字节跳动 Seed 团队宣布正式发布了图像编辑模型SeedEdit3.0,技术报告对外公开,模型同步在即梦网页端开启测试,豆包 App 也即将上线。
SeedEdit3.0 基于文生图模型Seedream3.0开发,通过引入多样化的数据融合方法和特定奖励模型,解决了以往图像编辑模型在主体与背景保持、指令遵循等方面的不足。
根据介绍,该模型可处理并生成 4K 图像,在精细且自然地处理编辑区域的同时,还能高保真地维持其他信息。尤其针对图像编辑“哪里改与哪里不改”的取舍,该模型表现出更佳的理解力和权衡力,可用率相应提高。当用户需要去掉图片内一众行人,模型不仅可以准确识别并移除场景内的无关人物,连影子也能一并去掉。
评测结果显示,SeedEdit 3.0 在编辑保持效果、指令响应能力上领先于此前版本 SeedEdit 1.0,以及引入新数据源的 SeedEdit 1.5、进一步加入数据合并策略的 SeedEdit 1.6。对比 Gemini 2.0 和 Step1X,SeedEdit 3.0 也有一定优势。我们同时观察到,GPT-4o 位于右下角,表明其图像保持能力较 SeedEdit 3.0 有差距,但指令遵循更为出色。
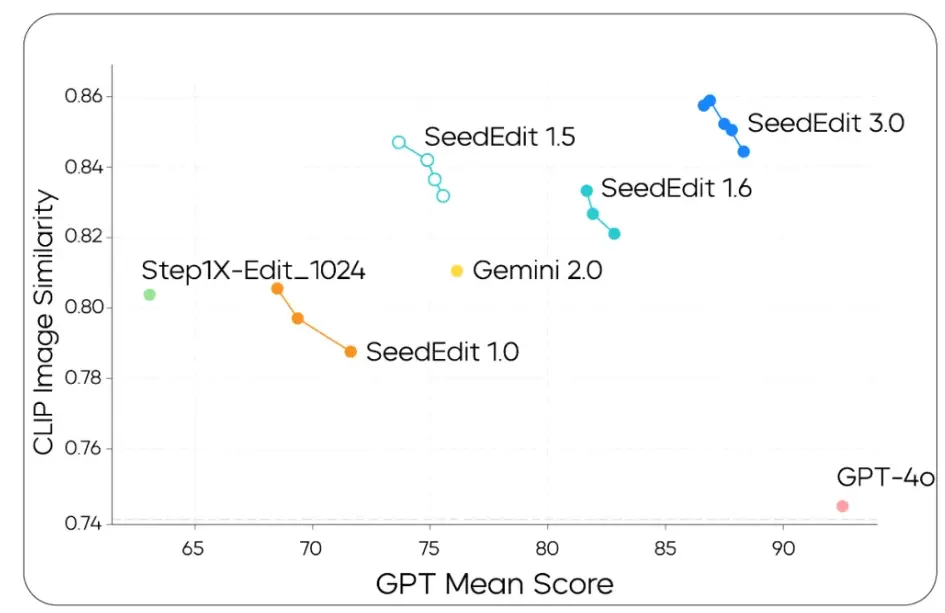
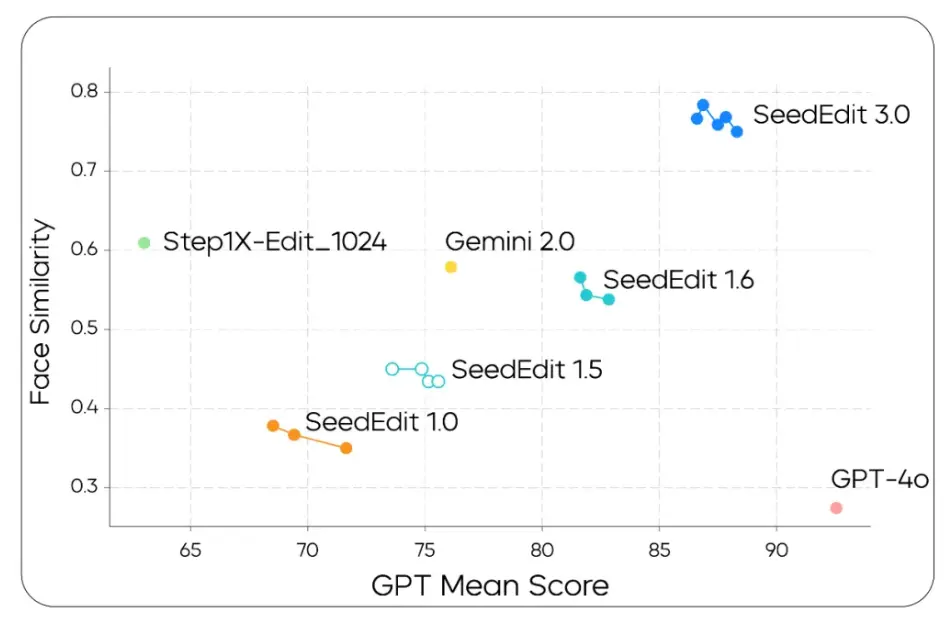
在综合测评中,SeedEdit 3.0 的图像保持能力最为突出,保持能力得分达到 4.07 分(满分 5 分),较此前版本 SeedEdit 1.6 得分提升 1.19 分;SeedEdit 3.0 可用率达 56.1%,较 SeedEdit 1.6 绝对值增加 17.46 个百分点。同时,SeedEdit 3.0 的指令遵循、生成质量表现也处于行业前列。
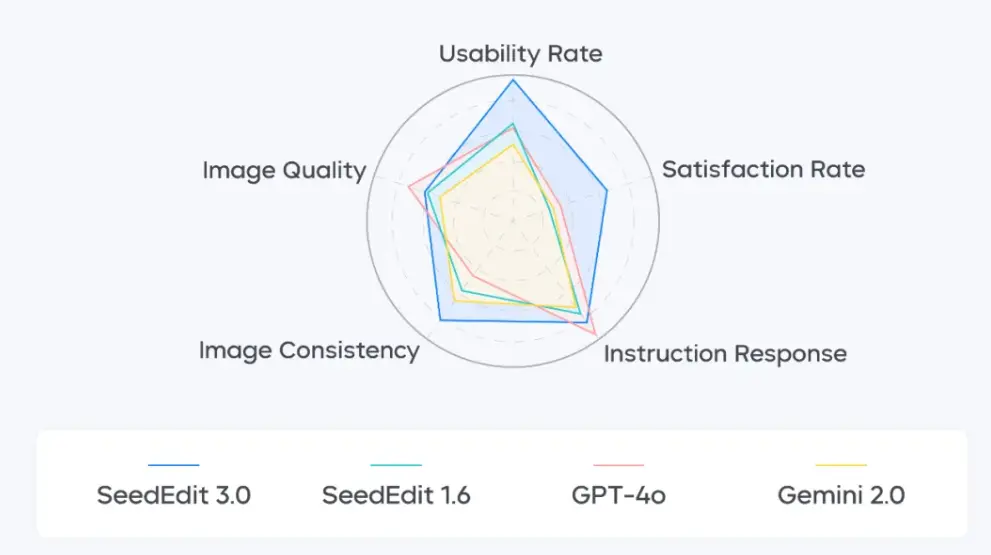
尽管 SeedEdit 3.0 在图像保持、可用率等方面表现不错,但项目团也承认,其在指令遵循方面仍有一定提升空间。未来除进一步优化编辑性能外,团队还将探索更丰富的编辑操作,让模型拥有连续多图生成、多张图像合成、故事性内容生成等能力。
更多详情可查看官方公告。