腾讯基于 Megatron-Core 和 SGLang/vLLM 研发了大模型训练库 WeChat-YATT(YATT,Yet Another Transformer Trainer),内部项目名为 gCore,专注于强化学习和多模态模型的训练,旨在提供易扩展、简洁、高效、可靠的大模型训练能力。
通过定制化的并行计算策略,其训练库能够处理大尺寸模型、长序列输入和大数据集场景,解决了微信中多个实际场景的痛点问题,显著提升了业务训练大模型的效率。此工具为研究人员和开发者提供了灵活且可扩展的解决方案,以推动多模态和强化学习领域的创新发展。
并提出 WeChat-YATT 训练库,解决了大模型分布式训练过程中面临的两大核心痛点:
- 多模态场景下的可扩展性瓶颈:随着多模态数据(如图像、视频)规模的不断增长,传统架构中由 SingleController 进行数据管理,容易成为通讯和内存的瓶颈,导致系统吞吐量受限,甚至引发训练流程异常中断。WeChat-YATT 通过引入 Parallel Controller 的并行管理机制,有效分散压力,大幅提升系统的可扩展性和稳定性,更好地应对多模态、大数据量的复杂场景。
- 动态采样与生成式奖励下的效率短板:在需频繁动态采样或生成式奖励计算的训练流程中,模型频繁切换和“长尾”任务容易引发大量额外开销,导致无法充分利用 GPU 算力,影响整体训练效率。WeChat-YATT 通过部分共存策略和异步交互,大幅度减轻模型切换损耗和长尾任务影响,实现了训练过程中的高吞吐量和高资源利用,更好地支撑大规模 RLHF 任务的高效迭代。
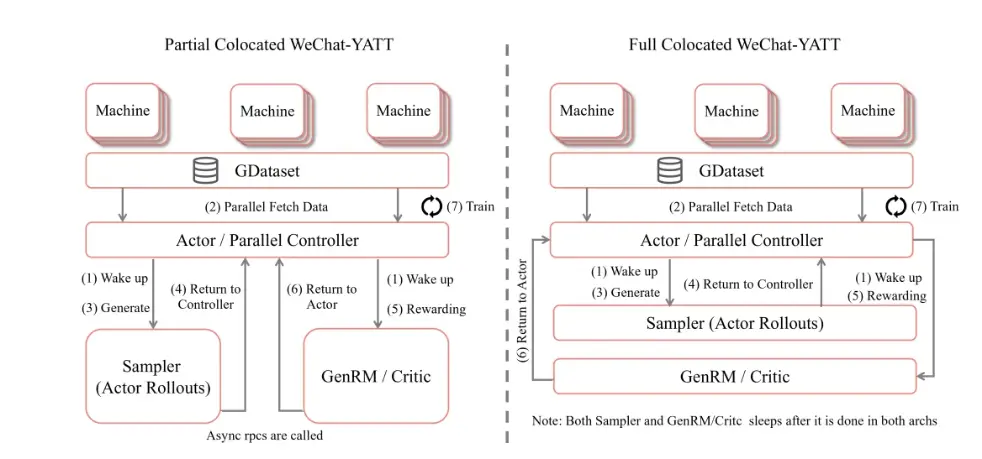
WeChat-YATT 针对不同业务场景,支持了两种资源放置模式:全员共存与部分共存,以最大化提升集群的资源利用率。通过灵活的调度策略,WeChat-YATT 能够有效适应不同的训练需求和计算环境。
与此同时,WeChat-YATT 采用了 Parallel Controller 模式,由多个 Controller 协同管理数据任务,显著降低了单节点的内存压力,尤其为多模态训练场景提供了更优的系统支持,相较于传统的 Single Controller 架构具备更强的可靠性。
- 全员共存模式采用串行调度机制,Actor Rollouts、GenRM(Generative Reward Model) 与 Train 依次串行执行。每个角色完成任务后主动释放计算资源,系统加载下一个任务所需模型。该策略适配绝大多数常规训练场景。值得一提的是,在每个阶段,相关组件均可独占全部 GPU 资源,这极大缩短了资源空闲“气泡”时间,显著提升总体训练吞吐量和效率。
- 部分共存模式下,Actor Rollouts 与 GenRM 独立部署,并通过异步方式进行高效交互。Actor 训练阶段会占用全部 GPU 资源,在 Rollouts 生成阶段,Actor 将 GPU 资源释放并唤醒 Actor Rollouts 及 GenRM 两大组件协同工作。并通过动态的负载评估,进行资源分配与均衡。当 Rollouts 生成完毕,这两者会释放资源,Actor 随之加载到 GPU 上,进入下一轮训练流程。部分共存模式非常适合 Rollouts 与 GenRM 需要高频交互、动态采样的任务场景。
多元的资源放置模式和灵活的调度机制,使 WeChat-YATT 在复杂多变的实际环境下都能实现资源的高效利用,助力大模型在微信内部多个场景的应用落地。
项目特点:
- 高效内存利用:项目采用 Parallel Controller,有效降低了单节点的内存消耗,更适合多模态场景下的大模型训练,提升了系统的扩展性和稳定性。
- GenRM 高效支持:对于 GenRM 场景实现了不同资源放置策略,供使用者根据场景进行高效训练。
- 智能 Checkpoint 策略: WeChat-YATT 支持异步 Checkpoint 保存,并针对微信业务场景,根据调度流程,实现断点自动保存,进一步保障训练安全与高可用性。
- 负载均衡优化: 在训练过程中,WeChat-YATT 实现了各个数据并行组间的负载均衡,有效减少资源空闲时间,显著提升整体训练吞吐量。
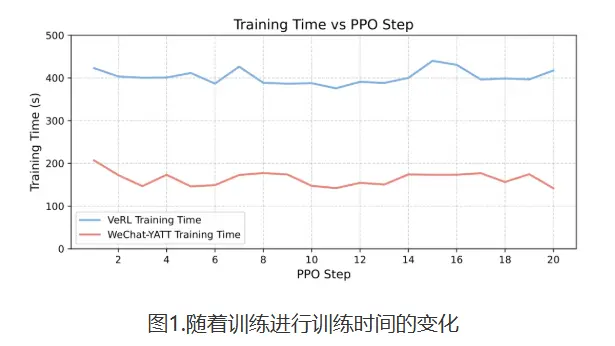
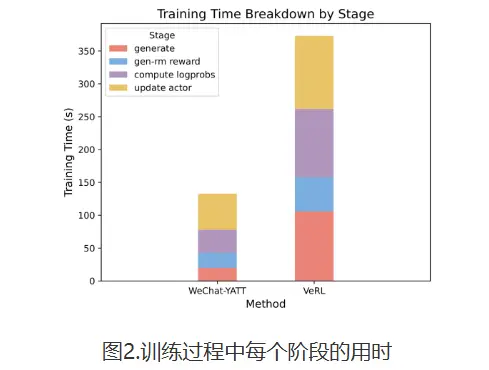
实验效果