陈天奇团队新发布了一个可将大型语言模型和基于 LLM 的聊天机器人引入 Web 浏览器的项目 —— Web LLM。“一切都在浏览器内运行,无需服务器支持,并使用 WebGPU 加速。这开辟了许多有趣的机会,可以为每个人构建 AI 助手,并在享受 GPU 加速的同时实现隐私。”
查看演示网页以进行试用
生成式 AI 和 LLM 方面最近的发展如火如荼,LLaMA、Alpaca、Vicuna 和 Dolly 等相继开源。但这些模型通常很大且计算量很大。要构建聊天服务的话,需要一个大型集群来运行推理服务器,同时客户端向服务器发送请求并检索推理输出,且通常还必须在特定类型的 GPU 上运行。
因此,Web LLM 项目的推出,是“为生态系统带来更多多样性的一步”。具体来说,通过实现将 LLM 直接 bake 到客户端并直接在浏览器中运行,可以为客户个人 AI 模型提供支持,从而降低成本、增强个性化和保护隐私。“如果我们可以简单地打开一个浏览器并直接将 AI 原生地带到你的浏览器选项卡,这不是更令人惊奇吗?生态系统中有一定程度的准备。这个项目为这个问题提供了肯定的答案。”
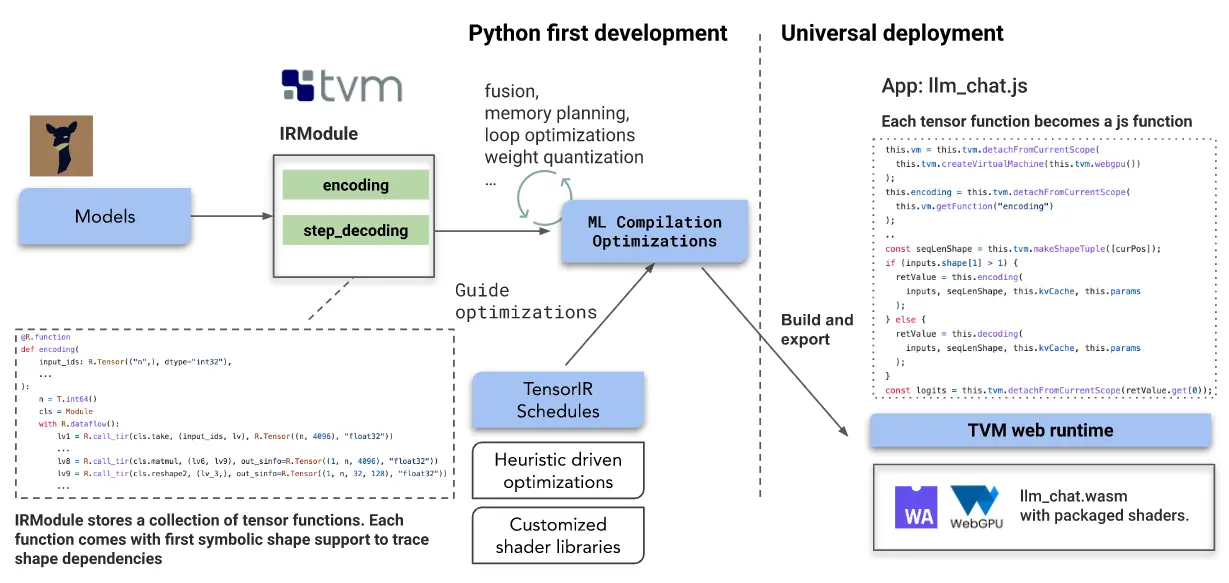
Web LLM 中采用的关键技术是机器学习编译(MLC)。该解决方案建立在开源生态系统的基础上,包括 Hugging Face、来自 LLaMA 和 Vicuna 的模型变体、wasm 和 WebGPU;主要流程则建立在 Apache TVM Unity 之上。
目前,WebGPU 已经发布到 Chrome 并且处于测试阶段,开发团队在 Chrome Canary 中进行了实验。用户也可以试用最新的 Chrome 113,但不支持 Chrome 版本 ≤ 112。Windows 和 Mac 上也已进行了相关的测试,运行的前提条件是一个 6.4G 内存的 GPU。
根据介绍,WebGPU 支持多个后端,除了 Apple Silicon 上的 Metal 之外,它还可以 offloads 到 Vulkan、DirectX 等;这意味着支持 Vulkan 的 Windows 笔记本电脑应该也可以使用。“我配备 AMDGPU 的 2019 年英特尔 MacBook 也能正常工作。当然,还有 NVIDIA GPU!我们的模型是 int4 量化的,大小是 4G,所以也不需要 64GB 的内存。6G 左右的地方应该就足够了。”
不过,Web LLM 团队也坦承该项目还有许多障碍需要跨越,包括在人工智能框架方面摆脱对硬件供应商维护的优化计算库的严重依赖、仔细规划内存使用并压缩权重等。“我们也不想只为一个模型做这件事。相反,我们想提供一个可重复和可破解的工作流程,使任何人都能够以高效的 Python 优先方法轻松开发和优化这些模型,并普遍部署它们,包括在 Web 上。”
除了支持 WebGPU,该项目还为 TVM 支持的其他类型的 GPU 后端(如 CUDA、OpenCL 和 Vulkan)提供了线束。
更多详情可查看官方公告。