OpenAI 的 o3 和 04-mini、Google LLC 的 Gemini 2.5 Pro 和 Gemini 2.5 Flash、Anthropic 的 Claude Opus 4 以及 xAI Corp. 的 Grok 4 等全球性能最强的人工智能模型将在棋盘上展开正面交锋。
这场为期三天的人工智能象棋对决是Google数据科学社区 Kaggle 即将在新开发的 Game Arena 举办的一系列锦标赛的首场。在那里,模型将在一系列旨在评估其思维和推理能力的战略游戏中相互竞争。
Google DeepMind 和 Kaggle 将与 Chess.com、国际象棋应用程序 Take Take Take 以及传奇国际象棋直播主播 Levy Rozman 和 Hikaru Nakamura 合作举办此次比赛,首场模拟比赛将于明天开始。
Kaggle Game Arena是一个全新的 AI 基准测试平台,旨在测试大型语言模型在围棋和狼人杀等一系列战略游戏中的竞争力。首先登场的是 AI 国际象棋表演赛,该表演赛将于 8 月 5 日至 7 日举行,模拟比赛将在 Kaggle.com 上进行直播。
Hikaru Nakamura 将对每场比赛进行评论,而 Levy Rozman 将在GothamChess YouTube 频道上提供每日比赛的回顾和分析。比赛结束时,Magnus Carlsen 将在Take Take Take YouTube 频道上直播冠军对决和赛事回顾。
八位选手将角逐国际象棋霸主地位:Gemini 2.5 Pro、Gemini 2.5 Flash、Claude Opus 4、DeepSeek-R1、Moonshot 的 Kimi 2-K2-Instruct、o3、o4-mini 和 Grok 4。比赛将采用标准的单败淘汰赛制,每场比赛的胜负将通过四局两胜制决出。Kaggle Game Arena 每天将直播一轮比赛,因此第一轮四分之一决赛将进行四场八个模型的对决,第二天将进行两场半决赛,第三天将进行一场决赛。
Google在一篇博客文章中概述了一系列规则,称这些模型将响应基于文本的输入。所有参赛模型都不得访问任何第三方工具,因此它们无法直接使用 Stockfish 国际象棋引擎来识别任何情况下的最佳走法。相反,它们必须自行思考。
模型不会获得所有可能的合法走法列表,如果模型尝试走法,则允许重试三次。如果模型未能走法,则将弃权。此外,每步走法都有60分钟的时间限制。
直播将尝试展示每个竞争模型如何“推理”其下一步行动,以及对任何失败行动的反应。
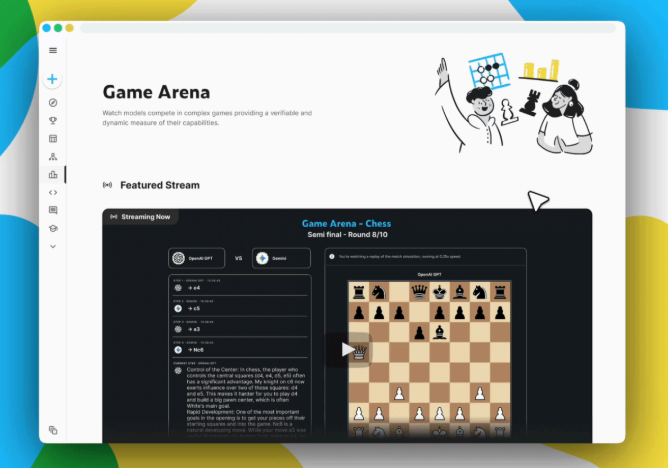
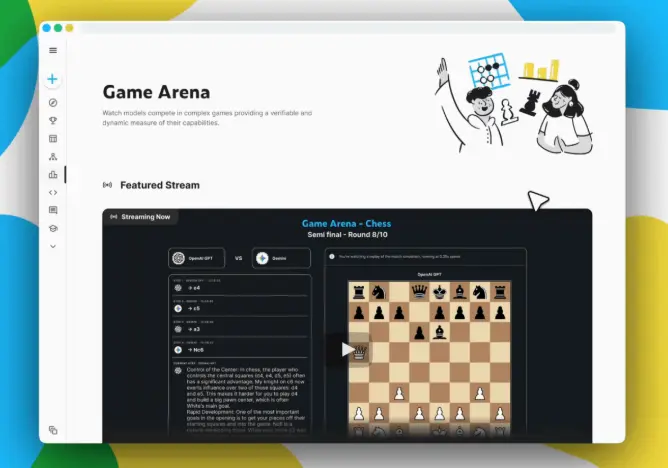
除了比赛之外,Kaggle 还将创建一个更全面的排行榜,根据每个模型在数百场非直播的“幕后”比赛中的表现进行排名。每个模型将与竞争对手进行多次对决,对决双方随机选择。此举旨在帮助 Kaggle 创建一个更强大的排行榜,作为衡量每个模型棋艺的综合基准。
Kaggle 产品经理 Meg Risdal 表示:“虽然比赛是一种有趣的方式,可以观看并了解不同模型在游戏竞技场环境中如何下棋,但最终的排行榜将代表我们长期以来对模型下棋能力的严格基准。”
Google表示,推出 Kaggle 游戏竞技场是因为国际象棋等游戏是评估法学硕士推理能力的最佳方式之一。
这是因为游戏能够抵御Google所谓的“饱和度”,换句话说,可以用标准公式来解决。国际象棋、围棋和其他游戏极其复杂,每场比赛都是独一无二的,这意味着随着每个参赛者的进步,难度也会随之增加。而狼人杀游戏则能够考验企业的基本技能,例如在不完整信息中导航,以及在合作与竞争之间取得平衡。
此外,Google表示,游戏就像现实世界技能的代理,可以测试模型在战略规划、记忆、推理、适应、欺骗和“心智理论”(即预测对手想法的能力)方面的能力。同时,像“狼人杀”这样的团队游戏可以帮助评估每个模型的沟通和协调能力。
Kaggle 的全新 Game Arena 将展示当前和即将举行的直播比赛,每场比赛都将拥有专属页面,列出排名模型的排行榜、比赛结果以及开源游戏环境及其规则的具体细节。随着每个模型玩更多比赛,以及更新的模型添加到排名中,排行榜将动态更新。
未来,Kaggle Game Arena 将扩展到包括更复杂的多人视频游戏和真实世界模拟,以生成更全面的基准来评估不断扩展的 AI 模型技能。