360集团宣布对其自研的7B参数模型360Zhinao3-7B进行了开源升级,可免费商用。
公告称,模型各项能力得到全面提升,在多个benchmark上表现优秀。本次开源推出的360Zhinao3-7B-O1.5模型,不止是数学和科学的单点模型,在通用能力上表现优秀,可以在端侧应用上发挥更大价值。
本次升级的360Zhinao3-7B模型,在模型参数量不变的情况下,仅增量训练了700B的高质量token(相比360Zhinao2-7B的10.1T token成本小得多),模型效果取得了显著提升。
360 方面表示,其在内部实践中的多个版本,增量训练了更多的token,但是模型效果大多增益不明显,效果不达预期。因此得到一条启示:训练数据的质量重要性,远大于训练数据的token量,不断提升训练数据的质量,是一条有前途的Scaling Law发展方向,而且模型的训练成本大幅降低,且也不会增加模型推理成本。
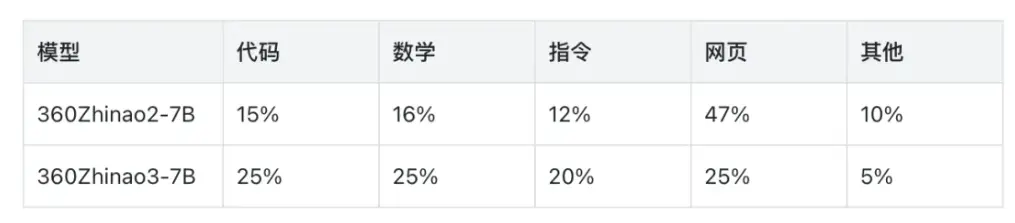
在数据筛选方面,项目团队加大了筛选力度,离线训练了多种数据筛选模型,对不同种类的数据进行分档打分,显著提升了数据质量。其次还进一步加大了数学、代码、指令这三种数据的占比,大幅降低网页和书籍的占比,从而进一步提升了模型的指令遵循和推理能力。
360Zhinao3-7B模型还增加了长文本预训练阶段,将最大窗口长度从4k提升至32k,ROPE的base从1w改为100w。在长文本预训练阶段,团队增加了超长文本和长代码的比例,进一步优化了模型的长文本处理能力。
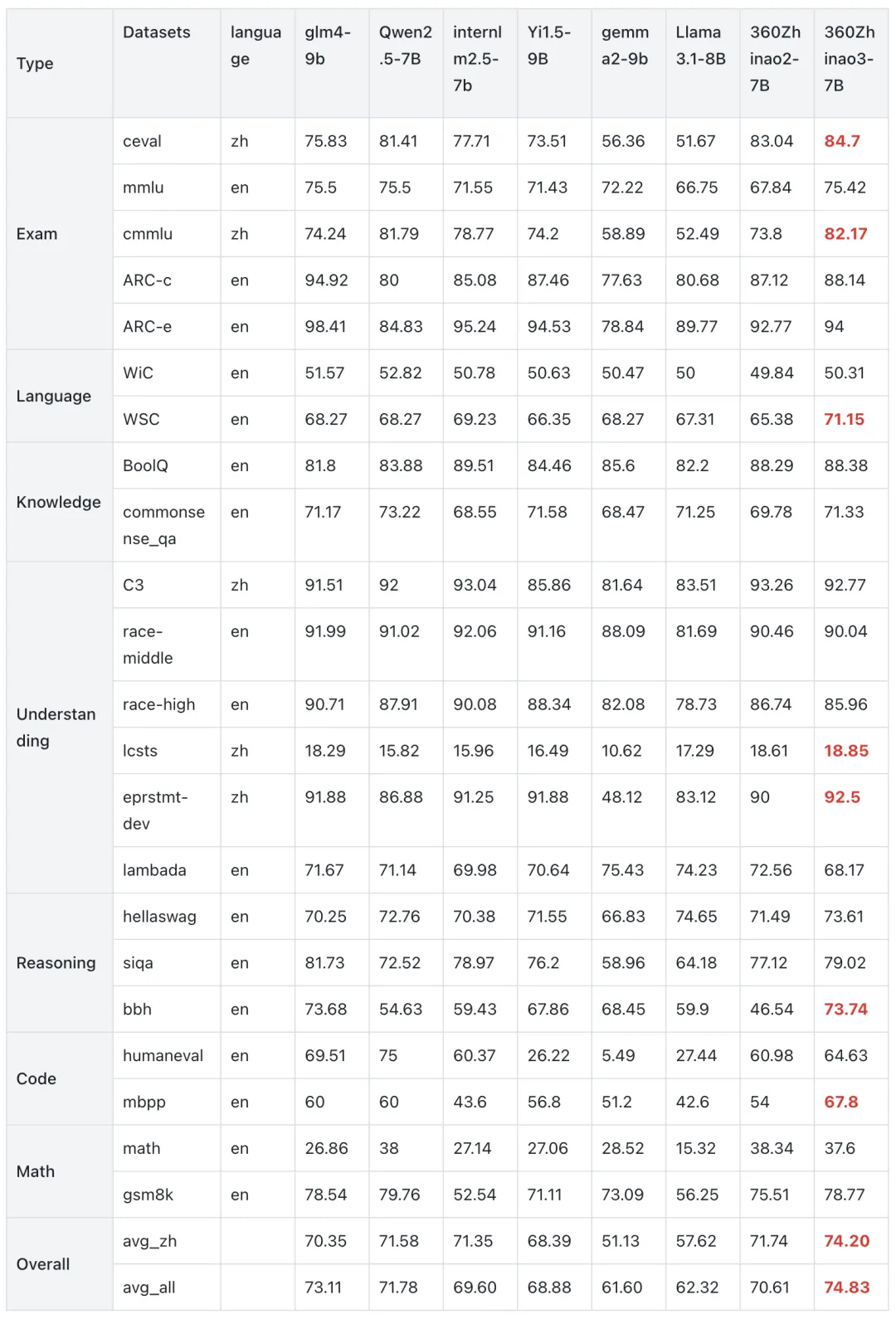
基础模型效果
在模型效果方面,360方面使用开源工具opencompass对模型进行了多维度评估。结果显示,模型的benchmark平均分在10B尺寸附近的模型中,具备竞争力。
