多元共进|2023 Google 开发者大会精彩演讲回顾
介绍
Openjob
基于Akka架构的新一代分布式任务调度框架。支持多种定时任务、延时任务、工作流设计,采用无中心化架构,底层使用一致性分片算法,支持无限水平扩容。
- 分布式无状态设计,采用 Master/Worker 架构,支持多样的数据库(H2/MySQL/PostgreSQL/Oracle/TiDB)
- 底层使用一致性分片算法,全程无锁化设计,任务调度精确到秒级别,支持轻量级分布式计算、无限水平扩容。
- 支持分布式定时任务、固定频率任务、高性能秒级任务、一次性任务定时调度。
- 支持单机、广播、Map、MapReduce 和分片多种分布式编程模型,轻松实现大数据分布式计算。
- 基于 Redis 实现高性能延时任务,底层实现任务多级存储,提供丰富的统计和报表。
- 内置工作流调度引擎,支持可视化 DAG 设计,简单高效实现复杂任务调度。
- 完善的用户管理,支持菜单、按钮以及数据权限设置,灵活管理用户权限
- 全面的监控指标,丰富及时的报警方式,便于运维人员快速定位和解决线上问题。
- 原生支持 Java/Go/PHP/Python 多语言 ,以及Spring Boot、Gin、Swoft 等框架集成。
如果您正在寻找一款高性能的分布式任务调度框架,支持定时任务、延时任务、轻量级计算、工作流编排,并且支持多种编程语言,那么
Openjob
肯定是不二之选(
https://github.com/open-job/openjob
)。
更新内容
openjob
1.0.7 新增支持H2/TiDB 数据库,新增秒级任务、固定频率任务、广播任务、分片任务、Map Reduce 轻量计算。
秒级任务
秒级任务,支持1~60秒间隔的秒级延迟调度,即每次任务执行完成后,间隔秒级时间再次触发调度,适用于对实时性要求比较高的业务。
优势
- 高可靠:秒级别任务具有高可靠的特性,如果某台机器宕机,可以在另一台机器上重新运行。
- 丰富的任务类型:秒级别任务属于定时调度类型,可以适用于所有的任务类型和执行方式。

固定频率任务
由于Crontab必须被60整除,如果需要每隔50分钟执行一次调度,则Cron无法支持。
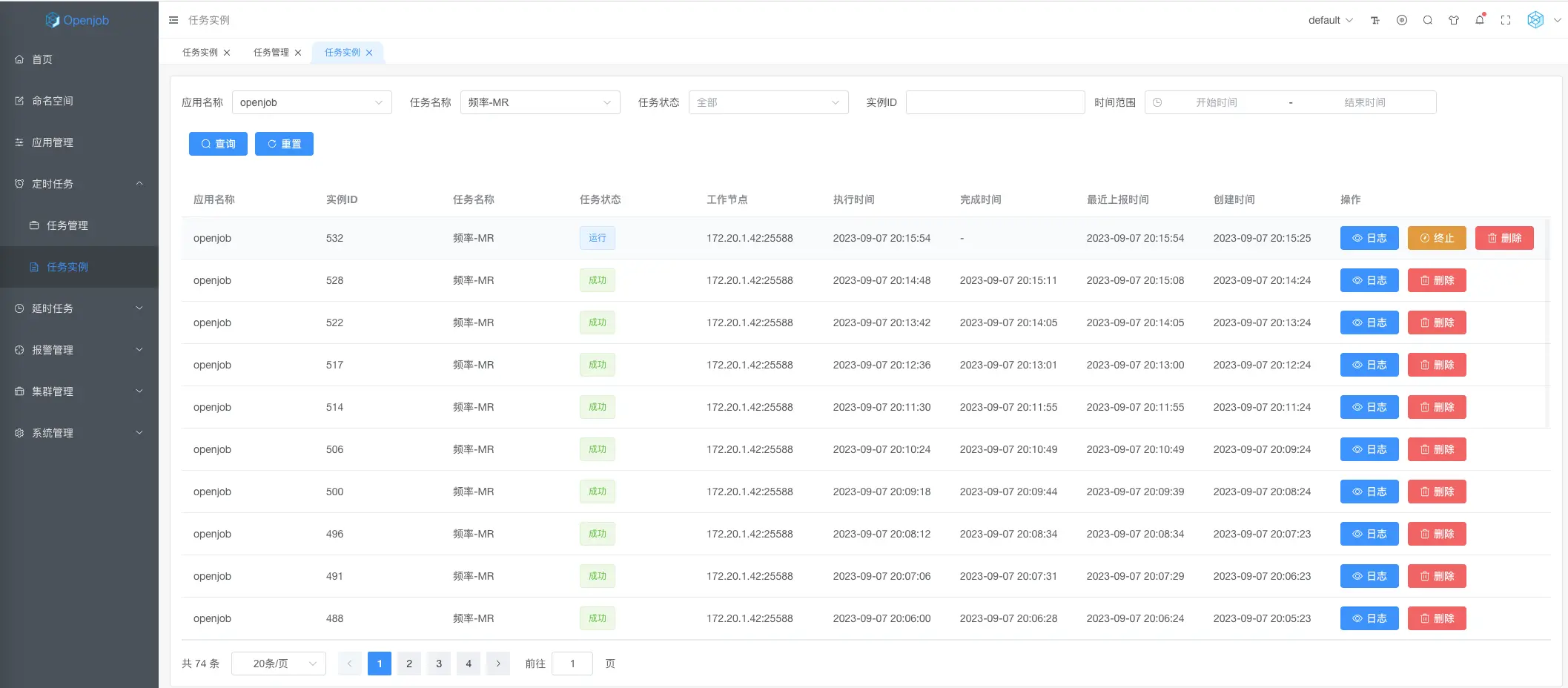
