Ray 是一个统一的框架,用于扩展人工智能和 Python 应用程序。Ray 由一个核心的分布式运行时和一个用于加速 ML 工作负载的工具包(Ray AIR)组成。
Ray 2.2 正式发布,该版本增强了可观察性、提高了数据密集型人工智能应用的性能、提高了稳定性,并为 RLlib 提供了更好的用户体验。
改善整个 Ray 生态的可观察性
Ray Jobs API 现在是 GA。Ray Jobs API 允许你将本地开发的应用程序提交给远程 Ray Cluster 执行,旨在简化打包、部署和管理 Ray 应用程序的体验。
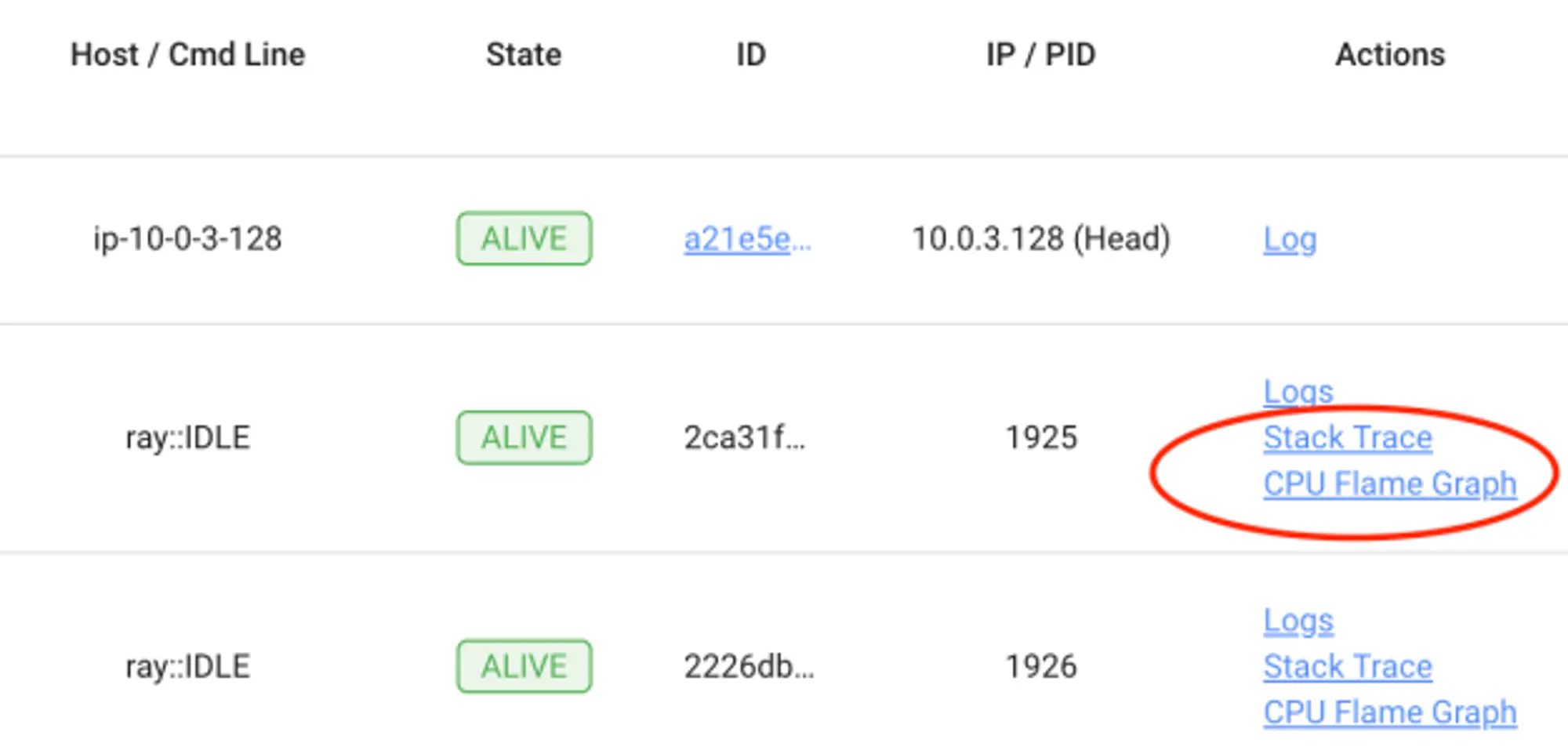
为了观察和衡量 Ray 作业在执行过程中的资源使用情况,Ray 2.2 在 Ray Dashboard 中增加了一些功能,包括可视化 Ray 工作进程的 CPU Flame Graph 和不同内存使用情况的额外指标的功能。
提高数据密集型 AI 应用的性能
在 Ray 2.0版本中,发布了 Ray AI 运行时的测试版。自从测试版发布以来,Ray 团队已经推动了各种性能和可用性的改进,特别是针对数据密集型的 ML 应用。
