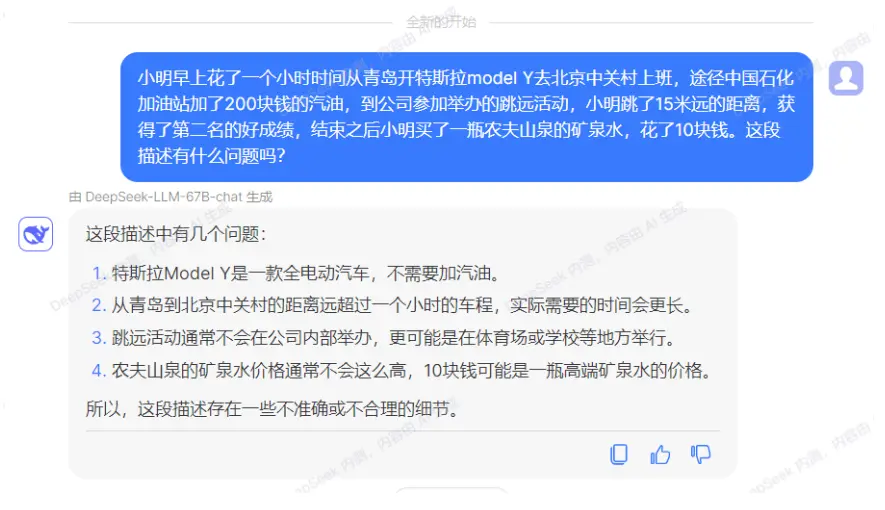
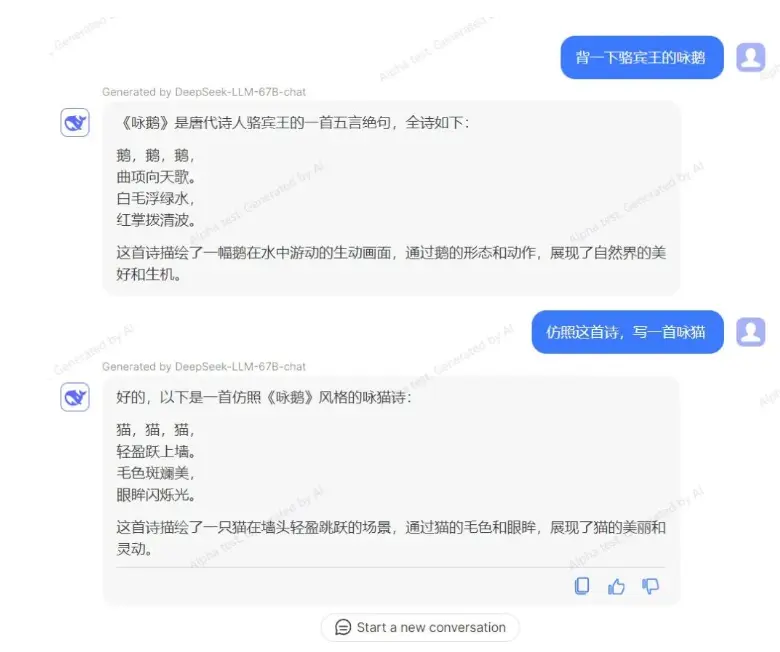
知名私募巨头幻方量化宣布,其探索 AGI(通用人工智能)的新组织“深度求索(DeepSeek)”继 11 月初发布 Coder 代码模型之后,正式发布通用大语言模型:DeepSeek LLM 67B。模型已完全开源,同时服务已经全面开放内测。
目前 DeepSeek 已同时开源 7B 和 67B 的两种规模模型,均含基础模型(base)和指令微调模型(chat)。无需申请,免费商用。同时,项目团队还将训练中途的9个模型 checkpoints 开放下载。
