MiniMax Audio 正式发布了全新的 Speech-02 系列语音模型,支持将任何文件或 URL 转换为逼真的音频。用户只需一次输入,即可轻松创建有声读物和播客,最多可输入 20 万个字符,支持 30 多种语言的音频生成,效果自然流畅。
Speech-02 模型支持 30 多种语音,一次性可以输入 20 万字符。为用户带来更真实、更流畅、更便捷的音频体验。
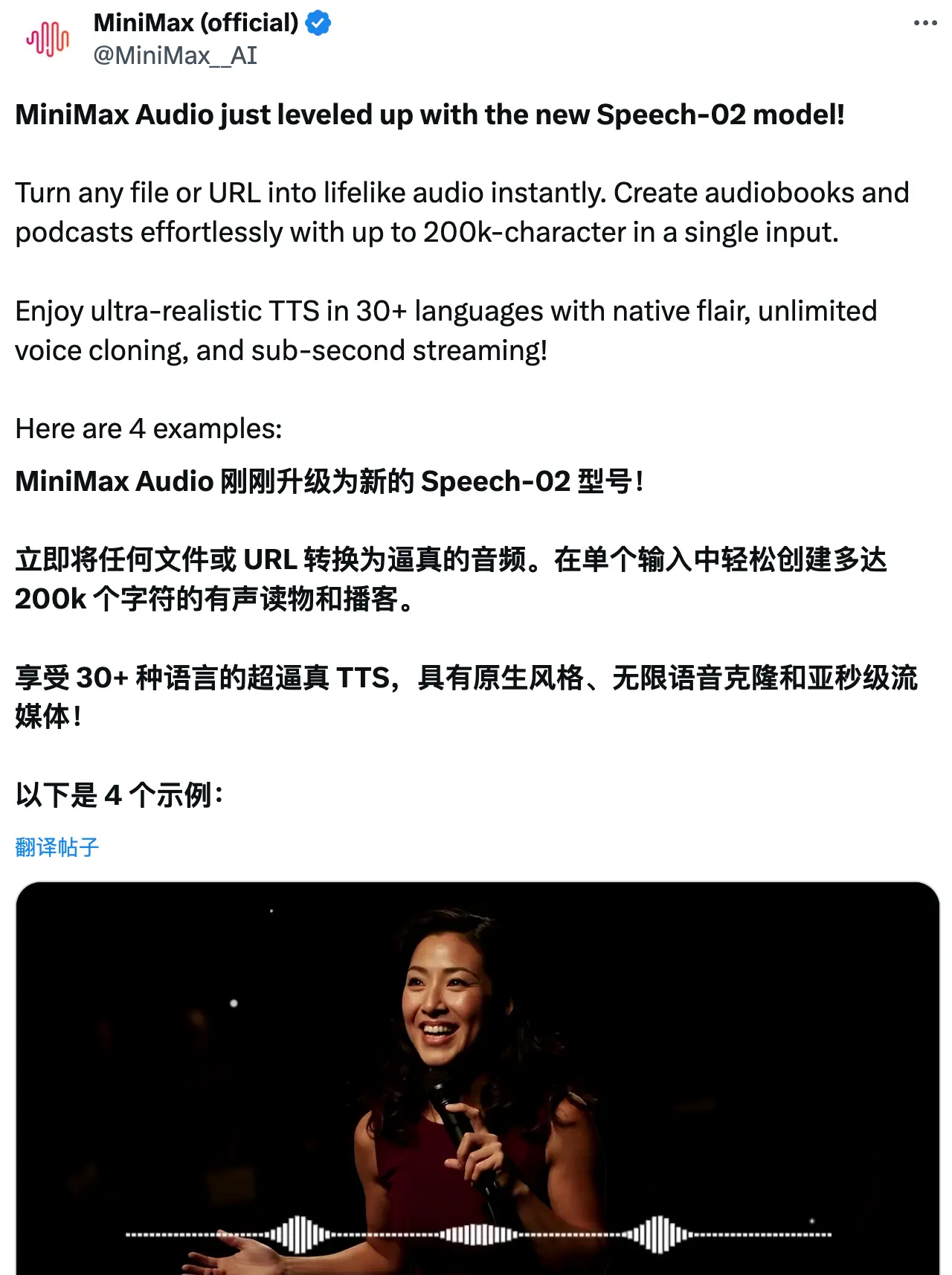
据官方介绍,该系列在多语言覆盖能力上实现了显著提升,能够更准确、更地道地呈现多种语言的发音。Speech-02的人声相似度高达99%,这意味着合成的语音听起来更加自然、贴近真人。
此外,该模型还实现了零节奏故障,彻底解决了音频播放过程中可能出现的卡顿和节奏不稳问题,保证了听感的连贯性和流畅性。
使用地址:https://www.minimax.io/audio