Map Reduce
MapReduce 模型是轻量级分布式跑批任务。通过 MapProcessor 或 MapReduceProcessor 接口实现。相对于传统的大数据跑批(例如Hadoop、Spark等),MapReduce无需将数据导入大数据平台,且无额外存储及计算成本,即可实现秒级别海量数据处理,具有成本低、速度快、编程简单等特性。
/**
* @author stelin [email protected]
* @since 1.0.7
*/
@Component("mapReduceTestProcessor")
public class MapReduceTestProcessor implements MapReduceProcessor {
private static final Logger logger = LoggerFactory.getLogger("openjob");
private static final String TWO_NAME = "TASK_TWO";
private static final String THREE_NAME = "TASK_THREE";
@Override
public ProcessResult process(JobContext context) {
if (context.isRoot()) {
List<MapChildTaskTest> tasks = new ArrayList<>();
for (int i = 1; i < 5; i++) {
tasks.add(new MapChildTaskTest(i));
}
logger.info("Map Reduce root task mapList={}", tasks);
return this.map(tasks, TWO_NAME);
}
if (context.isTask(TWO_NAME)) {
MapChildTaskTest task = (MapChildTaskTest) context.getTask();
List<MapChildTaskTest> tasks = new ArrayList<>();
for (int i = 1; i < task.getId()*2; i++) {
