清华大学与生数科技合作发表论文,提出了一种名为FreeAudio的精准时间可控长时文生音频系统。该系统无需额外训练,即可基于自然语言文本和时间提示,生成超过10秒且时间点精确可控的音频,突破了现有技术普遍存在的10秒时长限制。

https://arxiv.org/abs/2507.08557
FreeAudio系统利用大语言模型(LLM)对时间结构进行规划,将复杂的文本和时间提示解析为一系列不重叠的时间窗口,并为每个窗口生成独立的描述。
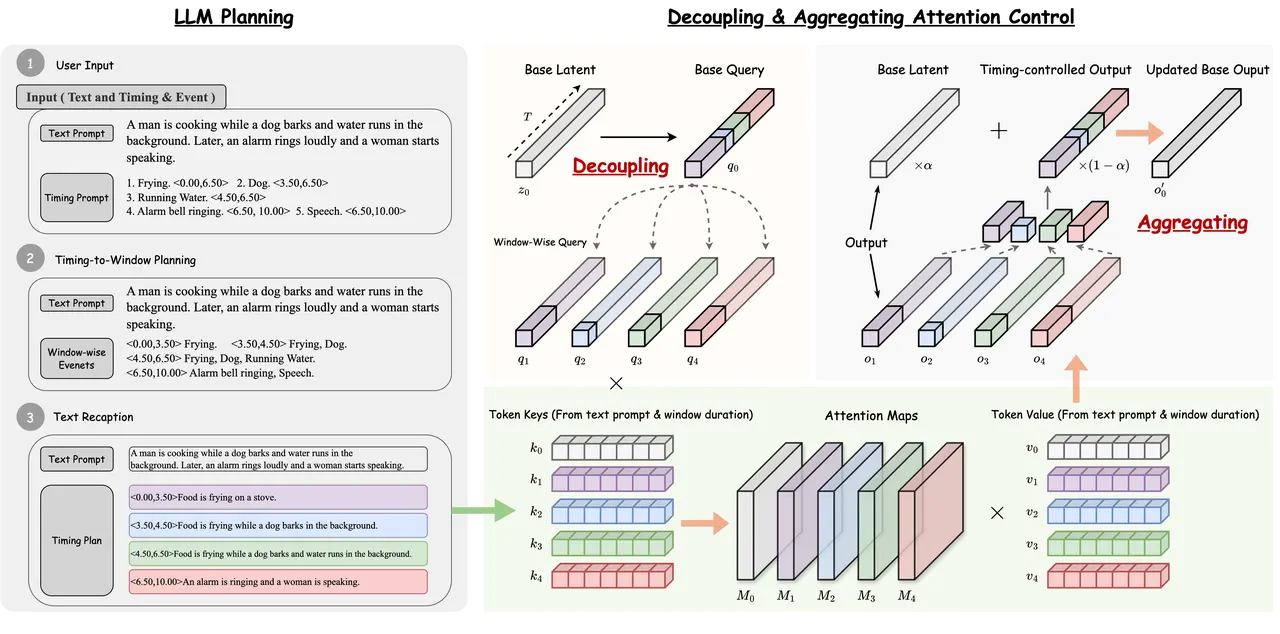
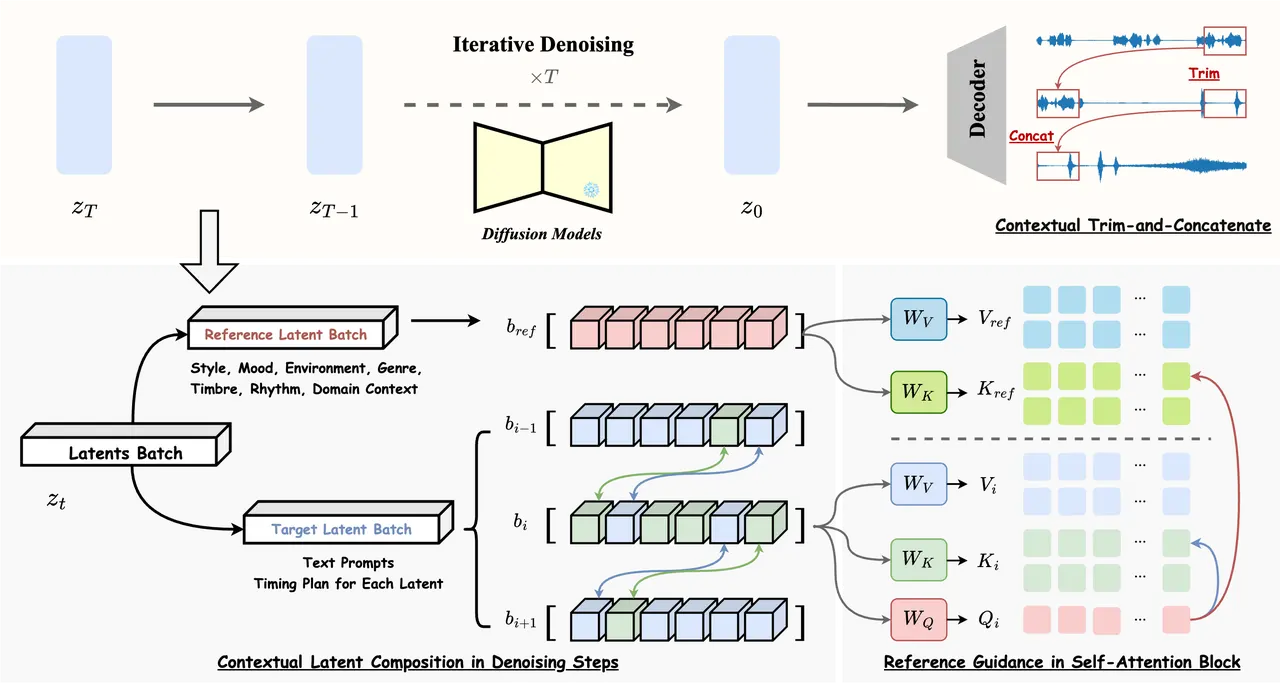
随后,通过“解耦与聚合注意力控制”机制,在DiT-based T2A模型中引导各子段与对应描述对齐。最后,通过上下文潜变量合成、参考引导和上下文修剪与拼接等长时生成优化技术,确保音频片段间的平滑过渡和全局一致性。在AudioCondition测试集上,FreeAudio的事件级和片段级得分均排名第一,并在多项客观和主观评估中表现优异。
该研究成果已被计算机多媒体领域的顶级会议ACM Multimedia 2025录用,并可能在未来应用于生数科技的Vidu产品中。