NVIDIA、Arm 和英特尔共同撰写了一份白皮书《深度学习的 FP8 格式》,描述了 8 位浮点 (FP8) 规范。它提供了一种通用格式,可通过优化内存使用来加速 AI 开发,并适用于 AI 训练和推理。
此 FP8 规范有两个变体,E5M2 和 E4M3。
兼容性和灵活性
FP8 最大限度地减少了与现有 IEEE 754 浮点格式的偏差,并在硬件和软件之间实现了良好的平衡,以利用现有的实施、加速采用并提高开发人员的生产力。
E5M2 使用 5 位作为指数,2 位作为尾数,是一种截断的 IEEE FP16 格式。在需要以牺牲某些数值范围为代价来提高精度的情况下,E4M3 格式会进行一些调整,以扩展可使用四位指数和三位尾数表示的范围。
新格式节省了额外的计算周期,因为它只使用八位。它可用于 AI 训练和推理,无需在精度之间进行任何重铸。此外,通过最大限度地减少与现有浮点格式的偏差,它为未来的人工智能创新提供了最大的自由度,同时仍然遵守当前的规范。
高精度训练和推理
对 FP8 格式的测试显示,在广泛的用例、架构和网络中,精度与 16 位精度相当。变压器、计算机视觉和 GAN 网络的结果都表明,FP8 训练精度与 16 位精度相似,同时提供了显著的加速。
下图为语言模型 AI 训练测试:
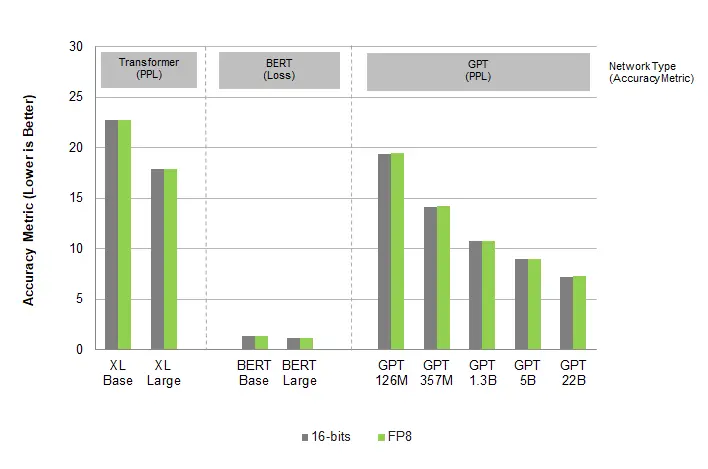
下图为语言模型 AI 推理测试:
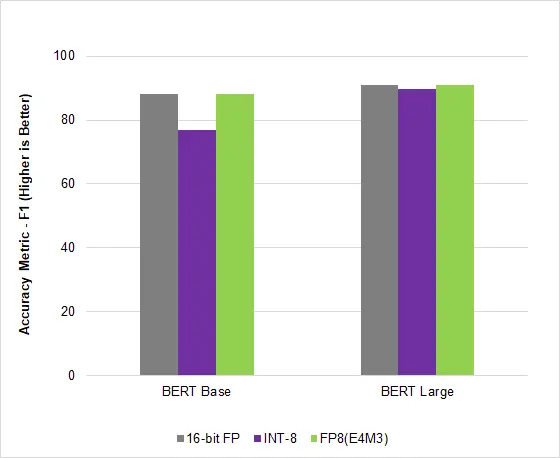
在 AI 行业常用的基准测试 MLPerf Inference v2.1中,NVIDIA Hopper 利用这种新的 FP8 格式在 BERT 高精度模型上实现了 4.5 倍的加速,在不影响准确性的情况下获得了更高的吞吐量。
标准化
NVIDIA、Arm 和 Intel 以开放、免许可的格式发布了此规范,以鼓励 AI 行业采用该规范。此外,该提案已提交给 IEEE。
通过这种可保持准确性的可互换格式,人工智能模型可以在所有硬件平台上一致且高效地运行,有助于推进人工智能技术的发展。