tasks.add(new MapChildTaskTest(i));
}
logger.info("Map Reduce task two mapList={}", tasks);
return this.map(tasks, THREE_NAME);
}
if (context.isTask(THREE_NAME)) {
MapChildTaskTest task = (MapChildTaskTest) context.getTask();
logger.info("Map Reduce task three mapTask={}", task);
return new ProcessResult(true, String.valueOf(task.getId() * 2));
}
return ProcessResult.success();
}
@Override
public ProcessResult reduce(JobContext jobContext) {
List<String> resultList = jobContext.getTaskResultList().stream().map(TaskResult::getResult)
.collect(Collectors.toList());
logger.info("Map Reduce resultList={}", resultList);
return ProcessResult.success();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class MapChildTaskTest {
private Integer id;
}
}
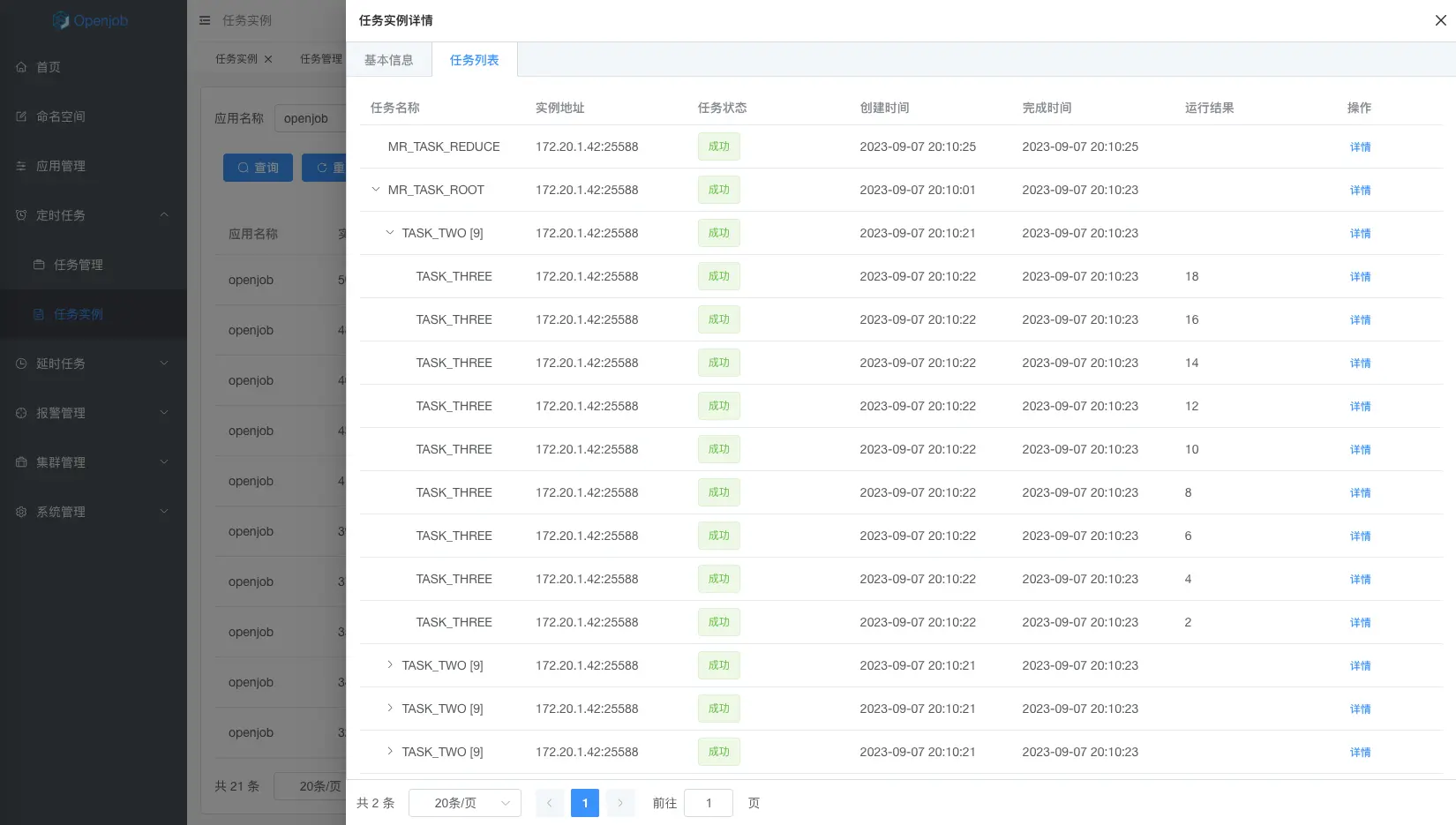
分片任务
分片模型主要包含静态分片和动态分片:
- 静态分片:主要场景是处理固定的分片数,例如分库分表中固定 256 个库,需要若干台机器分布式去处理。
- 动态分片:主要场景是分布式处理未知数据量的数据,例如一张大表在不停变更,需要分布式跑批。此时需要使用 MapReduce 任务
任务特性
- 支持 Java、PHP 、Python、Shell、Go四种语言。