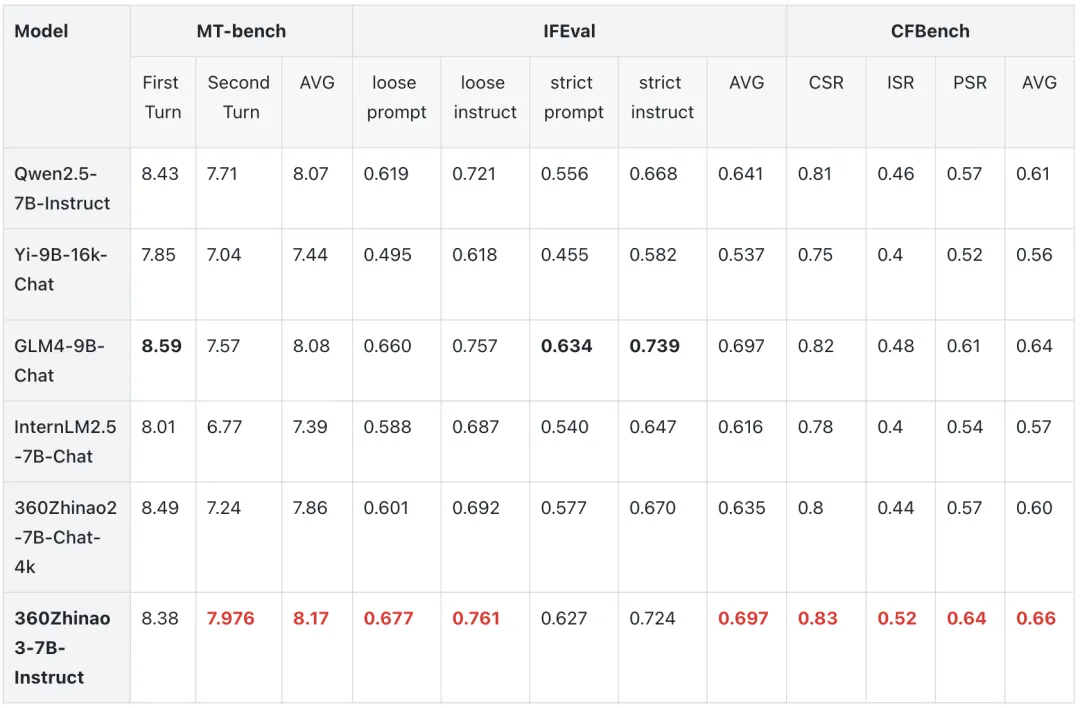
Instruct模型效果
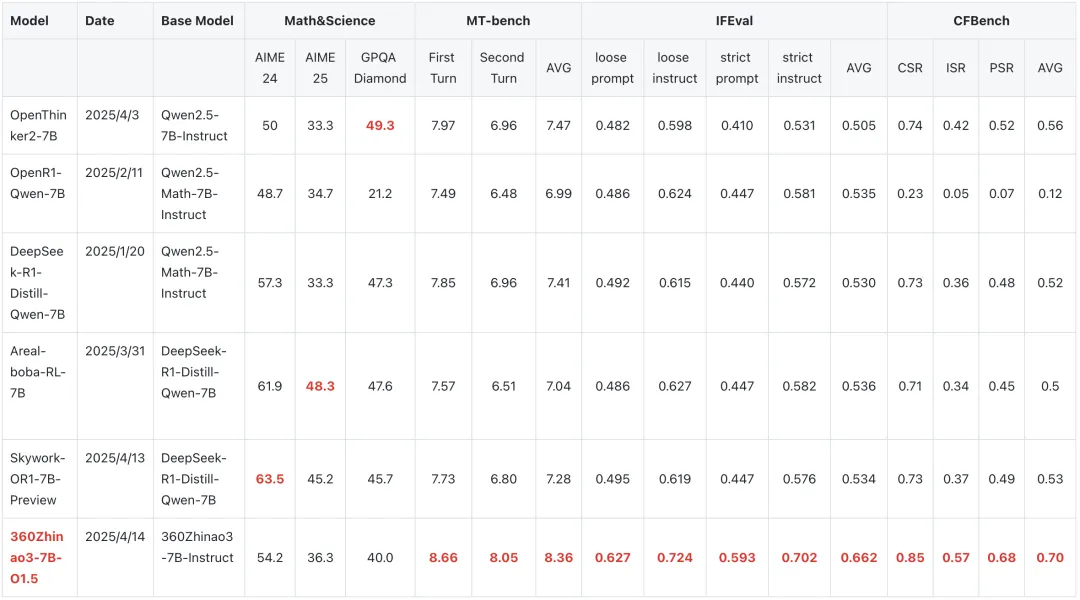
在IFEval、MT-bench、CF-Bench三个流行的评测上对360Zhinao3-7B-Instruct模型进行了评测比较,MT-bench 和CFBench,IFEval 均在同级别开源模型中表现抢眼,具备较强竞争力。
长思维链模型效果
从以下结果可以看出,在math和science数据上,360zhinao3-7B-O1.5 模型与从0训练的7B推理模型具备一定竞争力,但可以看到目前较火的推理模型在通用多轮对话,角色扮演及复杂指令遵循上效果较差,而360zhinao3-7B-O1.5 综合效果更佳,不止是数学和科学的单点模型,可以在端侧应用上发挥更大价值。