:生成初始代码后,工程师Agent可执行代码并检查运行中是否报错。如果出现报错,Agent会检查执行结果,并将它们与 PRD、系统设计和代码文件进行比较,进行代码的重写和优化。
1.1、智能体通信协议
目前大部分多智能体都是通过以自然语言为主的对话形式来完成协作,但这对于解决具体特定任务而言并不是最优的方式。
没有约束和特定要求的自然语言输出,可能会导致信息内容的失真或者语义焦点的偏移。
因此,结构化的通信内容和接口形式有助于智能体之间进行快速准确的任务要求理解,也有利于信息内容的最大化保留。参考人类 SOPs 中对不同岗位的角色要求,我们给每个角色设定了符合人类对应岗位专家的输出规范,要求智能体将原始自然语言信息转换为更结构化的表达(如下图所示),如数据结构、API设计和时序图。
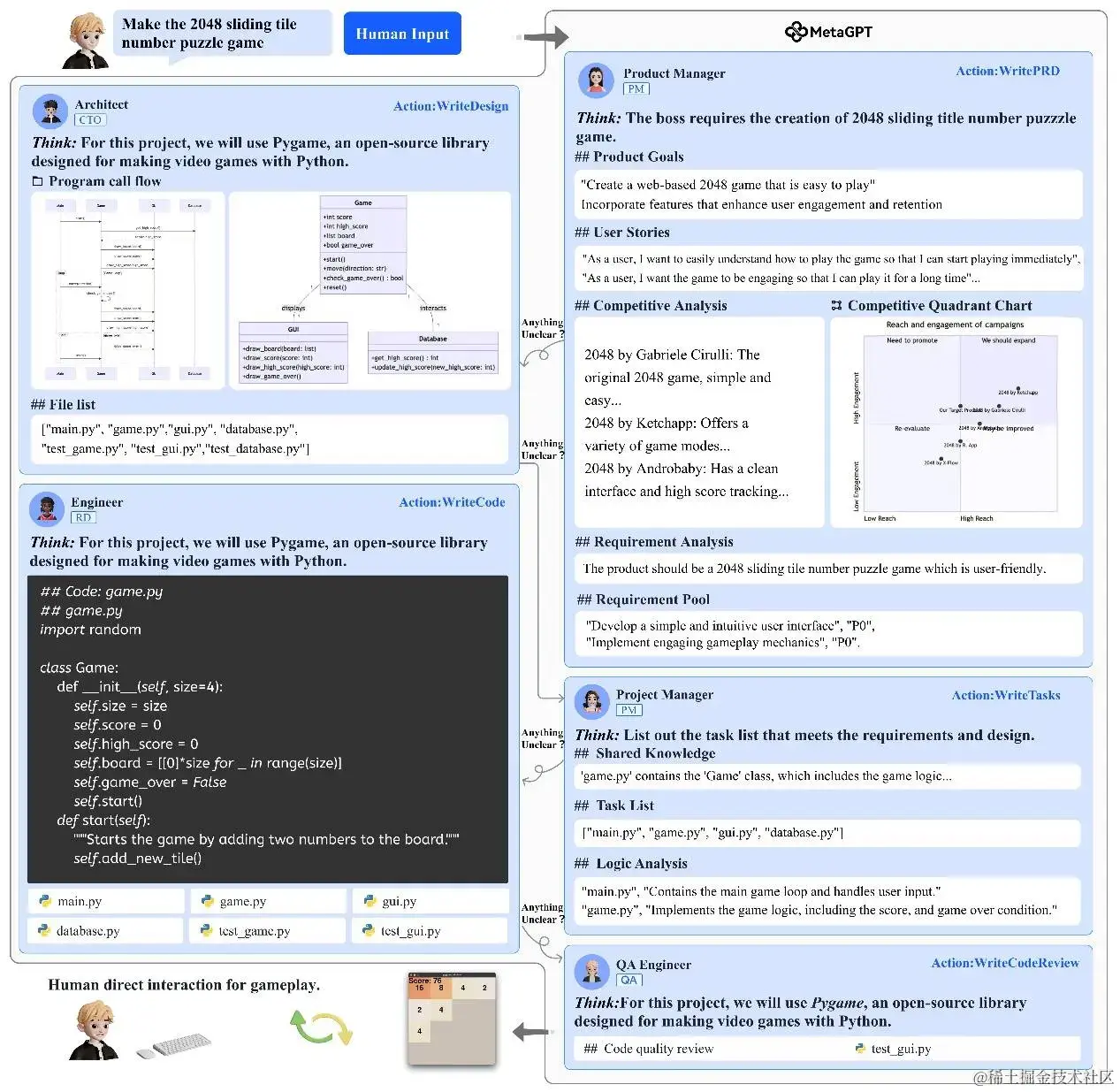