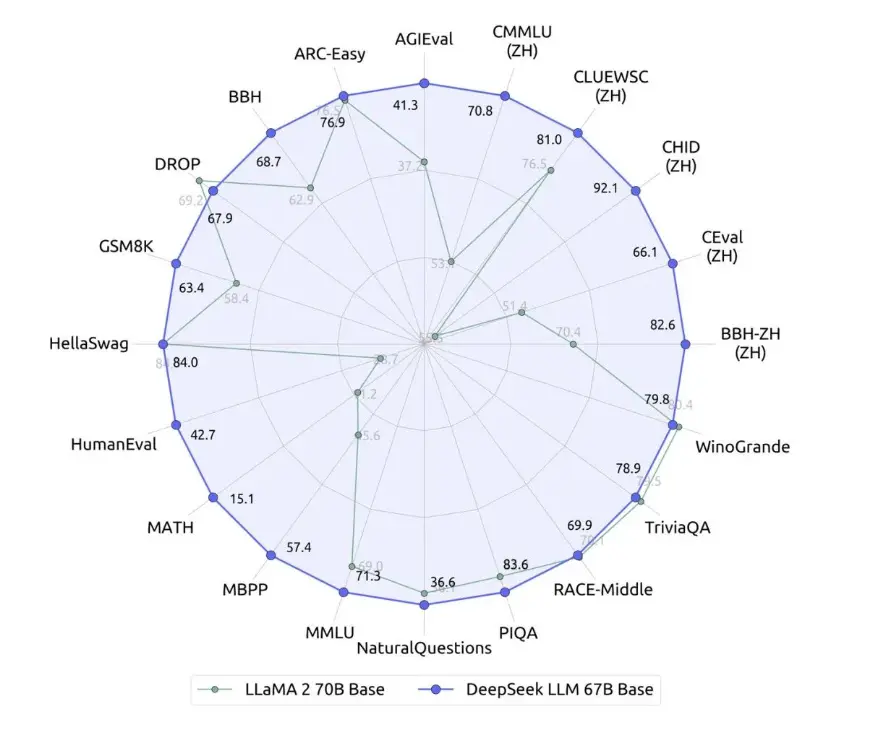
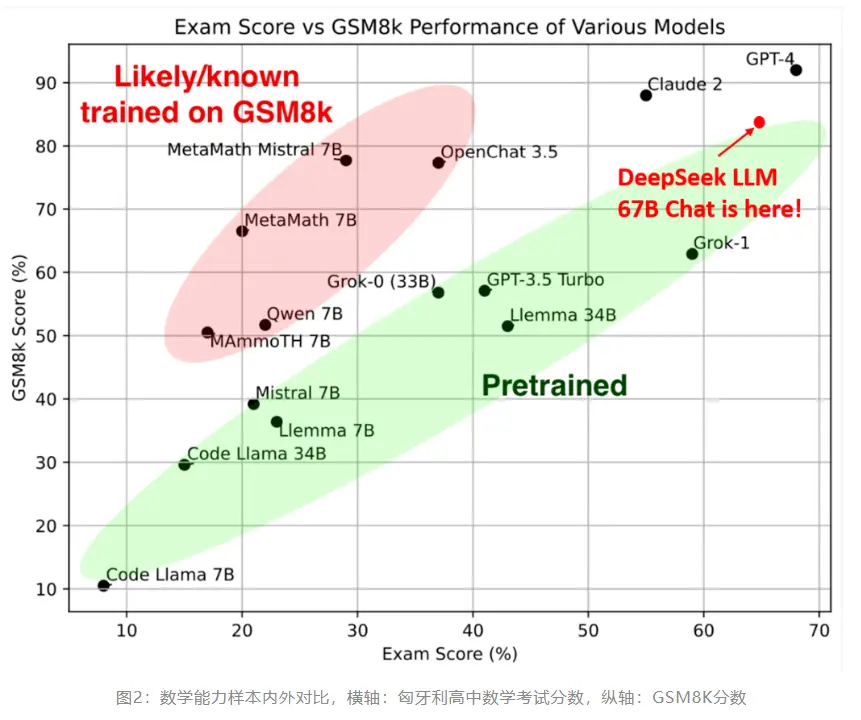
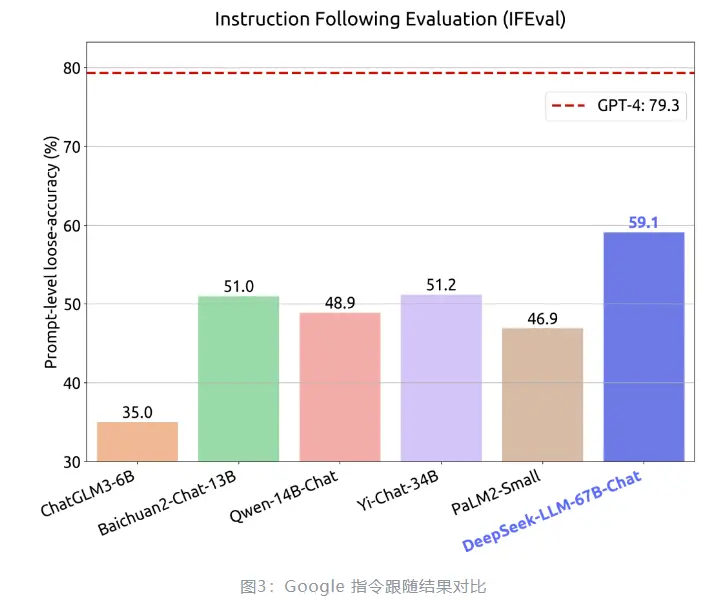
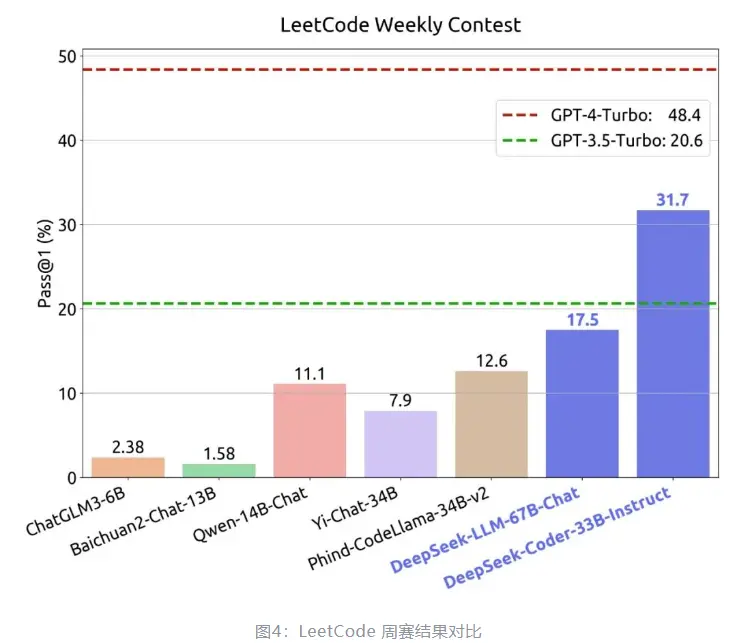
相比开源的同级别模型 LLaMA2 70B,DeepSeek LLM 67B 在近 20 个中英文的公开评测榜单上表现更佳。尤其突出的是推理、数学、编程等能力(如:HumanEval、MATH、CEval、CMMLU)。