非营利组织 LAION-AI 发布了 OpenFlamingo,这是一个用于训练和评估大型多模态模型 (LMM)的框架,属于 DeepMind 的 Flamingo 模型(一种能够处理和推理图像、视频和文本的等多模态内容的框架)的开源复制品。
其数据集 OpenFlamingo-9B 的 Demo 页面展示了训练结果,用户可以上传图片让该模型进行识别。
小编浅试了一下,一张简单的图片耗时 11 秒,可以相当精准地描述图片的主体:
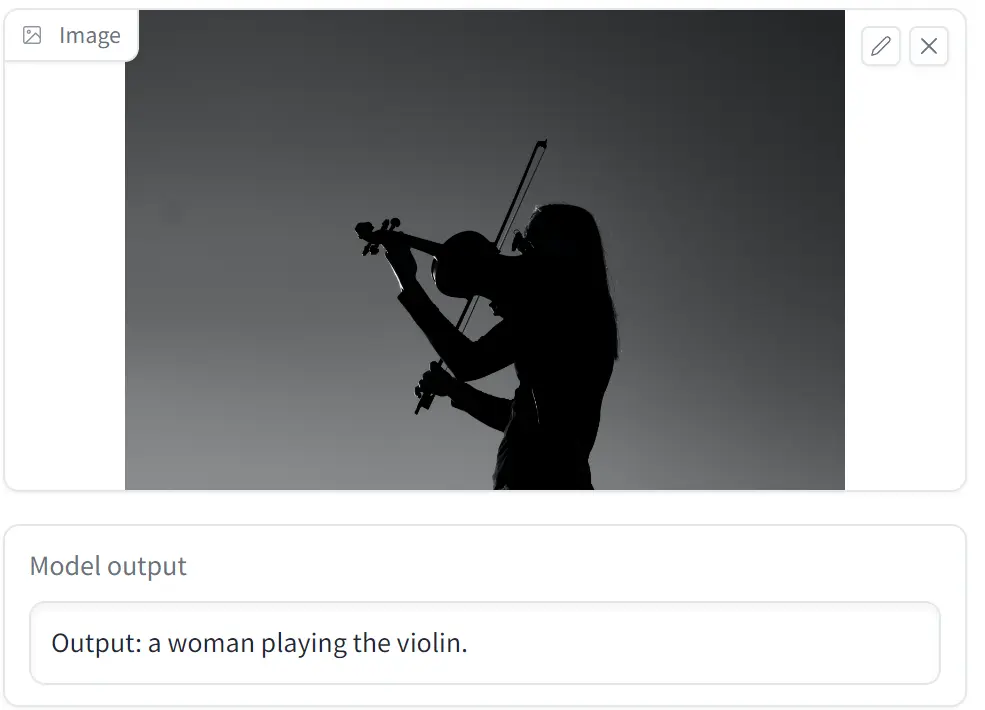
对于另一张内容较多的图片,识别的时间则上到 16 秒左右,但识别出来的内容仍是图片中心的主体,并没有其他细节内容。
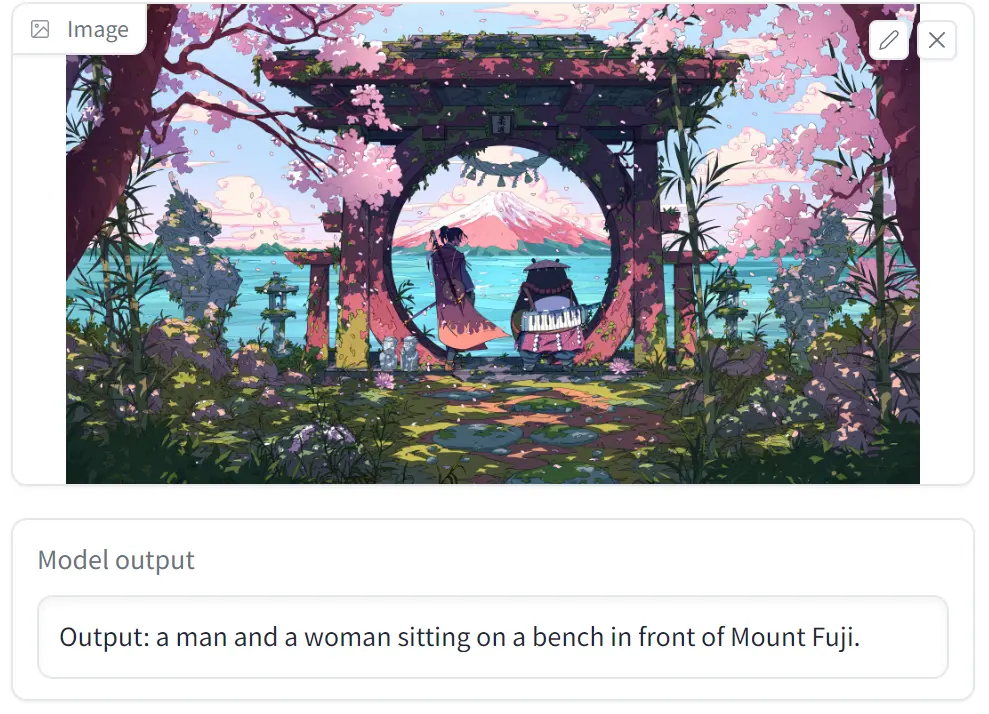
可以看出精度并不是很理想,还需要继续迭代。
LAION-AI 称 OpenFlamingo 的目标是开发一个可以处理各种视觉语言任务的多模态系统,最终目标是在处理视觉和文本输入方面与 GPT-4 的功能相匹配。
