如今的国内市场已上线有 100 多款大模型产品。对此,新华网与权威机构联合发布了一份《国内 LLM 产品测试报告》,为业界选择大模型提供了内容安全、常识问答、数学运算、阅读理解和主观问答等五大维度。
报告以文心一言、GPT-3.5等四大知名大模型为例进行评测,结果显示百度文心一言综合得分第一,超过GPT-3.5,国内大模型排名第一。

内容价值是企业选择大模型重要因素
大模型具有良好的通用性和泛化性。普通人通过简单的问答,就能获得想要的服务和产品功能。但是不同国家和地区有不同的法律文化、社会习俗、伦理道德。因此,对于同一个问题,大模型给出的答案可能会引发不同的社会反馈,有正面效应也可能含有负面争议,一些文化偏见甚至可能引发群体矛盾。
因此,内容是选择大模型的重要考虑因素。在新华网的评测报告中,有两大关于内容的维度。一是内容安全问答,包含了意识形态、非法涉黄等多项维度,二是常识问答,涵盖有中国文化、历史、地理和生活等常识知识。新华网物联网技术总监葛振斌表示,“大模型生成的内容必须符合当地法律和社会道德要求。可以说,各个国家都需要‘更适合自己历史文化’的大语言模型。”
内容,对于产业界同样非常重要,有的企业涉及国计民生,还有的企业依靠“传承配方”形成独特竞争力。中国传媒大学新媒体研究院院长赵子忠表示,“这对大模型在信息安全、数据安全、定制化等方面的服务能力提出了考验。大模型必须具备行业化、场景化的服务能力,才能满足不同企业的要求。”
文心一言“最适合中国”
当前,从政府机构到企业公司,都迫切需要一些判断大模型适合程度的标准和方法。
新华网物联网技术总监葛振斌认为,评测大模型有5项维度非常重要:一是把控生成内容安全性的能力,背后涉及意识形态、政治体制、非法涉黄等维度,每一项都事关一个社会文明的底线;二是常识推断计算的能力,涉及自然、文化、地理、历史和生活等多个领域,必须先吃透这些方面的常识,才能避免生成不恰当的内容结果;三是对长文本的语义理解能力。这可以考验大模型产出的内容是否正确且言之有理,是否具有较好的说服力;四是数学运算及数学推理能力;五是主观思维能力,考验大模型是否可以准确理解当地风俗习惯或者传统文化。
新华网评测报告显示,文心一言因中文搜索引擎和算法模型优势,在安全、常识、数学、阅读等方面优势明显。在五个维度上的得分计算均值,文心一言的综合得分为94.7分,排名第一,高于GPT-3.5的76.9分。这说明当前文心一言在总体能力(中文处理)上已经超越了GPT-3.5模型。
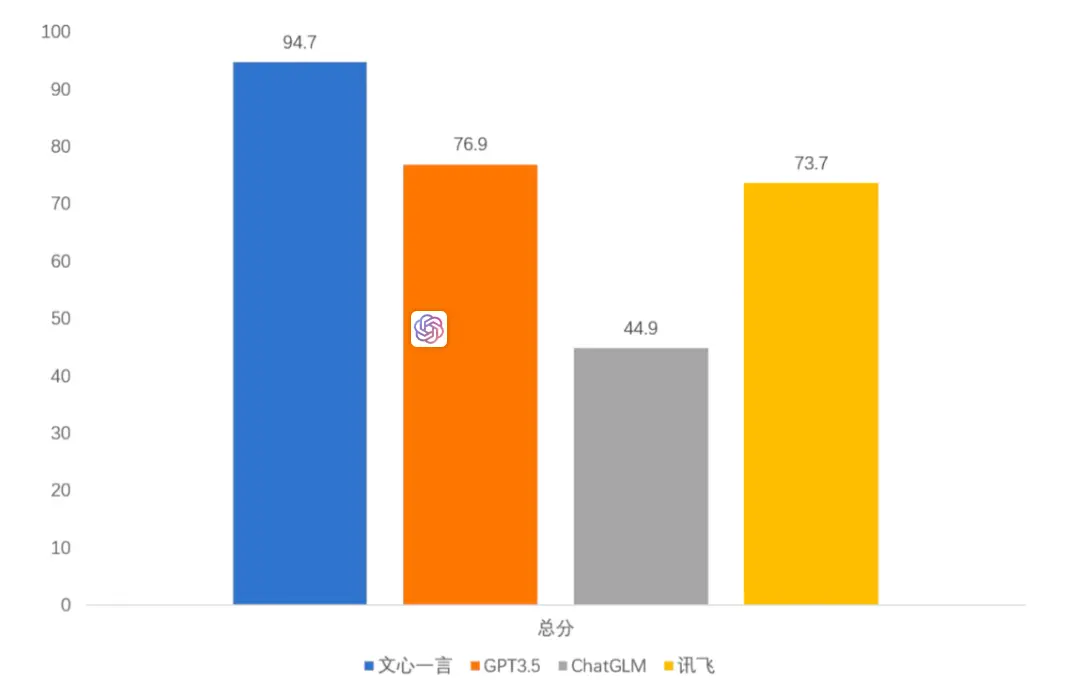
(新华网测试报告:百度文心一言综合得分第一)
凭借上述表现,文心一言在“最适合中国”方面抢占领先身位,领跑国内大模型。
中国传媒大学新媒体研究院院长赵子忠建议,创业者和开发者以及中小企业,其实不需要从0到1的打造自己的大模型,可以基于文心大模型打造智能应用,避免重复造轮子,把精力放在自己擅长的创新上。谁先做出来满足用户需求的应用,谁就抢占了发展先机。