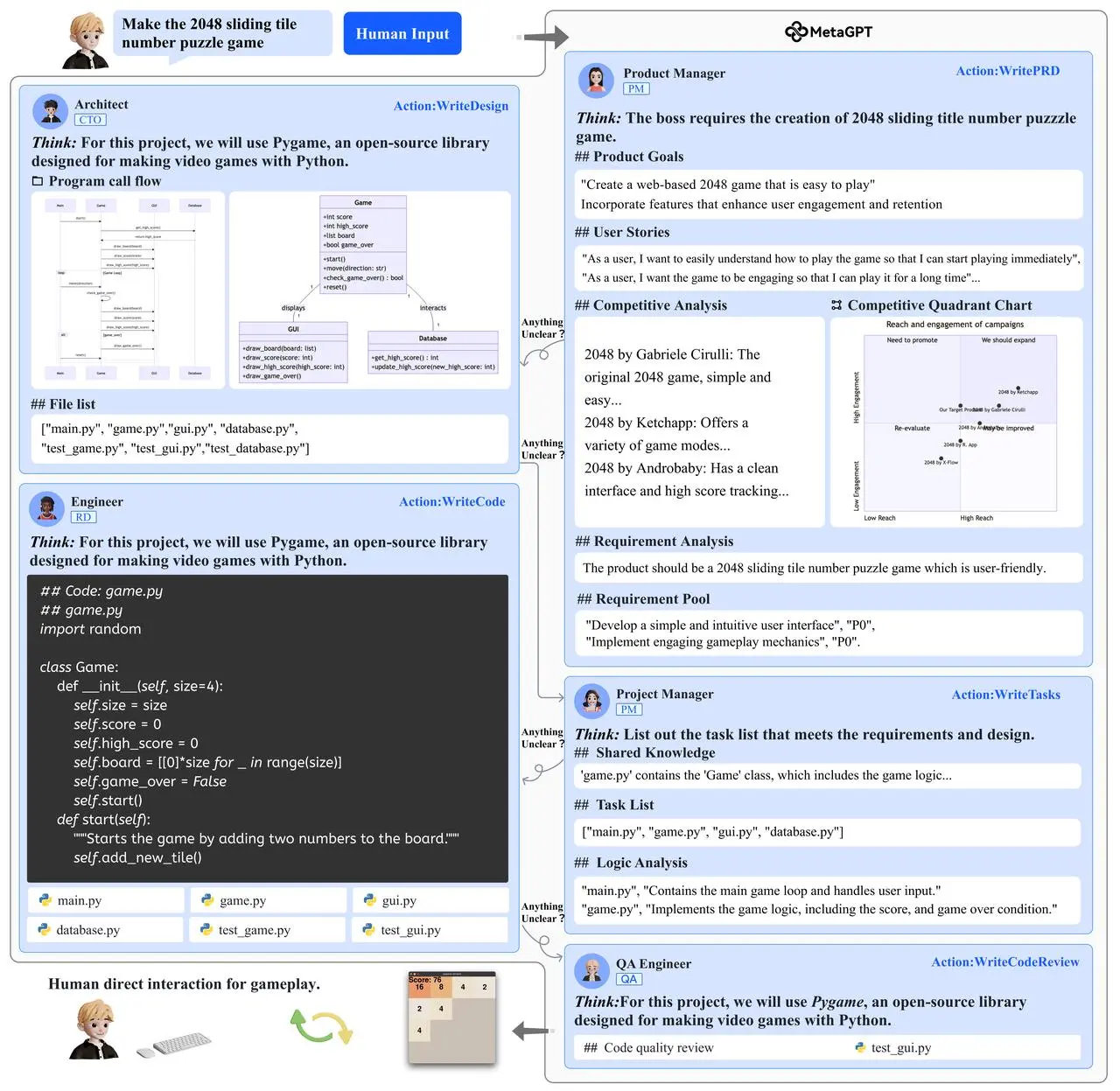
Fig.3 MetaGPT 软件开发流程示意图,表明结构化的 SOPs 可以带来较好的效果 。更详细的演示见附录 B
在后续的实验中,我们对比了 MetaGPT 和 ChatDev(使用聊天形式的沟通协作机制)来进行软件开发的这一复杂任务的实际解决效果,结果说明结构化的通信接口设计对于智能体协作能带来显著效果。
发布-订阅机制
在多智能体的通信过程中,仅仅依赖1v1的单点通信方式不仅会加剧通信拓扑的复杂度,导致协作的效率低下,也会急剧增加开发成本。因此,我们通过【发布-订阅】的消息机制,在框架内实现了共享消息池和基于兴趣的订阅方式。
具体来说,环境提供共享的消息池,智能体可以从中直接获取信息,无需逐一询问其他智能体。与此同时,智能体可根据自己兴趣/关注的行为来进行消息的过滤和筛选,从而减少消息/记忆的过载。如图3所示,架构师主要关注产品经理的 PRD文档输出,而对测试工程师的文档则关注较少。


