5 月 27 日,我们公开了 RWKV-8 首个新特性 DeepEmbed:对端侧友好的稀疏设计,解决 MoE 显存占用。
今天,我们公开与其相关的另一个新特性:DeepEmbedAttention(DEA) ,这是一种基于 RWKV-8 的 DeepEmbed 思路构建的注意力变体,拥有极小的 KV 缓存 ,尤其适合混合模型(例如后续的 RWKV-7s 混合模型),可将它们的长上下文性能提升到 Transformer 水准。
DEA 的结构定义例子:
# q: D => 256
# k: D => 32, k_up: 32 => 256, k_emb: V => 256
# v: D => 32, vup: 32 => D, v_emb: V => D
q = ln_q(q(x))
k = ln_k(k_up(k(x)) * k_emb(idx))
v = ln_v(tanh(v_up(v(x))) * v_emb(idx))
然后将 QKV 的输出加到 RWKV-7 的输出上。这适合并行计算,例如可在不同设备(或异构计算)计算 QKV 和 RWKV-7 部分。
这个注意力头的维度是 256,但由于 DEA 的 key 和 value 只需缓存 32 维,KV 总共只需缓存 64 个值(32+32)。
对于 RWKV-7,只需在每层加上一个 DEA head,就能显著增强长上下文能力。因此,对比现有的高效注意力机制(例如 MLA 使用 576 个值),DEA 的 KV 缓存进一步缩小到 64/576 = 1/9,实现了极致效率。
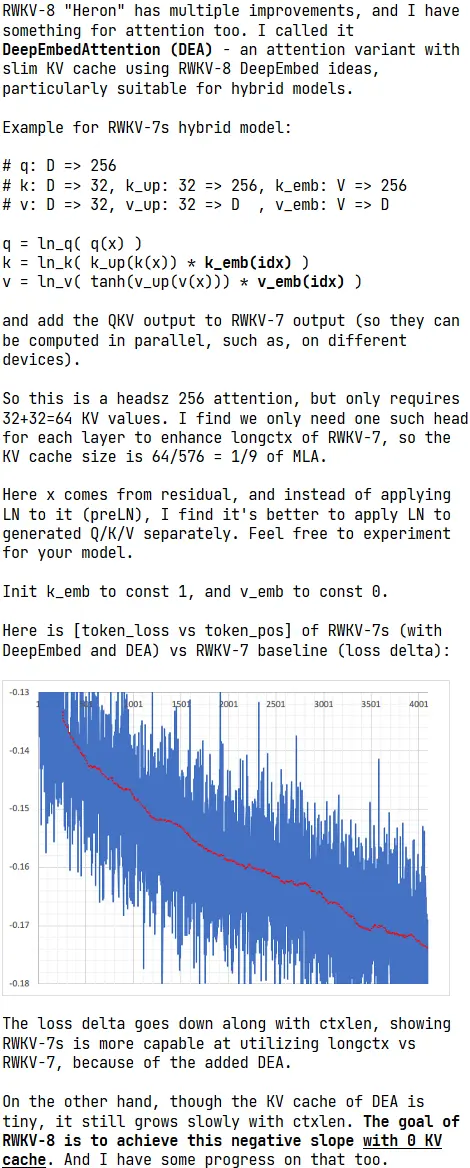
图中 loss delta 图的横轴是随着前文长度增加时 token 的位置(token_pos),纵轴表示两种架构在不同 token 位置的 loss 差值(token_loss delta)。
实验结果显示:随着前文长度增加,RWKV-7s(加入 DeepEmbed 和 DEA)在越来越长前文的 loss 相较原版 RWKV-7 持续下降,从 -0.13 降至 -0.17。
这意味着 RWKV-7s 这类添加了 DEA 的混合模型,在处理长上下文时表现更好。因为 token 越靠后,所依赖的前文也越长,而 loss 差值持续扩大,代表 RWKV-7s 对比 RWKV-7 更有能力利用越来越长的前文所包含的越来越多的信息,语言建模能力越来越强。
最后,尽管 DEA 的 KV 缓存非常小,但它仍会随上下文长度而缓慢增长。RWKV-8 的目标,是在完全无 KV 缓存的情况下也能实现强上下文能力,且我们也有方法,后续逐步公布,欢迎大家关注。