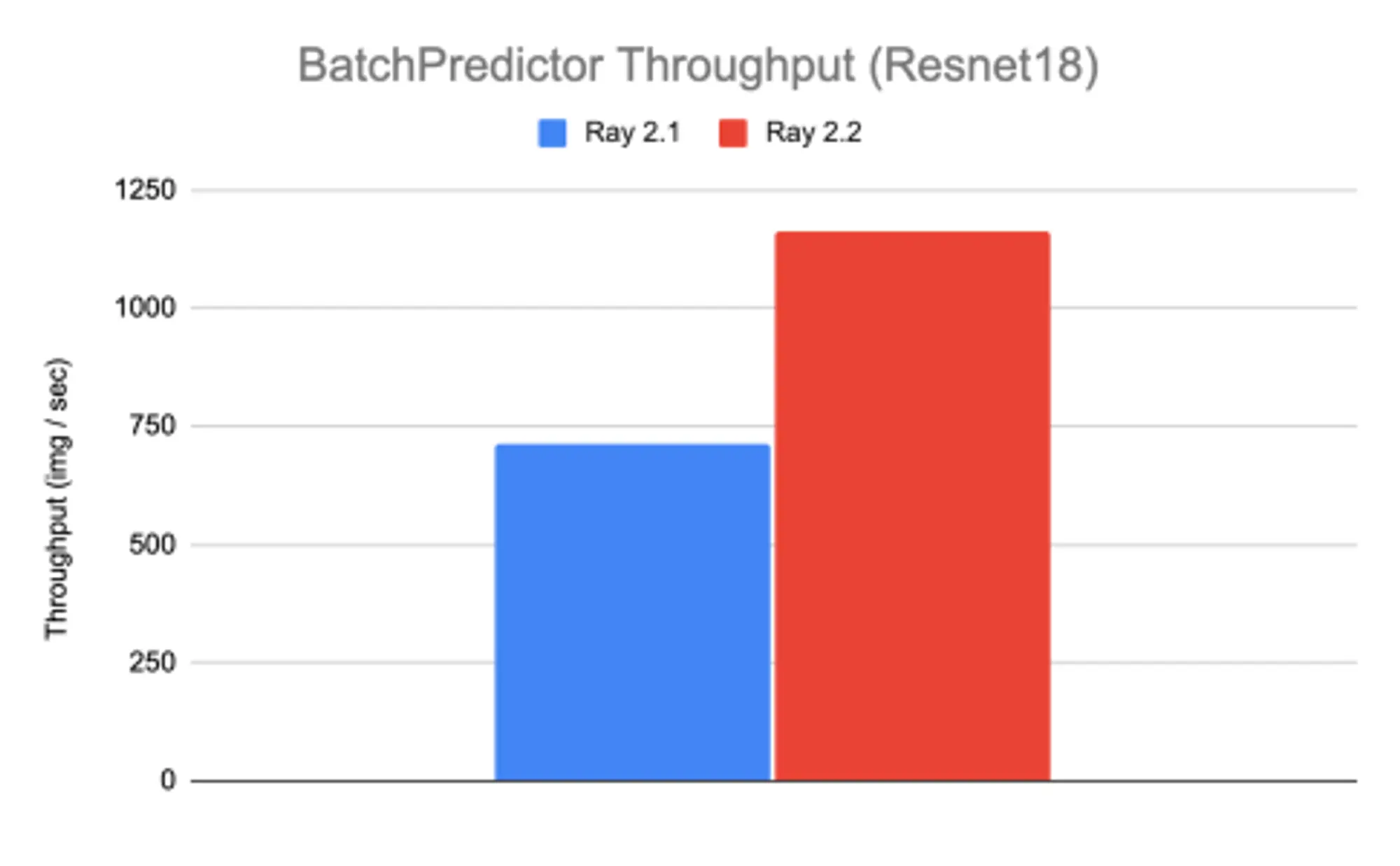
在这个版本中,Ray 团队集中精力通过避免不必要的数据转换来减少深度学习模型批量预测的延迟和内存占用。Ray 2.2 为基于图像的工作负载的批量推理提供了近 50% 的吞吐性能和 100 倍的 GPU 内存占用率的改善。
此外,Ray 团队加强了对 ML 数据生态的支持,包括但不限于扩大与 Apache Arrow 的版本兼容性,为 Ray Data 提供完整的 TensorFlow TF 记录读/写支持,以及 TF 和 Torch 数据集的新连接器方法( from_tf, from_torch)。
针对内存外崩溃的稳定性改进
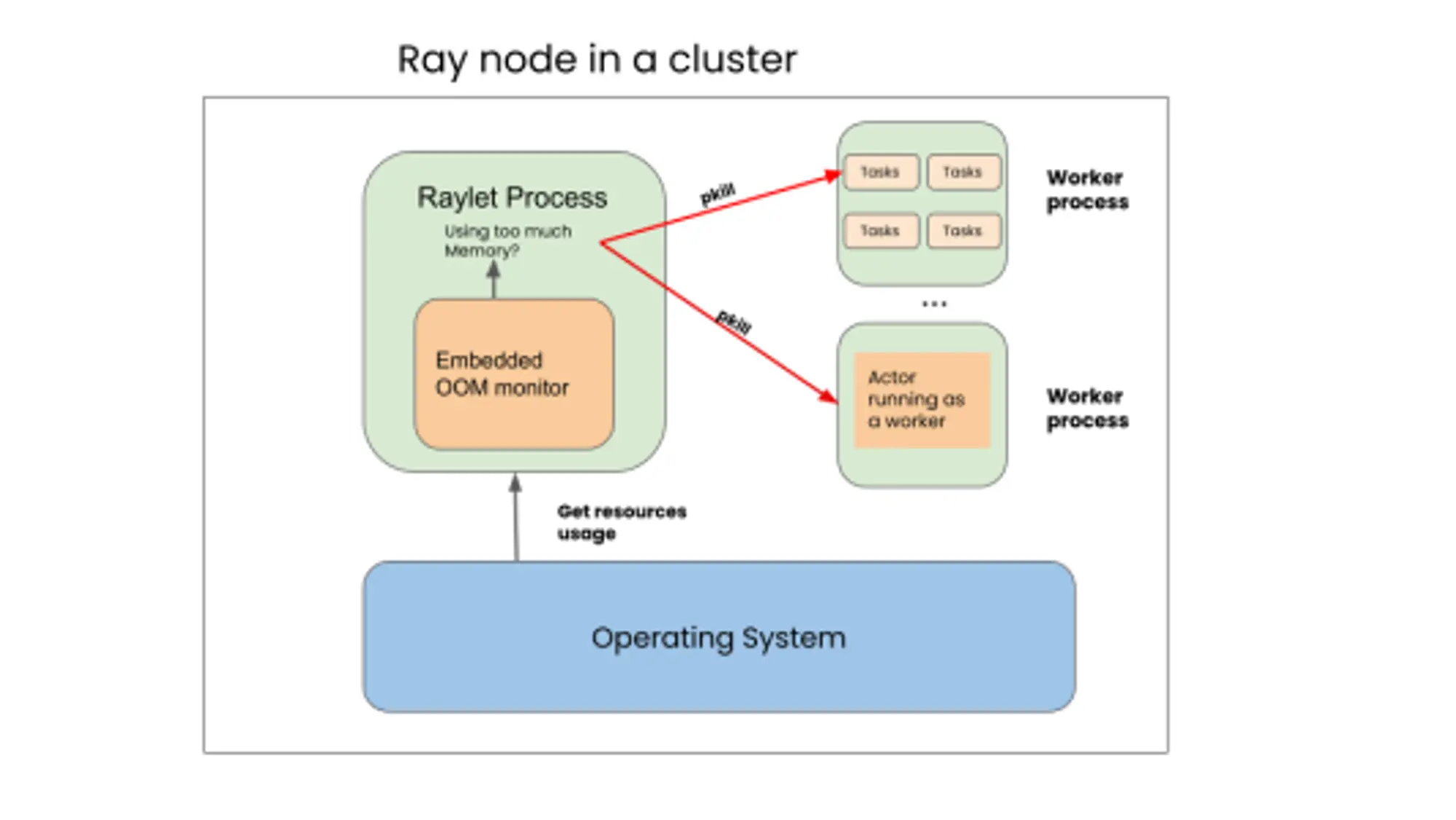
内存不足(OOM)是有害的错误,它不仅扰乱了长期运行的 Ray 应用程序,而且还降低了 Ray 集群中的其他服务。在这个版本中,默认启用了 Ray Out-Of-Memory(OOM)监控器。这个组件定期检查内存使用情况,该监控器使用内存使用统计数据来防御性地释放内存,防止 Ray 完全崩溃。
对于数据密集型的工作负载,Ray 团队听到许多用户报告说,当文件太大,Ray Data 会出现内存不足或性能问题。因此 Ray 2.2 默认启用了动态块分割,这将通过避免在内存中保留过多的数据来解决上述问题。
RLlib API 的增强
RLlib 团队一直在为 RLlib 做一些基本的用户体验改进。Ray 2.2 已经引入了一个增强的 RLlib 命令行界面(CLI),允许自动下载示例配置文件、基于 Python 的配置文件,训练和评估运行之间更好的互操作性。
未来计划
计划在后续的 Ray 版本中进行大量令人兴奋的改进,重点是加强稳定性,提高性能,扩展与更大的 Python 和 ML 生态的集成,以及为 Ray 作业和集群提供可观察性。
更多详情可查看:https://www.anyscale.com/blog/ray-2-2-improved-developer-experience-performance-and-stability