1.2、可执行迭代反馈设计
调试和执行反馈在日常编程任务中发挥着重要作用。然而,现有方法往往缺乏自我纠正机制,仅通过代码审查和评审机制进行代码可行性评估。为了进一步减少 LLM 在生成代码上的幻觉问题,我们引入了可执行反馈机制,对代码进行迭代改进。通过自动的代码执行测试结果反馈,进行代码可行性评估和判断,促进 LLM 进行自我的迭代和优化。如图2所示,工程师可根据代码执行结果持续更新代码,迭代测试,直到测试通过或者最大N次重试退出。
2、实验更新
在实验部分,我们增加了对 SOPs 引入多智能体框架效果的探索实验,和可执行迭代反馈带来的代码质量的提升实验。在数据集上:
- 针对代码质量的效果评估:我们使用了两个公共基准数据集:HumanEval 和 MBPP。
1)HumanEval 包括 164 个手写编程任务。这些任务包括功能说明、描述、参考代码和测试。
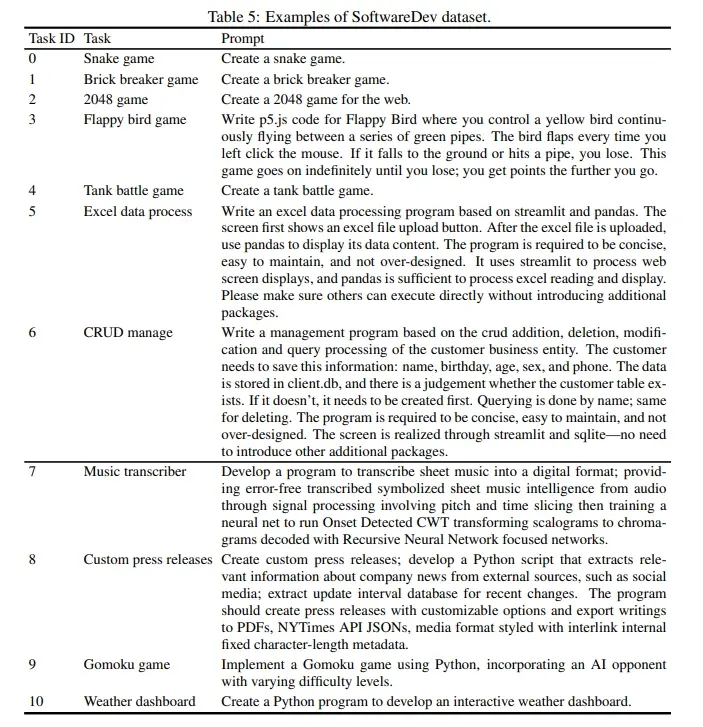
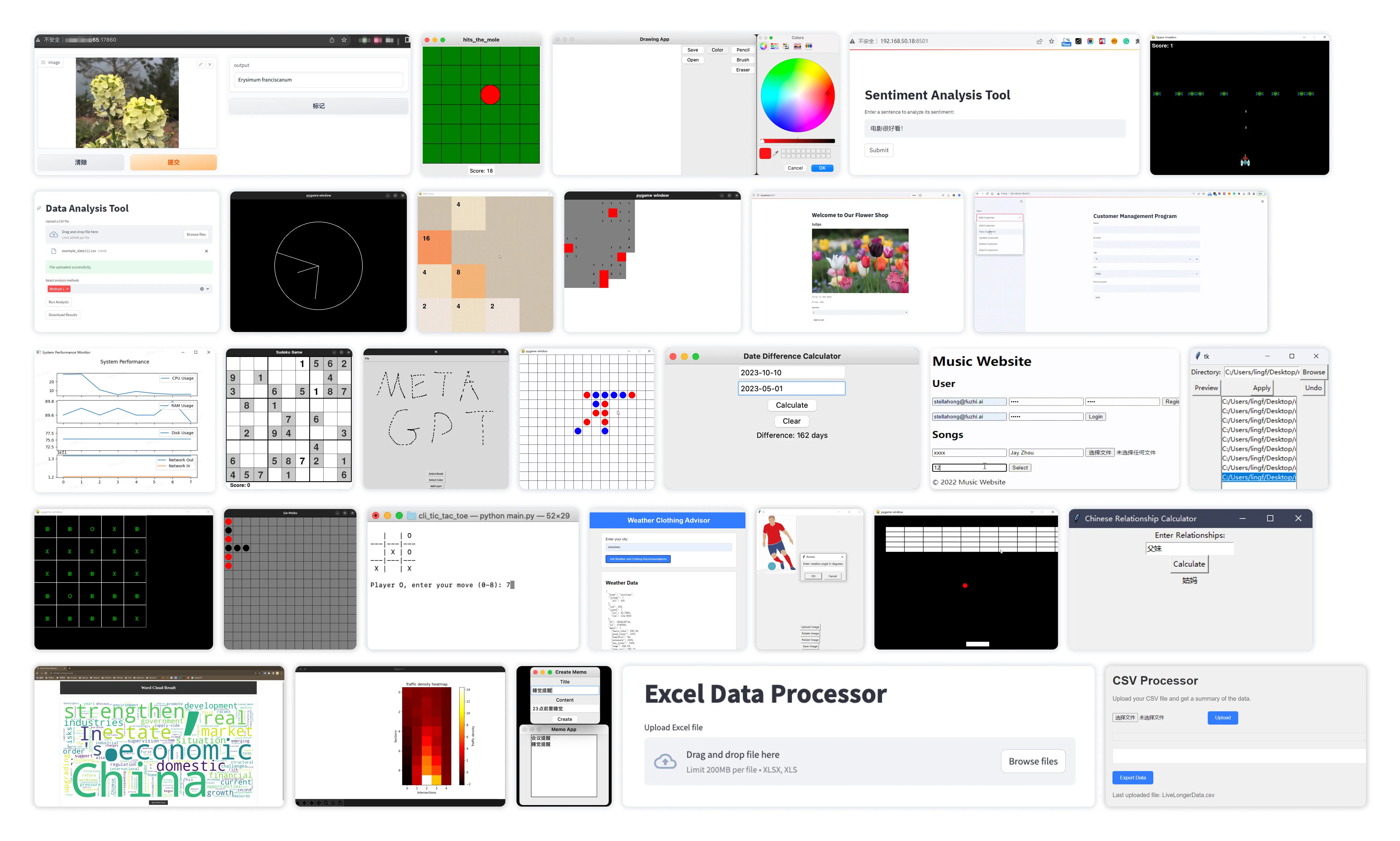
2)MBPP 包含 427 个 Python 任务。这些任务涵盖核心概念和标准库功能,并包括说明、参考代码和自动测试。 - 我们提出了更具有挑战性的软件开发任务的基准数据集 SoftwareDev:我们的 SoftwareDev 数据集收集了 70 个具有代表性的软件开发任务实例,每个实例都有自己的任务提示(见论文表 5)。这些任务的范围多种多样(见论文图 5),如迷你游戏、图像处理算法、数据可视化等。它们为真实的开发任务提供了一个强大的测试平台。与之前的数据集不同,SoftwareDev 侧重于工程方面。在比较中,我们随机选择了七个具有代表性的任务进行评估。

