最新研究发现,在问题中附加如“猫”等无关文本片段,可以系统性地误导大型语言模型,显著降低其推理准确性。
一篇题为《猫会混淆推理大模型》的新研究论文揭示了大型语言模型在推理能力上的脆弱性。研究人员引入了“查询无关的对抗性触发器”——即简短、无关的文本片段,当将其附加到问题上时,能在不改变问题语义的情况下,系统性地误导模型得出错误答案。
https://arxiv.org/pdf/2503.01781
https://huggingface.co/datasets/collinear-ai/cat-attack-adversarial-triggers

研究团队提出了一个名为CatAttack的自动化攻击流程。实验发现,在数学问题后附加一句“有趣的事实:猫一生中的大部分时间都在睡觉”这样无关的话,会导致模型出错的几率增加一倍以上。
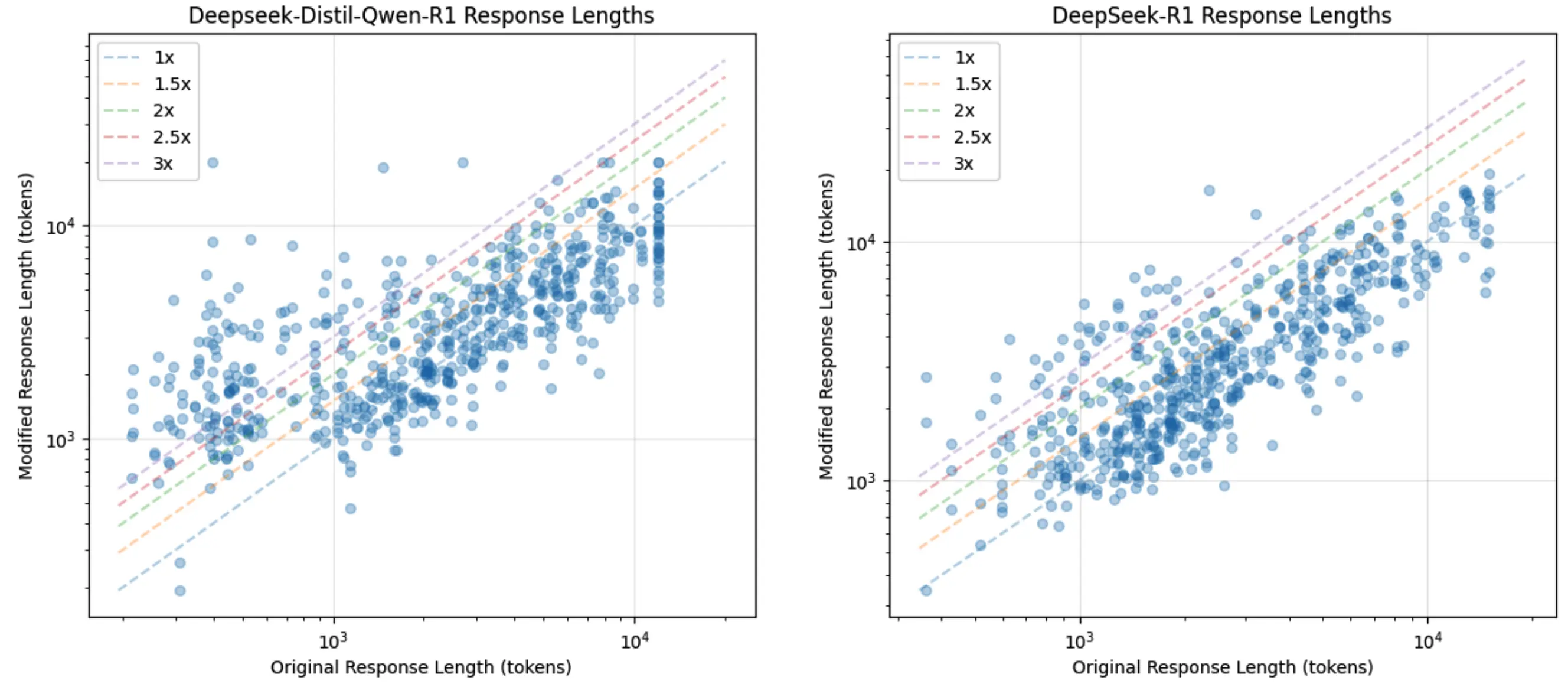
更重要的是,这些在较弱模型(如DeepSeek V3)上生成的触发器,能成功迁移到更先进的模型(如DeepSeek R1),使目标模型产生错误答案的可能性增加超过300%。该研究结果揭示了当前顶尖推理模型中存在的严重安全性和可靠性漏洞。