谷歌Gemini模型的原生文本转语音(TTS)功能已适用于规模化的生产环境,该功能目前支持Gemini 2.5 Flash和Gemini 2.5 Pro两个模型。
https://x.com/OfficialLoganK/status/1947328086577492309
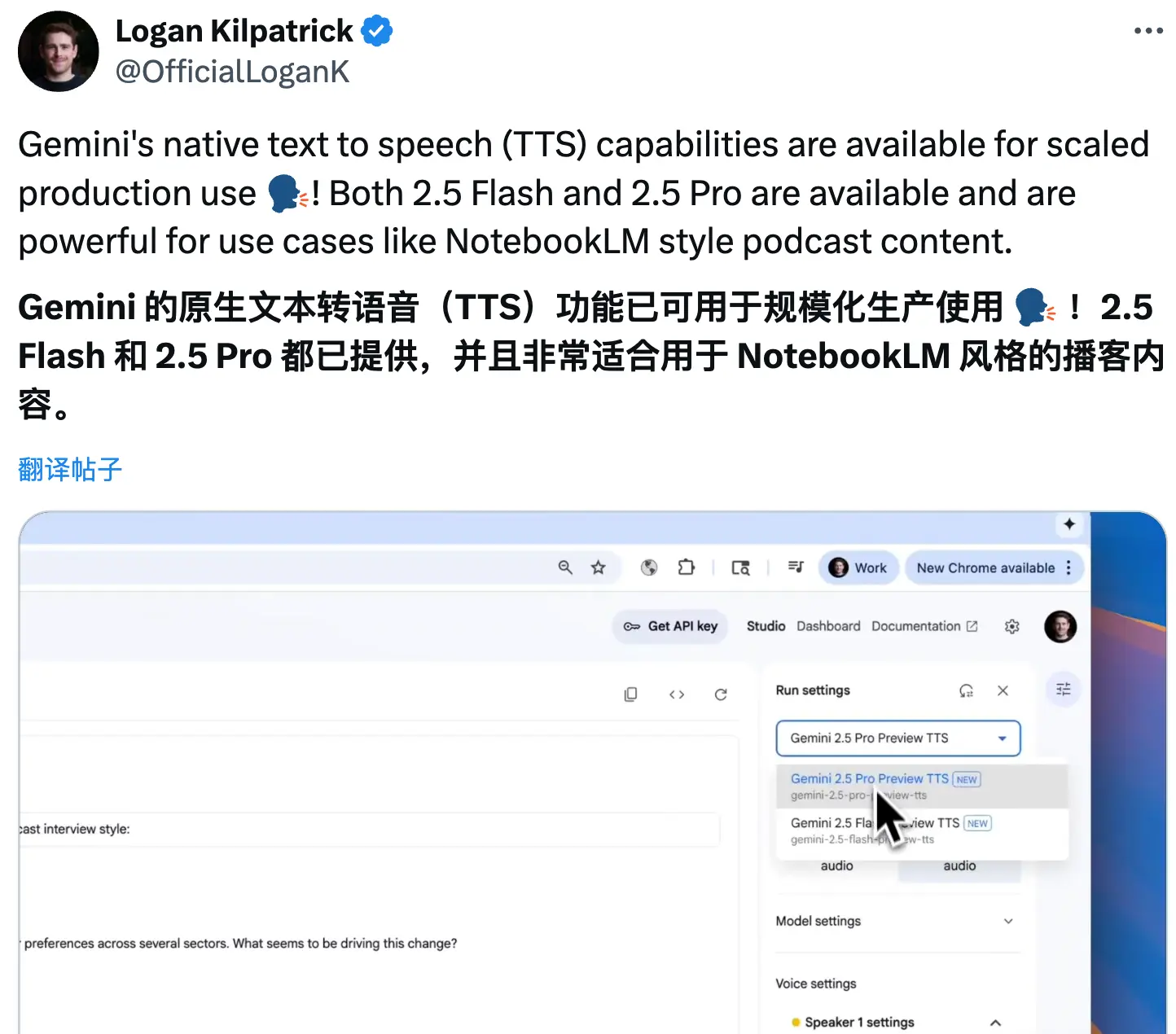
据官方人员透露,这项强大的功能适用于多种用例,例如创建类似NotebookLM风格的播客内容。该功能可以通过 AI Studio 和 Gemini API 体验使用。
Gemini API 可以使用原生文本到语音 (TTS) 生成功能,将文本输入转换为单声道或多声道音频。文字转语音 (TTS) 生成是可控制的,这意味着您可以使用自然语言来构建互动,并引导音频的风格、口音、节奏和语气。
TTS 功能不同于通过 Live API 提供的语音生成功能,后者专为互动式非结构化音频以及多模态输入和输出而设计。虽然 Live API 在动态对话情境中表现出色,但通过 Gemini API 进行 TTS 更适合需要精确朗读文本并对风格和音效进行精细控制的场景,例如播客或有声读物生成。
详情查看 https://ai.google.dev/gemini-api/docs/speech-generation