制图: Victoria Slocum
以下为解释
---------------------------
提示工程(Prompt Engineering)已死,上下文工程(𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴) 万岁!
(好吧,也没完全死掉——但它无疑正在进化成一种远为更强大的形态)
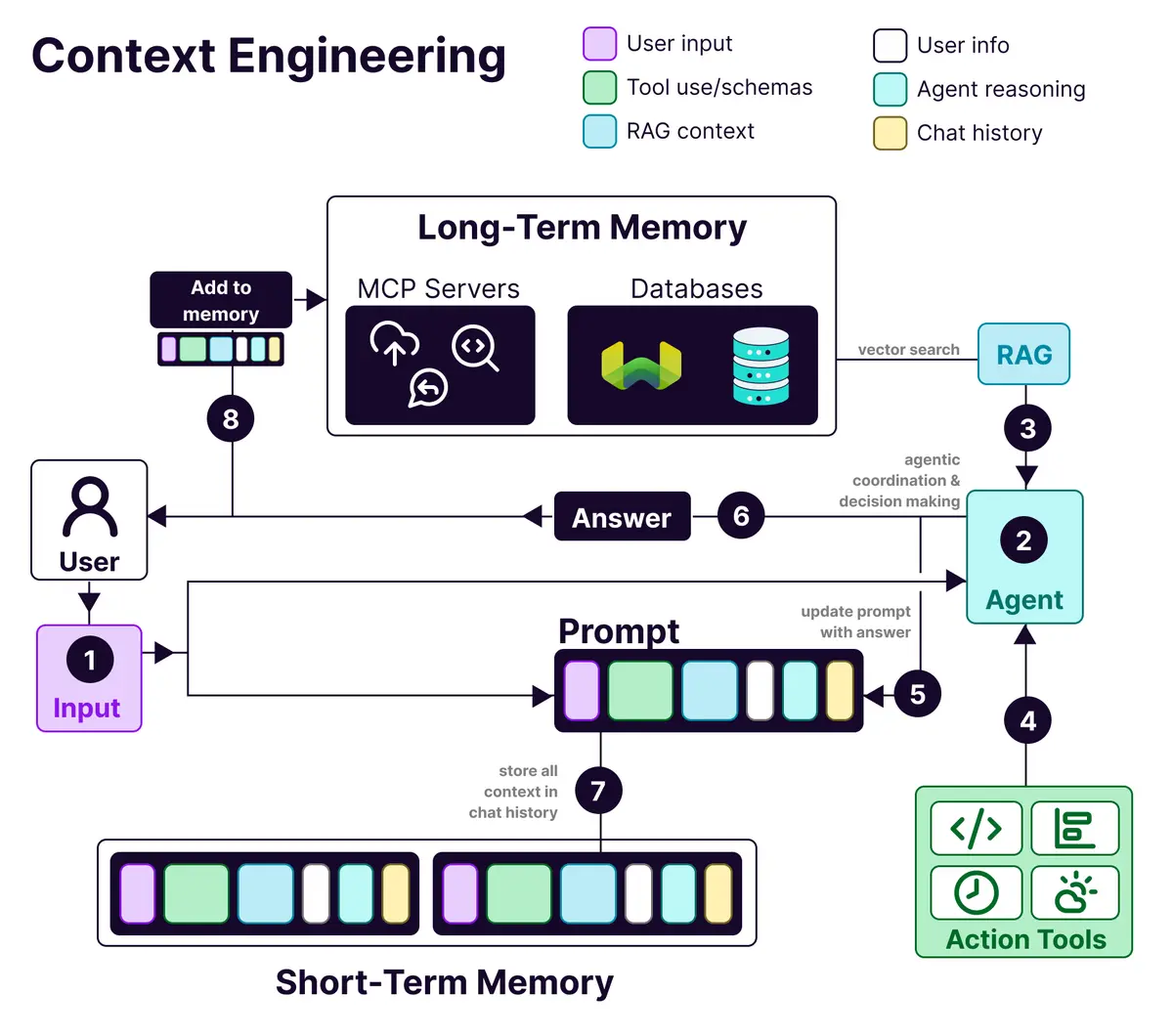
让我们来认识一下上下文工程(𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴)——这是一门艺术,致力于构建动态系统,从而精准地为大语言模型(LLM)提供成功完成任务所需的一切。
随着我们从简单的聊天机器人转向复杂的AI代理(Agent),我们正逐渐意识到,仅仅靠巧妙的提示语是不够的。真正重要的是精心编排一个完整的信息生态系统,并将这些信息输入到你的大语言模型中。
那么,这具体意味着什么呢?
它的核心在于构建动态系统,以正确的格式提供正确的信息和工具,从而让大语言模型能够切实地完成任务。
一个经过上下文工程设计的系统的构成解析:
✨用户信息 (𝗨𝘀𝗲𝗿 𝗜𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻): 偏好、历史记录和个性化数据。
✨工具使用 (𝗧𝗼𝗼𝗹 𝗨𝘀𝗲): API、计算器、搜索引擎——任何大语言模型完成工作所需的工具。
✨RAG上下文 (𝗥𝗔𝗚 𝗖𝗼𝗻𝘁𝗲𝘅𝘁): 从像Weaviate这样的向量数据库中检索出的信息。
✨用户输入 (𝗨𝘀𝗲𝗿 𝗜𝗻𝗽𝘂𝘁): 当前实际的查询或任务。
✨代理推理 (𝗔𝗴𝗲𝗻𝘁 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴): 大语言模型的思考过程和决策链。
✨聊天历史 (𝗖𝗵𝗮𝘁 𝗛𝗶𝘀𝘁𝗼𝗿𝘆): 提供对话连续性的先前交互记录。
那么,它的记忆架构是怎样的呢?
✨短期记忆 (𝗦𝗵𝗼𝗿𝘁-𝘁𝗲𝗿𝗺 𝗺𝗲𝗺𝗼𝗿𝘆): 存在于上下文窗口中,处理当前对话。
✨长期记忆 (𝗟𝗼𝗻𝗴-𝘁𝗲𝗿𝗺 𝗺𝗲𝗺𝗼𝗿𝘆): 存储在向量数据库(如Weaviate)中,跨会话持久化存储用户偏好和过去的交互记录。
这为什么重要?
因为当代理系统(agentic systems)失败时,很少是因为模型本身不够聪明,而是因为我们没有给它提供正确的上下文。
信息的格式同样重要。一条结构清晰的错误信息,永远胜过一大堆杂乱的JSON数据。就像人类一样,大语言模型也需要清晰、易于理解的沟通方式。
转载自:蚁工厂 微博