2.1、可执行迭代反馈设计
图 4 表明,MetaGPT 在 HumanEval 和 MBPP 基准测试中均优于之前的所有方法。当 MetaGPT(使用 GPT-4 作为基础模型),与 GPT-4 相比,它在 HumanEval 基准测试中的 Pass @1 显著提高。它在这两个公共基准测试中达到了 85.9% 和 87.7%(考虑到实验成本,部分模型的数值结果直接使用的 Dong et al. (2023). 所提供的结果 [6])。
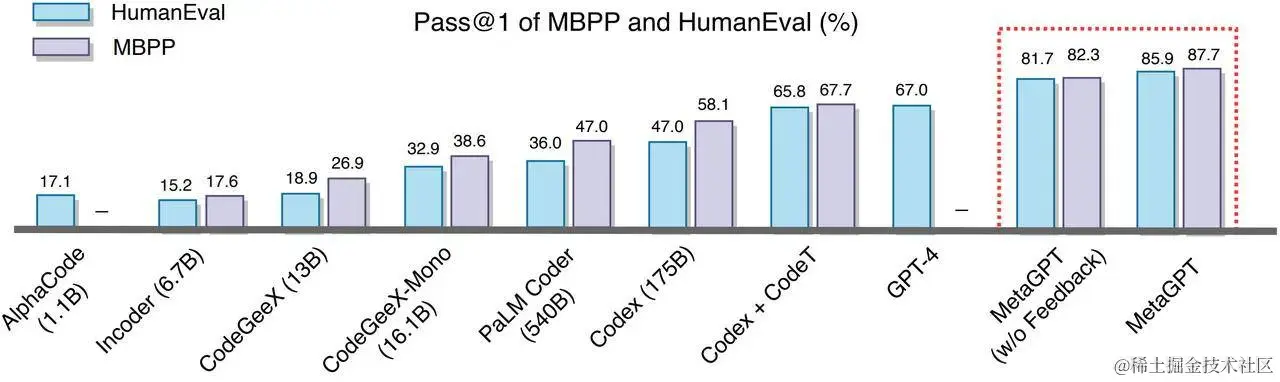
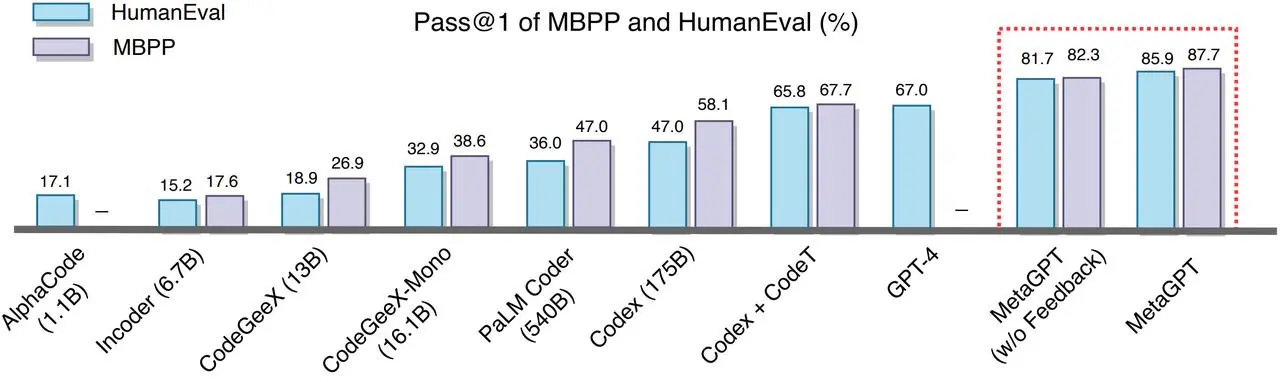
Figure 4: Pass rates on the MBPP and HumanEval with a single attempt.
