近日,空间理解模型SpatialLM正式发布首份技术报告。这一模型此前曾与DeepSeek-V3、通义千问Qwen2.5-Omni一起登上全球最大的开源社区HuggingFace全球趋势榜前三。
作为一款将大语言模型扩展到3D空间理解任务中的模型,SpatialLM能从3D点云输入生成结构化的空间场景描述,这一过程突破了大语言模型对物理世界几何与空间关系的理解局限,让机器具备空间认知与推理能力,为具身智能等相关领域提供空间理解基础训练框架。
在开源后经过广泛的实际验证,本次技术报告聚焦SpatialLM 1.1升级版本,其不仅包含了详细的消融实验与训练配方,还在点云编码方式、分辨率、用户指定识别类目等维度上实现优化。
多项基准测试数据显示:该模型在任务数据集微调后,在空间布局识别、3D物体检测任务中,均达到了相比与最新专业模型持平或更优的效果。
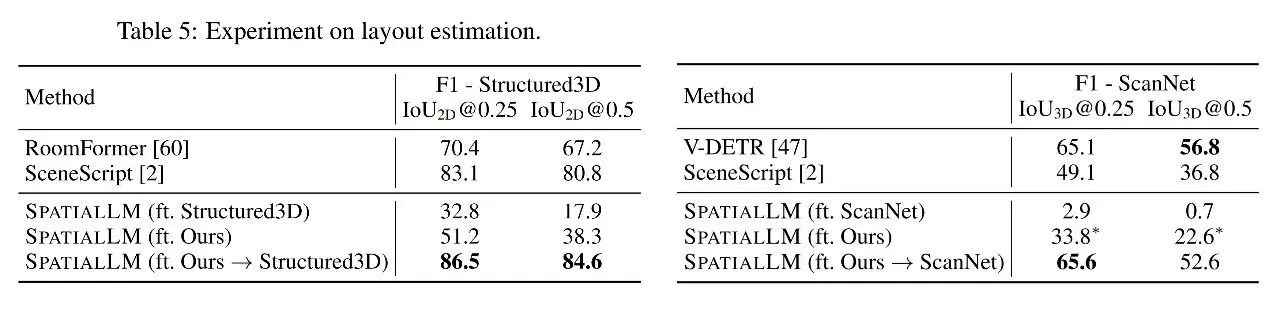
本次报告重点围绕算法框架和训练数据两方面展开。
在算法架构方面,SpatialLM将大语言模型(LLMs)扩展到3D空间理解任务中,特别在结构化室内建模领域实现了重要突破。
这一技术路线打破了传统任务专属架构(task-specific architecture)的限制,创新性地采用可编辑的文本形式表达场景结构。这一创新设计具有双重技术优势:
