分布式系统大行其道的当前,系统数据的准确性和正确性是重大的挑战,基于 CAP 理论,采用柔性事务,保障系统可用性以及数据的最终一致性成为技术共识 为了保障分布式服务的可用性,服务容错性,服务数据一致性 以及服务间掉用的网络问题。依据 "墨菲定律",增加核心流程重试, 数据核对校验成为提高系统鲁棒性常用的技术方案
特性
- 易用性 业务接入成本小。避免依赖研发人员的技术水平,保障重试的稳定性
- 灵活性 能够动态调整配置,启动 / 停止任务,以及终止运行中的重试数据
- 操作简单 分钟上手,支持 WEB 页面对重试数据 CRUD 操作。
- 数据大盘 实时管控系统重试数据
- 多样化退避策略 Cron、固定间隔、等级触发、随机时间触发
- 容器化部署 服务端支持 docker 容器部署
- 高性能调度平台 支持服务端节点动态扩容和缩容
- 多样化重试类型 支持 ONLY_LOCAL、ONLY_REMOTE、LOCAL_REMOTE 多种重试类型
- 重试数据管理 可以做到重试数据不丢失、重试数据一键回放
- 支持多样化的告警方式 邮箱、企业微信、钉钉、飞书
客户端与服务端数据交互图

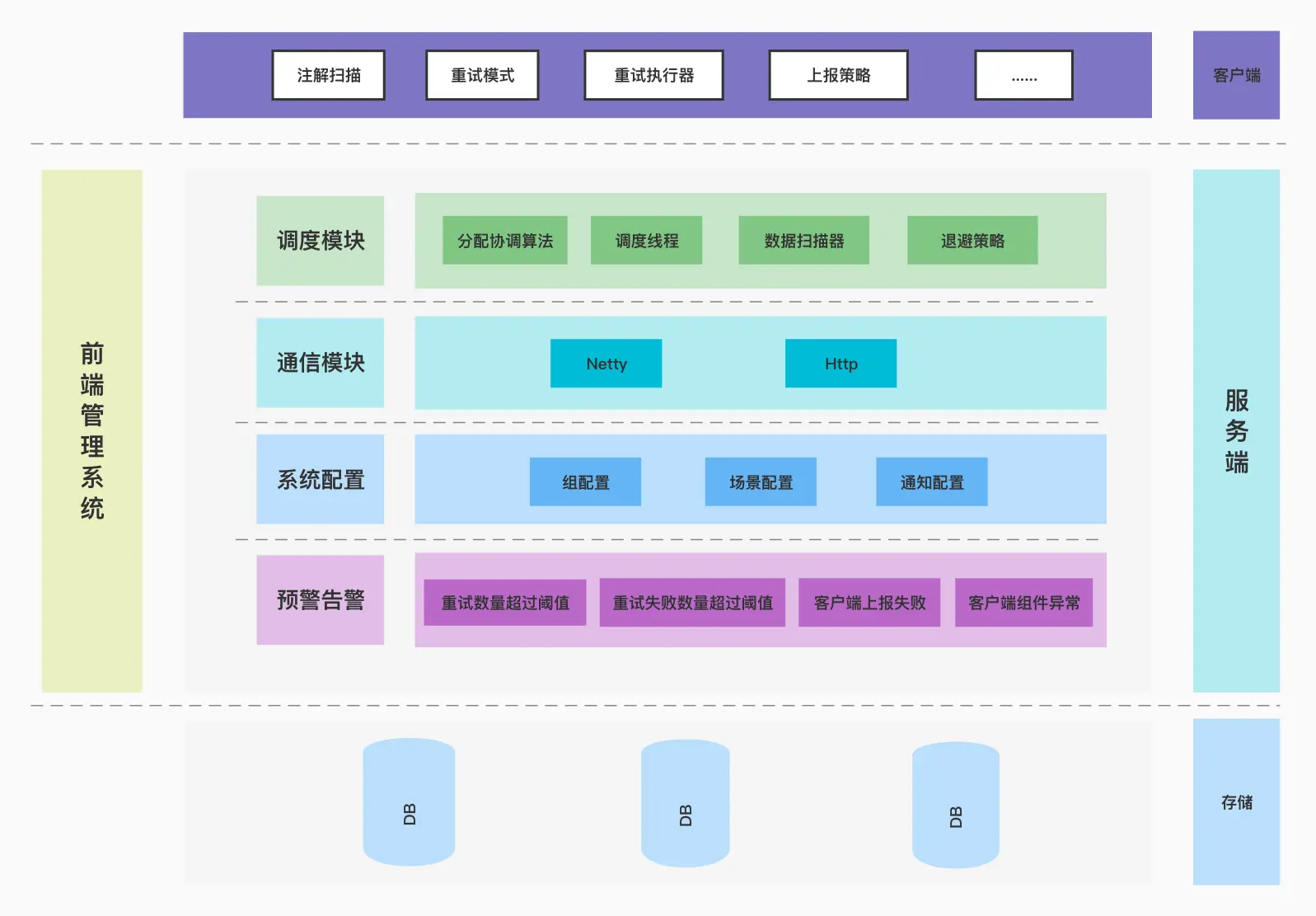
#系统架构图
分布式系统重试的重要性
在分布式系统中,由于网络延迟、节点故障、消息丢失等原因,操作可能会失败。重试机制在分布式系统中显得尤为重要,以下是一些原因:
- 网络不可靠性:在分布式系统中,由于网络的不可靠性,消息可能会丢失或延迟。重试机制可以确保消息被发送和接收,从而提高系统的可靠性和消息传递的可靠性。
- 事务处理:在分布式系统中,事务可能会因为网络延迟等原因失败。重试机制可以确保事务被正确提交,从而保证数据的最终一致性。
- 节点故障:分布式系统可能会由于节点故障而导致部分或全部服务不可用。重试机制可以确保节点重新启动后,服务能够自动恢复并继续运行。
- 提高系统可用性:重试机制可以确保在发生异常情况时,系统能够尝试自动恢复,避免出现系统宕机或无响应的情况,从而提高系统的可用性和稳定性。 重试机制在分布式系统中非常重要,可以提高系统的可靠性、性能和消息传递的可靠性,同时还可以确保数据的一致性和服务的可用性。
重试的风险
- 重试放大风险:这种指数放大的效应很可怕,会加大直接整体系统的负载,最坏情况下被调用的服务流量可能放大到 r 倍,不仅不能请求成功,导致整体的负载继续升高,甚至直接打挂
- 无限重试问题:如果不设置重试次数会使得业务线程一直被重试占用,这样会导致服务的负载线程暴增直至服务宕机.
- 数据安全:基于内存重试会可能造成数据丢失风险
- 网络阻塞:重试次数过多或重试间隔时间过短,就有可能导致大量的请求同时发送,从而导致网络拥塞和负载增加。
v1.1.0 发布内容:
- RetryAspect添加Ordered,支持动态调整Aop执行顺序【新增】
- 手动添加重试任务【新增】
- 更新核心字段描述【更新】
- 更新类名定义【更新】
- 删除重试retry_task_x的biz_id唯一键索引【删除】
- 新增批量删除重试任务数据【新增】
- 新增批量修改重试任务状态和执行器能力【新增】
- 修复管理界面日期显示问题【BUG】
- 停止策略改为责任链模式【更新】
项目地址
官网: https://www.easyretry.com/
gitee:https://gitee.com/aizuda/easy-retry.git
github:https://github.com/aizuda/easy-retry.git
方便的话给项目一个 star,你的支持是我们前进的动力!