Protect AI 最新发布的一份 2024 年 7 月漏洞报告在各种大语言模型(LLM)中发现了 20 个严重漏洞。
这些漏洞是通过 Protect AI 的“huntr”漏洞赏金计划发现的,这也是全球首个 AI/ML 漏洞赏金计划。该社区由 15,000 多成员组成,在整个 OSS AI/ML 供应链中寻找有影响力的漏洞。
“我们发现供应链中用于构建支持 AI 应用程序的机器学习模型的工具容易受到独有的安全威胁。这些工具是开源的,每月被下载数千次以构建企业 AI 系统。它们还可能存在漏洞,这些漏洞可能直接导致完全的系统接管,例如未经身份验证的远程代码执行或本地文件包含。”
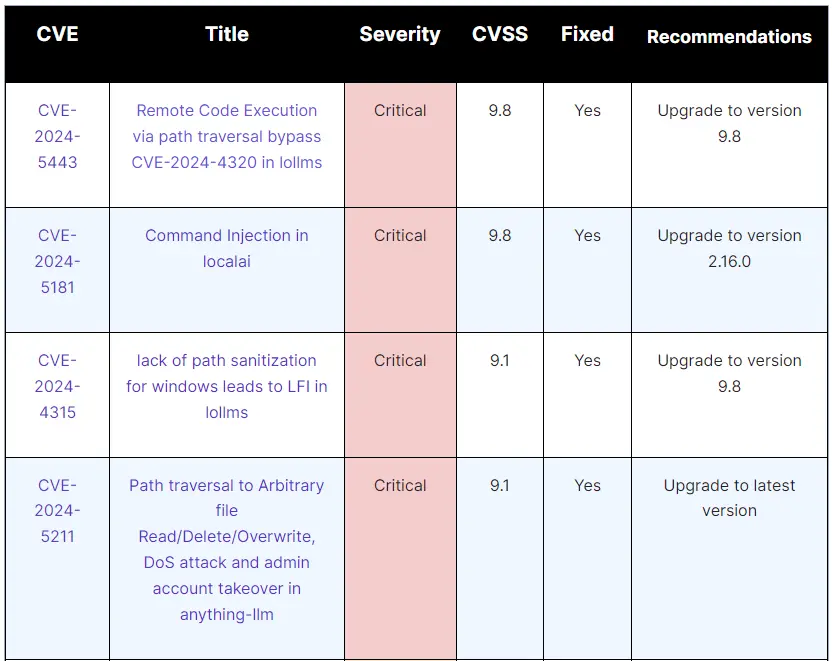
此次报告的漏洞涉及了 ZenML、lollms 和 AnythingLLM 等广泛使用的工具。ZenML 中的权限提升漏洞,未经授权的用户可以通过发送精心设计的 HTTP 请求将其权限提升到服务器帐户。可以通过修改请求负载中的 is_service_account 参数来利用此漏洞。利用此漏洞的攻击者可能会破坏整个系统,导致未经授权的访问和控制。
lollms 中的本地文件包含 (LFI) 漏洞,允许攻击者读取或删除服务器上的敏感文件,从而可能导致数据泄露或拒绝服务。该漏洞源于 lollms 中的 sanitize_path_from_endpoint 函数未正确处理 Windows-style paths,导致其容易受到目录遍历攻击。
AnythingLLM 中的路径遍历漏洞使得攻击者可以读取、删除或覆盖关键文件,包括应用程序的数据库和配置文件。该漏洞位于 normalizePath() 函数中,可导致数据泄露、应用程序入侵或拒绝服务。
更多详情可查看完整报告。