- 高可用:分片任务执行机器异常时,会动态分配到其它正常机器执行任务。
- 流量控制:可以设置单机子任务并发数。例如有 100 个分片,一共 3 台机器,可以控制最多 5 个分片并发执行,其它在队列中等待。
/**
* @author stelin [email protected]
* @since 1.0.7
*/
@Component
public class ShardingAnnotationProcessor {
private static final Logger logger = LoggerFactory.getLogger("openjob");
@Openjob("annotationShardingProcessor")
public ProcessResult shardingProcessor(JobContext jobContext) {
logger.info("Sharding annotation processor execute success! shardingId={} shardingNum={} shardingParams={}",
jobContext.getShardingId(), jobContext.getShardingNum(), jobContext.getShardingParam());
logger.info("jobContext={}", jobContext);
return ProcessResult.success();
}
}
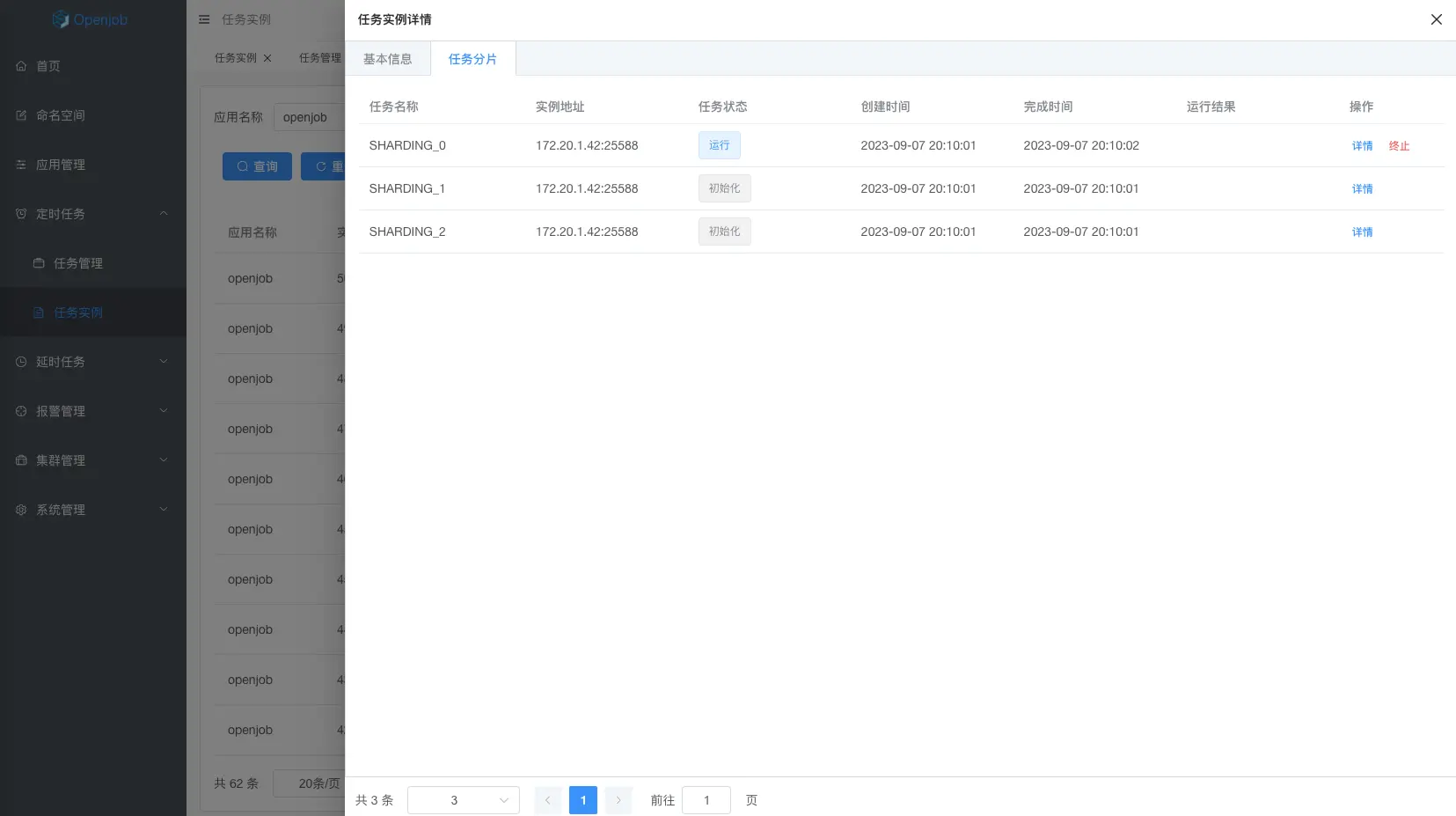
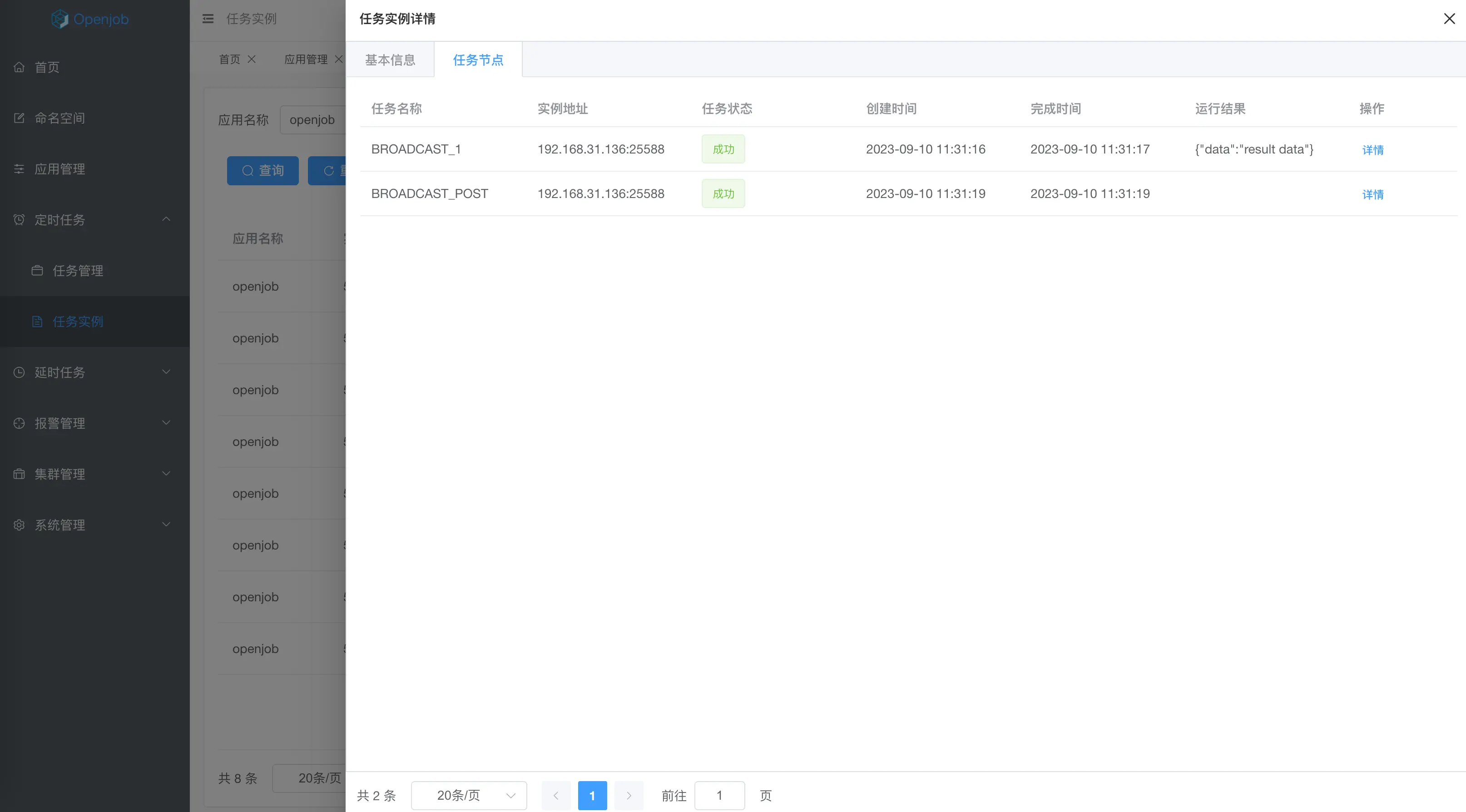
广播任务
广播任务类型的任务实例会广播到应用对应的所有Worker上执行,当所有Worker都执行完成,该任务才算完成,任意一台Worker执行失败,任务就算失败。
应用场景
- 使用JavaProcessor->preProcess 初始化
- 每台机器执行 process 时,根据自己业务返回 result。
- 执行 postProcess,获取所有机器的执行结果做汇总。
任务特性
广播任务类型可以选择多种,例如脚本或者Java任务。如果选择Java,还支持preProcess和postProcess高级特性。
- preProcess 会在每台机器执行 process 之前执行,且只会执行一次。
- postProcess 会在每台机器执行 process 完成且都成功执行之后执行一次,可以返回结果,作为工作流数据传输。
/**
* @author stelin [email protected]
* @since 1.0.7
*/
@Component("broadcastPostProcessor")
public class BroadcastProcessor implements JavaProcessor {
private static final Logger logger = LoggerFactory.getLogger("openjob");
@Override
public void preProcess(JobContext context) {
logger.info("Broadcast pre process!");
}
@Override
public ProcessResult process(JobContext context) throws Exception {
logger.info("Broadcast process!");
return new ProcessResult(true, "{\"data\":\"result data\"}");
}
@Override
public ProcessResult postProcess(JobContext context) {
logger.info("Broadcast post process taskList={}", context.getTaskResultList());
System.out.println(context.getTaskResultList());
return ProcessResult.success();
}
}
更多内容
- Github: https://github.com/open-job/openjob
- 在线体验: https://demo.openjob.io
- 用户名: openjob
- 密码: openjob.io