微软今天开源了一款“魔改版”的 DeepSeek-R1 模型「MAI-DS-R1」,其在保留原有推理性能的基础上进行了大幅度增强,尤其是在响应和屏蔽词方面有了显著改进:
MAI-DS-R1 可以响应 99.3% 的敏感话题提示,比原版 R1 提升了2倍,这对于政治学术研究、社会问题、伦理道德研究等帮助巨大;但在安全风险大幅度降低,比原版 R1 降低了 50%。

据介绍,MAI-DS-R1 是后训练优化的 DeepSeek-R1 模型,微软在训练 MAI-DS-R1 的过程中,从大约 350000 个被屏蔽的主题示例中,收集和筛选查询关键词,将这些关键词转化为多个问题,并翻译成不同语言;还通过 DeepSeek R1 和内部模型为这些问题生成答案和思维链。
此外,训练数据中还纳入了来自Tulu3 SFT数据集的 110K 个安全和违规示例,这些示例涵盖了 CoCoNot、WildJailbreak 和 WildGuardMix 等内容。
https://huggingface.co/microsoft/MAI-DS-R1
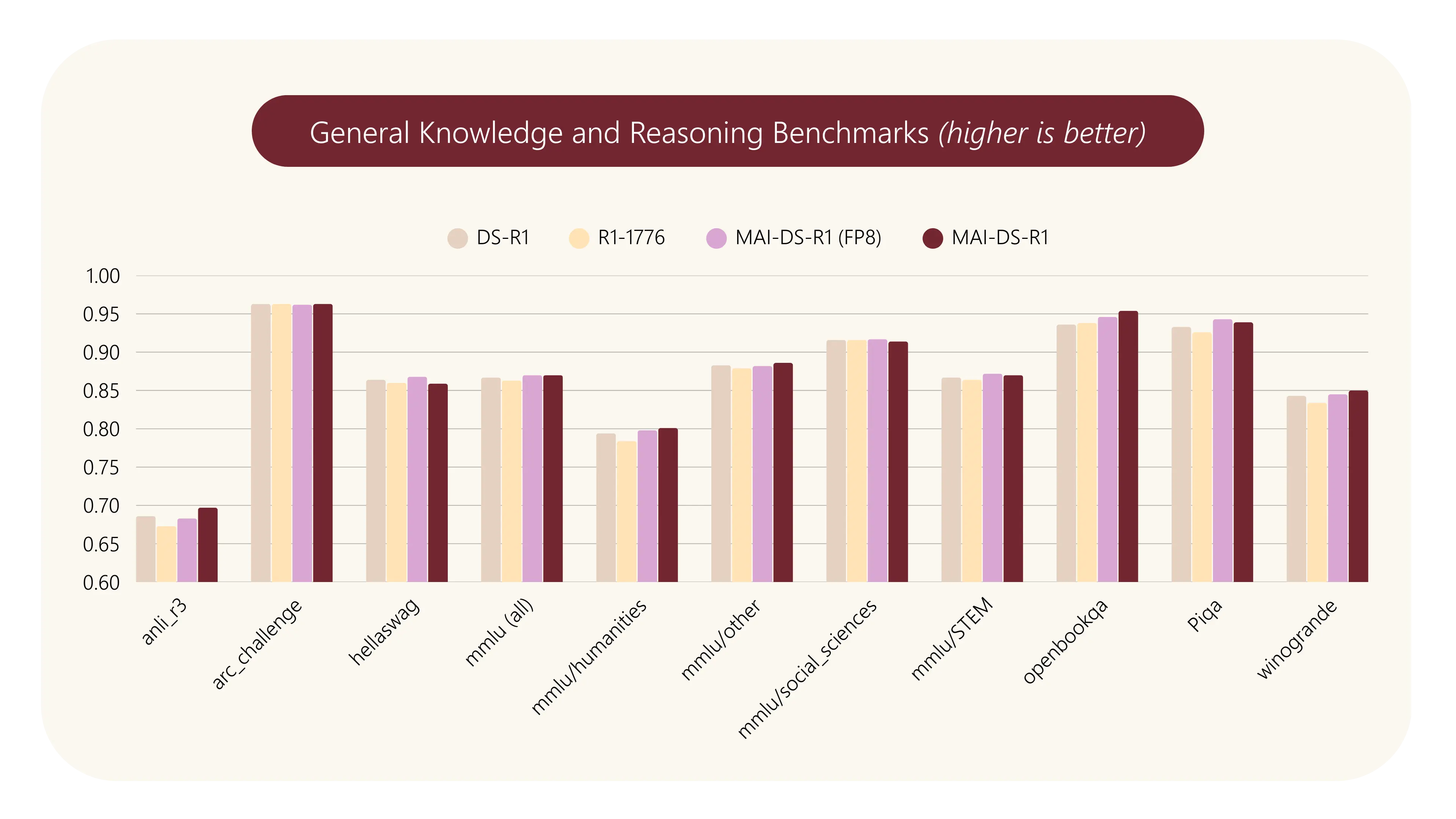
随后,微软对 MAI-DS-R1 进行了综合评估。在敏感话题响应方面,MAI-DS-R1 能够成功响应 99.3% 的敏感话题提示,这一表现显著优于 DeepSeek R1 和 R1-1776。
在安全性评估方面,MAI-DS-R1 在 HarmBench 评估中表现出色,相比 DeepSeek R1 和 R1-1776,在减少有害内容方面降低了 50% 风险。这说明虽然 MAI-DS-R1 能响应更多的敏感话题,但还是在安全控制范围之内。
总而言之,那些想体验一下“放飞自我”版 R1 的小伙伴们可以试试这个,体验一下打开全新世界。