2.2、软件开发任务数据集 & 评价指标
对于 SoftwareDev,我们优先考虑生成项目的实际可用性,并通过人工评估(A、E)或统计分析(B、C、D)来评估性能,我们通过可视化示例展示了 MetaGPT 的自主软件生成能力(论文图 5)。有关其他实验和分析,可参阅论文附录 C:
(A)可执行性:该指标将生成代码从 1(失败/无功能)到 4(无缺陷)进行评级。1代表无功能,2代表可运行但不完美,3代表接近完美,4代表无缺陷。
(B)成本:这里的成本评估包括(1)项目运行时间(2)Token 消耗量和(3)实际费用。
(C)代码统计信息:包括(1)代码文件数量(2)每个文件的平均代码行数 以及(3)总代码行数。
(D)生产效率:基本定义为 Token 使用量除以代码行数,即每行代码消耗的 Token,该数值越小说明代码生产效率越高。
(E)人工修订成本:以确保代码顺利运行所需的修订轮数来量化,这表示人工干预的频率,如调试或导入依赖等修订。

2.3、SOPs vs ChatChain
在解决特定任务的场景中,为了探索 SOPs 对多智能体协作的效果,我们选择了开源工作中支持软件开发任务的智能体框架 ChatDev 作为实验比较对象。ChatDev 是基于 ChatChain 和软件开发瀑布流的角色分工进行智能体组织和协作的框架。我们从 SoftwareDev 选择了7个任务进行对比,并比较了上述的相关指标来说明差异。
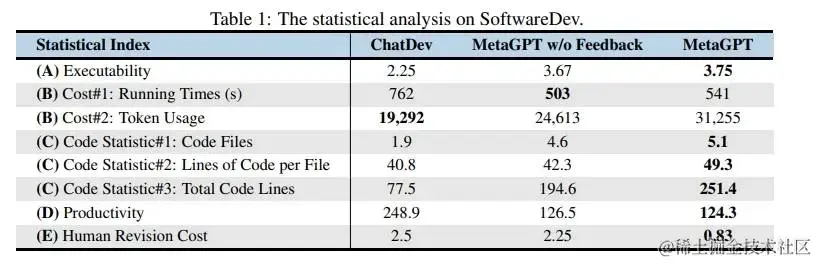
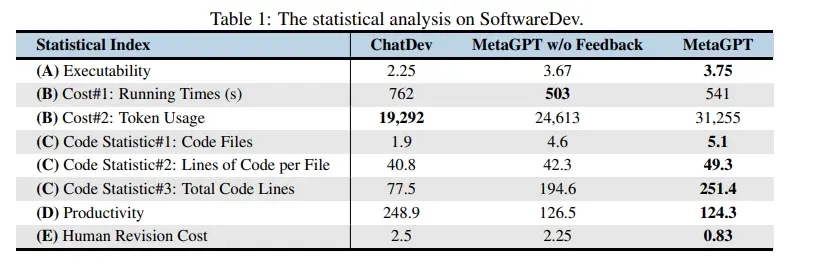
如论文表 1 所示,在具有挑战性的 SoftwareDev 数据集上,MetaGPT 几乎在所有指标上都优于 ChatDev。
例如:在可执行性方面,MetaGPT 得到了 3.75 分,非常接近 4 分(完美无缺)。此外,它花费的时间(503 秒)也明显少于 ChatDev。
在代码统计和人工修改的成本上也明显优于 ChatDev。虽然 MetaGPT 需要更多的 Token(24,613 或 31,255,而 ChatDev 为 19,292 ),但它只需要 126.5/124.3 个 Tokens 就能生成一行代码。相比之下,ChatDev 使用了 248.9 个 Tokens。
这些结果凸显了 SOPs 在多智能体协作中的优势。
3、致谢
感谢来自 KAUST AI 中心的执行秘书 Sarah Salhi,博士后王宇辉,以及博士生王文一对于此论文提供的建议以及帮助。
[1] arxiv.org/pdf/2308.00…
[2] en.wikipedia.org/wiki/Societ…
[3] arxiv.org/pdf/2305.17…
[4] en.wikipedia.org/wiki/Univer…
[5] en.wikipedia.org/wiki/Gödel_…
[6] arxiv.org/abs/2304.07…