今年 8 月,Stability AI 开源了一个叫 Stable Diffusion 的 AI 模型,它可以根据用户给定的文本生成对应的图像。Stable Diffusion 的原理是通过 “学习”从互联网上抓取的大量图像数据集,以获得生成图像的能力。

这个 AI 在艺术圈引起了不小的争议,尤其是画师群体,更是有人直言“AI 要抢走我们的饭碗”。很多艺术家开始抵制 AI 进入艺术领域 ,开始在个人主页中放置“No AI Art”图像,来广泛抗议 AI 生成的艺术作品。
在名为 Spawning 的艺术家的倡导下,上周三,Stability AI 宣布允许艺术家从 Stable Diffusion 3.0(即将发布) 的训练数据集中删除自己的作品。艺术家需要在 Have I Been Trained 网站上找到自己的作品,然后选择将其退出训练集。
小编随手上传了一张图片进行搜索,在该站点找到了一大堆动漫/女孩相关的图像。但是如果我想要选择一些照片退出训练集,则需要注册一个账号。(顺便一提这个网站的账号密码需要大小写+数字+特殊字符,非常严谨)
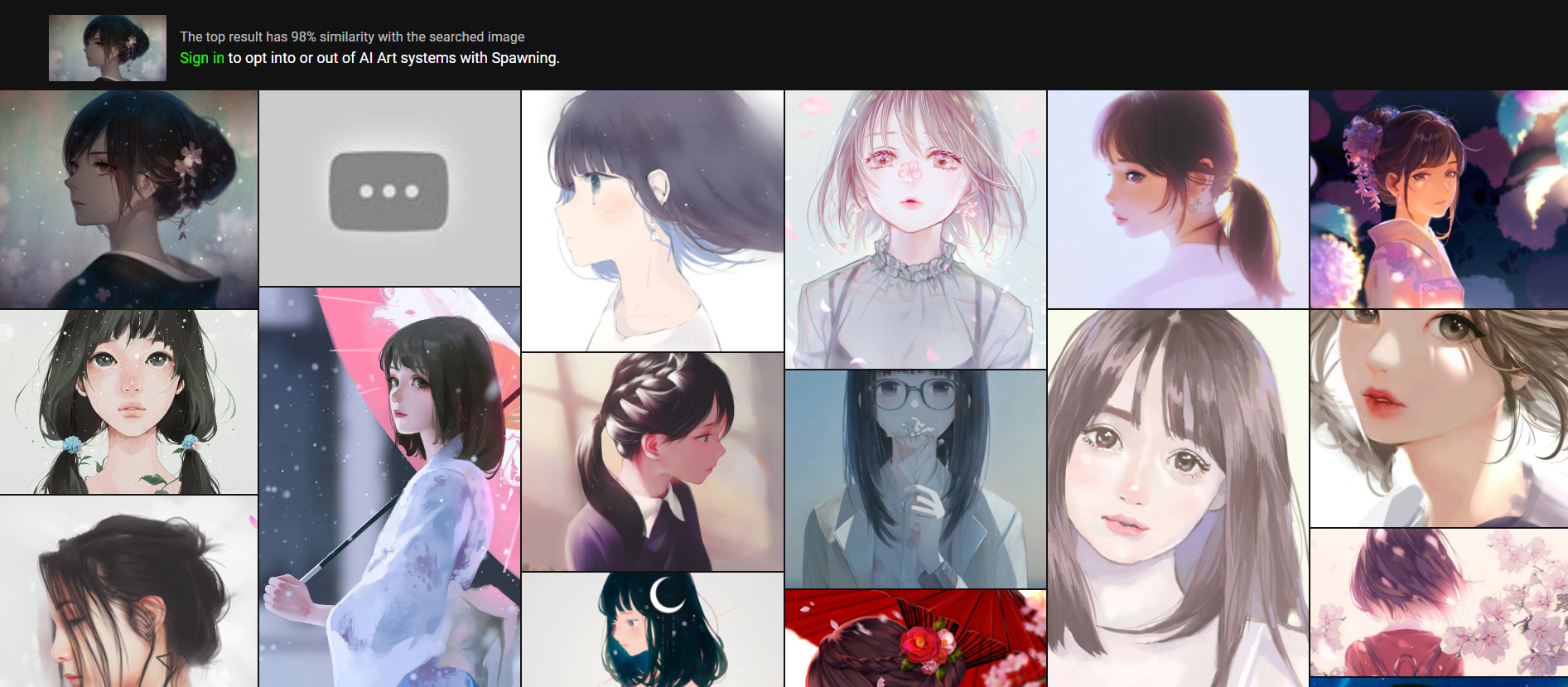
注册并登录后,我尝试选择了一些图片来“退出训练”,这个环节有一个大问题 —— 我完全不需要证明“这张图像是我的作品”,该网站无法验证用户对图像作品的所有权。

还有另一个问题,如果要从训练中删除自己的图像作品,它必须已经在 LAION 数据集中,且必须可以在 Have I Been Trained 网站上搜索到,但其他图像或数据集中可能存在同一图像的多个副本。另外,在主动删除之后,该数据集可能会再度从网上抓取你的作品图像。
这就涉及到“如何约束 Stability AI 从互联网上抓取数据集“,目前,Stability AI 在美国和欧洲法律范围内运作,训练 Stable Diffusion 的图像数据基本都是直接从网上抓取收集,未经原作者的许可。
有人指出,Stability AI 这个”选择退出“的机制,不符合欧洲通用数据保护条例,该条例规定抓取信息需要原作者主动同意,而不是默认假定。沿着这些思路,许多人认为所有的艺术作品都应该默认排除在 AI 的训练集之外,想为 AI 献身的艺术家可以选择将自己的作品加入 AI 数据集。
目前该问题还没有一个定论,很明显目前推出的 Have I Been Trained 网站不是很受欢迎。但起码 Stability AI 的 CEO Emad Mostaque 对 AI 与艺术的道德争议问题表现得非常友善,对艺术家们的倡导和建议也持开放态度,他在推特上写道:
我们团队对反馈非常开放,希望为所有人构建更好的数据集。
从我们的角度来看,我们相信这是一项变革性技术,并且乐于与各方接触并尽可能保持透明。
一切都在快速发展和成熟。