一方面发挥了群核科技强大数据集能力,通过持续训练不断优化空间识别精度;另一方面通过接入大语言模型,系统可直接接收并理解自然语言指令,使空间理解模型从简单任务执行工具转变为能够真正理解用户意图的智能系统,从而推进了LLMs在空间理解和推理方向的能力边界。
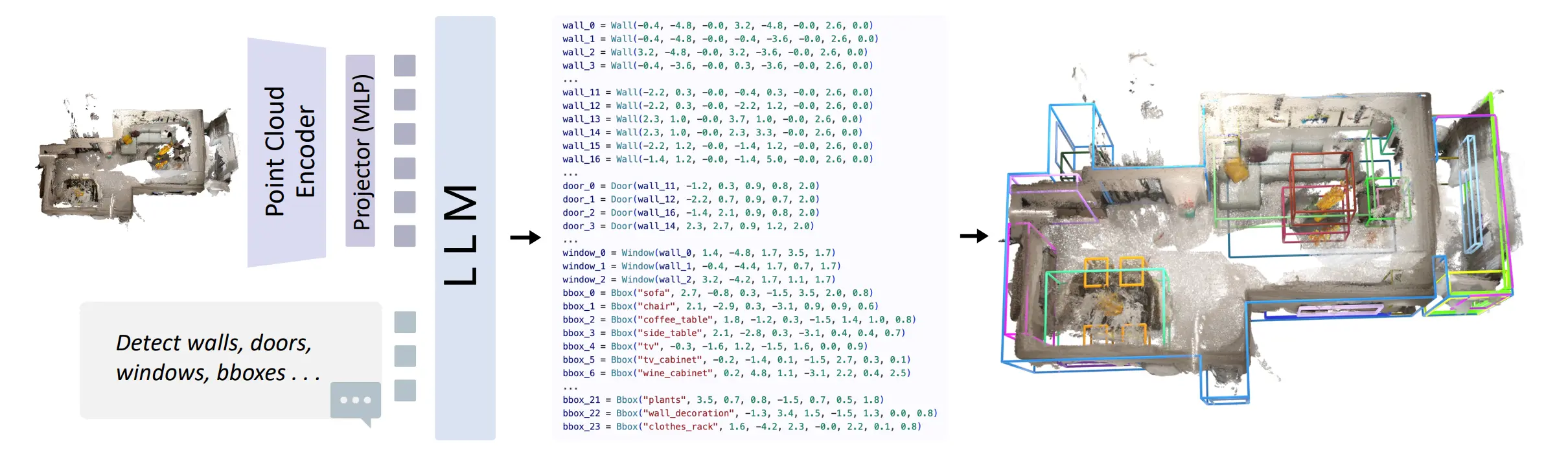
SpatialLM 模型的网络结构
在训练数据方面,SpatialLM构建了一个全新的包含3D结构化信息的合成点云数据集,打破了真实数据稀缺且难以标注的局限。
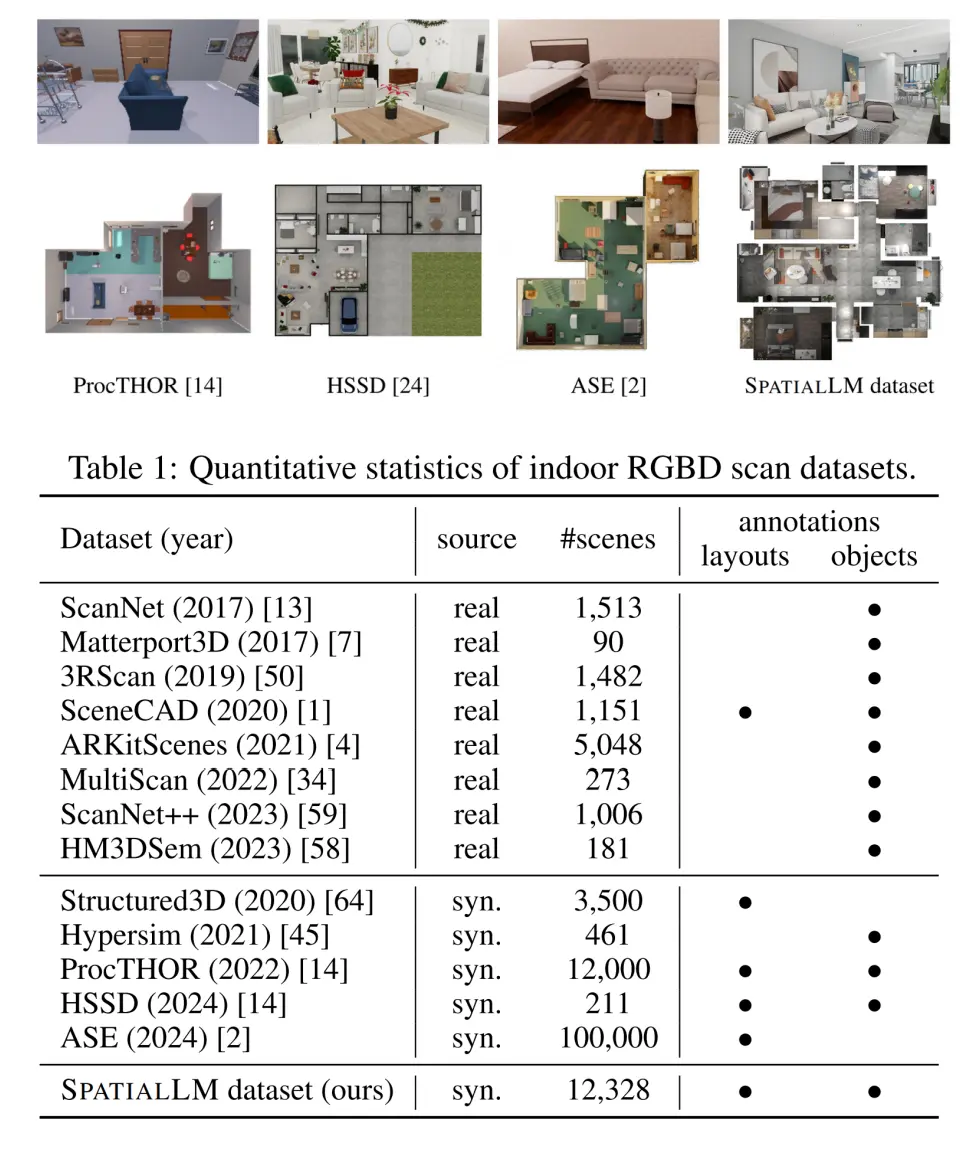
该数据集包含超1.2万场景、5.4万个房间的结构化室内点云数据,其规模远超ScanNet(仅包含1,513个场景)等现有数据集。所有数据均源自真实项目的专业设计模型,经严格筛选与解析后形成符合真实世界统计分布的虚拟环境,相较程序化生成的ProcTHOR等数据集具有更高真实性。
项目地址:https://manycore-research.github.io/SpatialLM/
报告详情:https://arxiv.org/abs/2506.07491