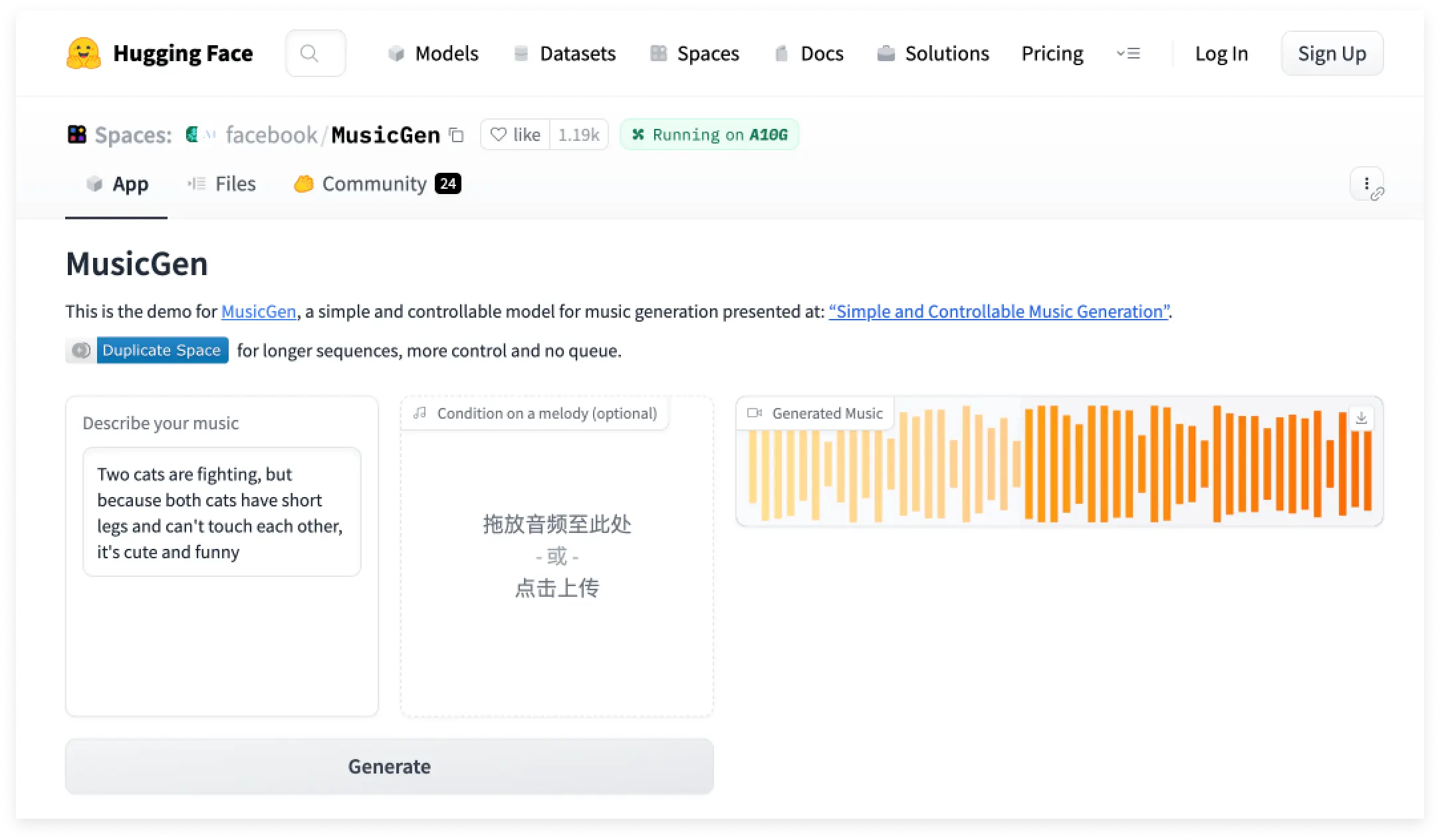
Meta 近日在 Github 上开源了其音乐生成模型 MusicGen。据介绍,MusicGen 主要用于音乐生成,它可以将文本和已有的旋律转化为完整乐曲。该模型基于谷歌 2017 年推出的 Transformer 模型。
研发团队表示:“我们使用了 20000 小时的授权音乐来对训练该模型,并采用 Meta 的 EnCodec 编码器将音频数据分解为更小的单元进行并行处理,进而让 MusicGen 的运算效率和生成速度都比同类型 AI 模型更为出色。”
除此之外,MusicGen 还支持文本与旋律的组合输入,例如你可以提出生成“一首轻快的曲目”并同时要求“将它与贝多芬的《欢乐颂》结合起来”。
研发团队还对 MusicGen 的实际表现进行了测试。结果显示,与谷歌的 MusicLM 以及 Riffusion、Mousai、Noise2Music 等其他音乐模型相比,MusicGen 在测试音乐与文本提示的匹配度以及作曲的可信度等指标上表现更好,总体而言略高于谷歌 MusicLM 的水平。
Meta 已允许该模型的商业使用,并在 Huggingface 上发布了一个供演示用的网页应用。
延伸阅读
- 谷歌推出 MusicLM,从文本生成音乐的模型