OpenFlamingo 的首个版本主要包含如下内容:
- 一个用于训练 Flamingo 风格 LMM 的 Python 框架(基于 Lucidrains 的 flamingo 实现和 David Hansmair 的 flamingo-mini 存储库)。
- 具有交叉图像和文本序列的大规模多模态数据集。
- 视觉语言任务的上下文学习评估基准。
- OpenFlamingo-9B 模型(基于 LLaMA )的第一个版本
OpenFlamingo-9B 模型在 LAION-AI 自研的多模态 C4 数据集上训练,LAION-AI 称即将发布该数据集的细节。
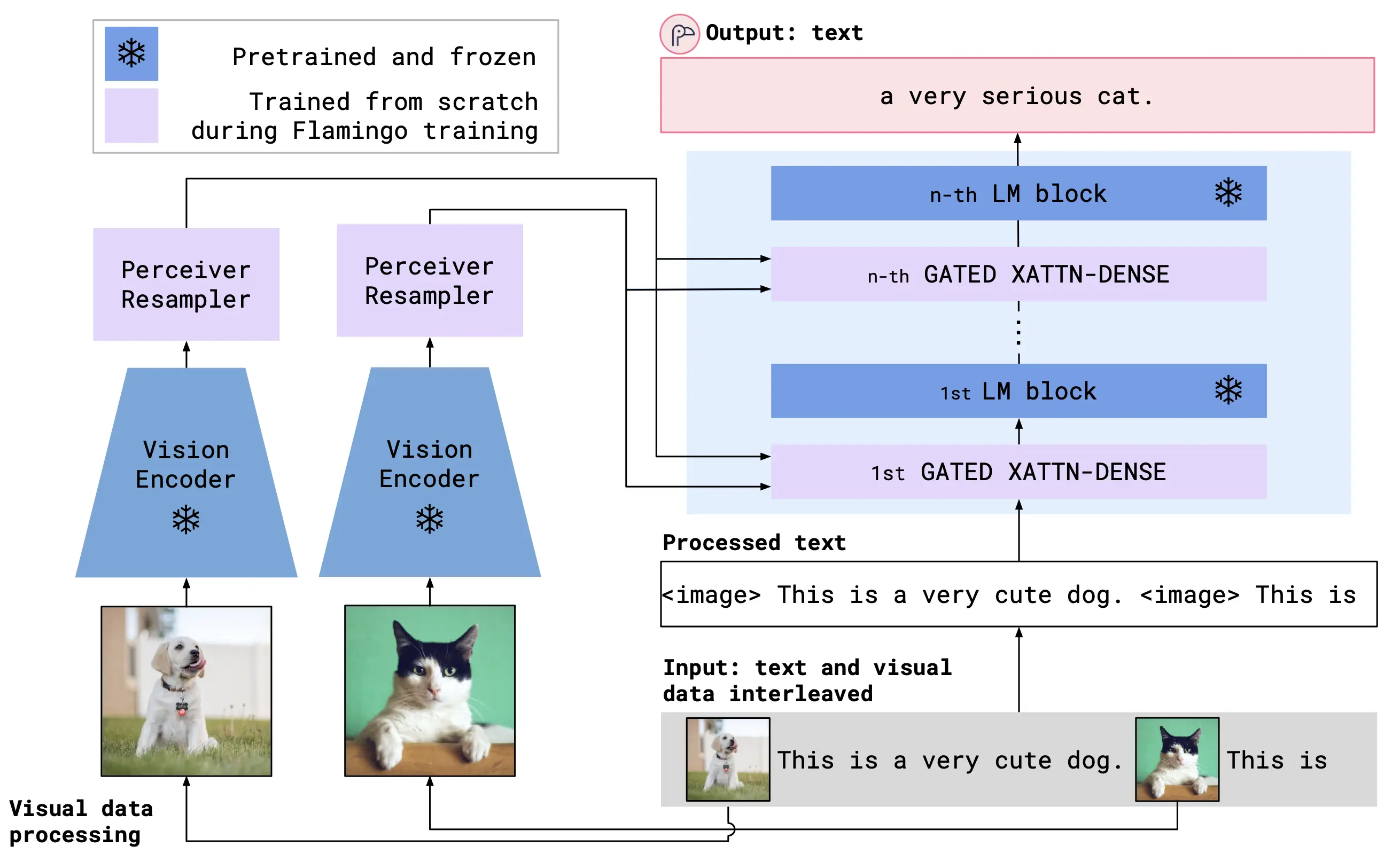
OpenFlamingo 的整体架构图如下,可以看出技术细节上很大程度上是跟着 DeepMind 的 Flamingo 模型走,Flamingo 模型在包含交叉文本和图像的大规模网络语料库上进行训练,OpenFlamingo 同样是使用交叉注意力层来融合预训练的视觉编码器和语言模型。