根据 TechCrunch 的报道,OpenAI o3模型的第一方与第三方基准测试结果存在显著差异,引发了外界对其公司透明度和模型测试实践的质疑。
去年12月,OpenAI首次发布o3模型时宣称,该模型能够在FrontierMath这一极具挑战性的数学问题集上正确回答超过四分之一的问题。这一成绩远远超过了竞争对手 —— 排名第二的模型仅能正确回答约2%的FrontierMath问题。
OpenAI首席研究官Mark Chen在直播中表示:“目前市场上所有其他产品在FrontierMath上的成绩都不足2%,而我们在内部测试中,使用o3模型在激进的测试时计算设置下,能够达到超过25%的正确率。”
然而,这一高分似乎是一个上限值,是通过一个计算资源更为强大的o3模型版本实现的,而并非是OpenAI上周公开发布的版本。
负责FrontierMath的Epoch研究所于上周五公布了其对o3模型的独立基准测试结果,发现o3的得分仅为约10%,远低于OpenAI此前声称的最高分数。
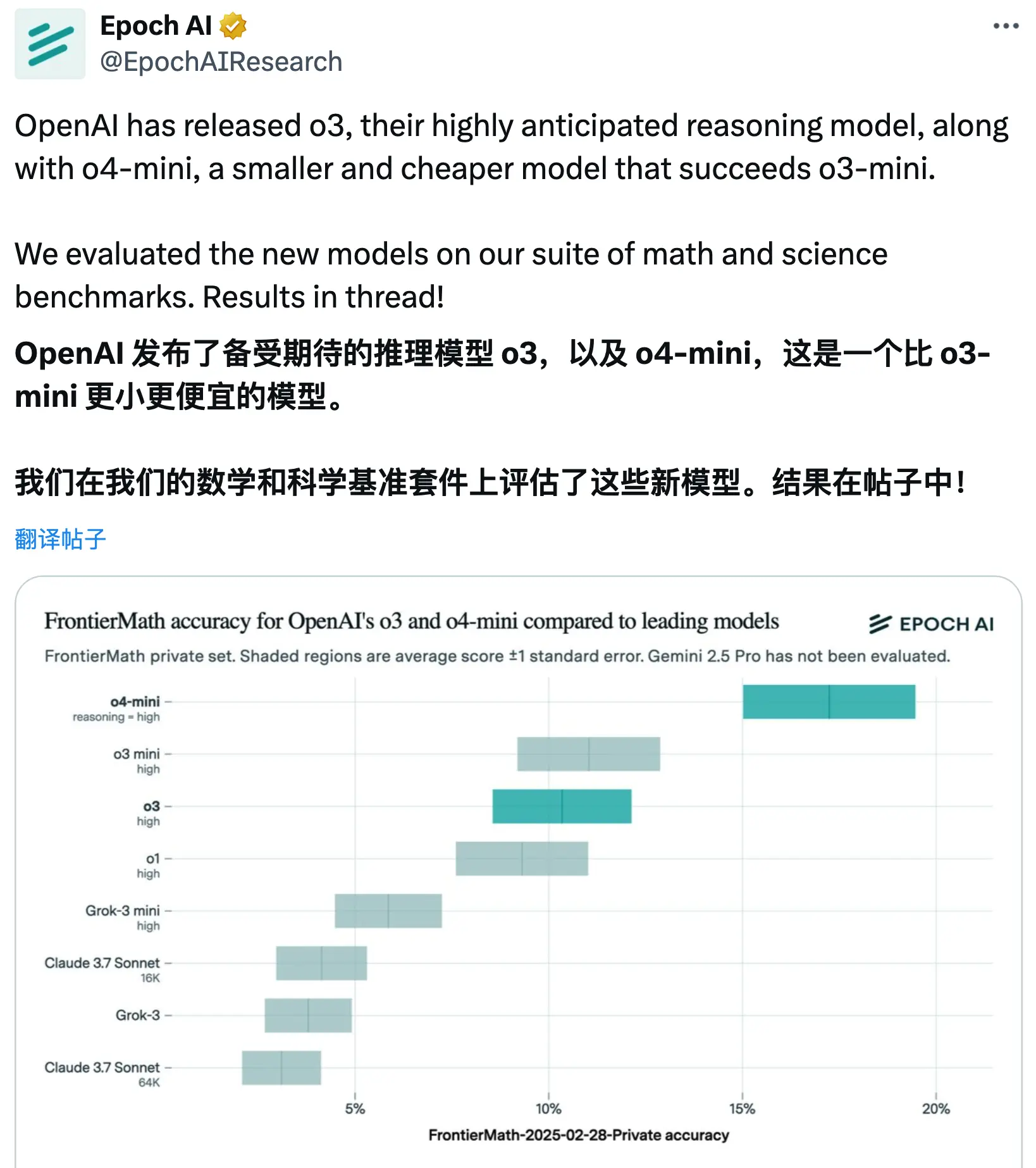
这并不意味着OpenAI故意撒谎,该公司在12月份公布的基准测试结果中也包含了一个与Epoch测试结果相符的较低分数。Epoch还指出,其测试设置可能与OpenAI有所不同,并且其评估使用了更新版本的FrontierMath。