2025 年 5 月 20 日,RWKV 基金会开源了 RWKV7-G1 2.9B 推理模型(Reasoning Model)。
RWKV7-G1 2.9B 具备其它同尺寸模型不具备的推理能力 和任务能力 ,同时还支持现实世界 100+ 种语言。在实际测试中,RWKV7-G1 2.9B 模型能够完成有难度的多语言、数学和代码任务。
RWKV7-G1 2.9B 推理模型基于 World v3.5 数据集训练,包含更多小说、网页、数学、代码和 reasoning 数据,总数据为 5.16T tokens。
快速体验 G1 2.9B :https://huggingface.co/spaces/RWKV-Red-Team/RWKV-LatestSpace
我们也开源发布了 RWKV 模型端聊天 APP,方便大家体验 RWKV-7 G1 模型,APP 下载链接在本文靠后位置。
模型客观指标评测
英语和多语言能力
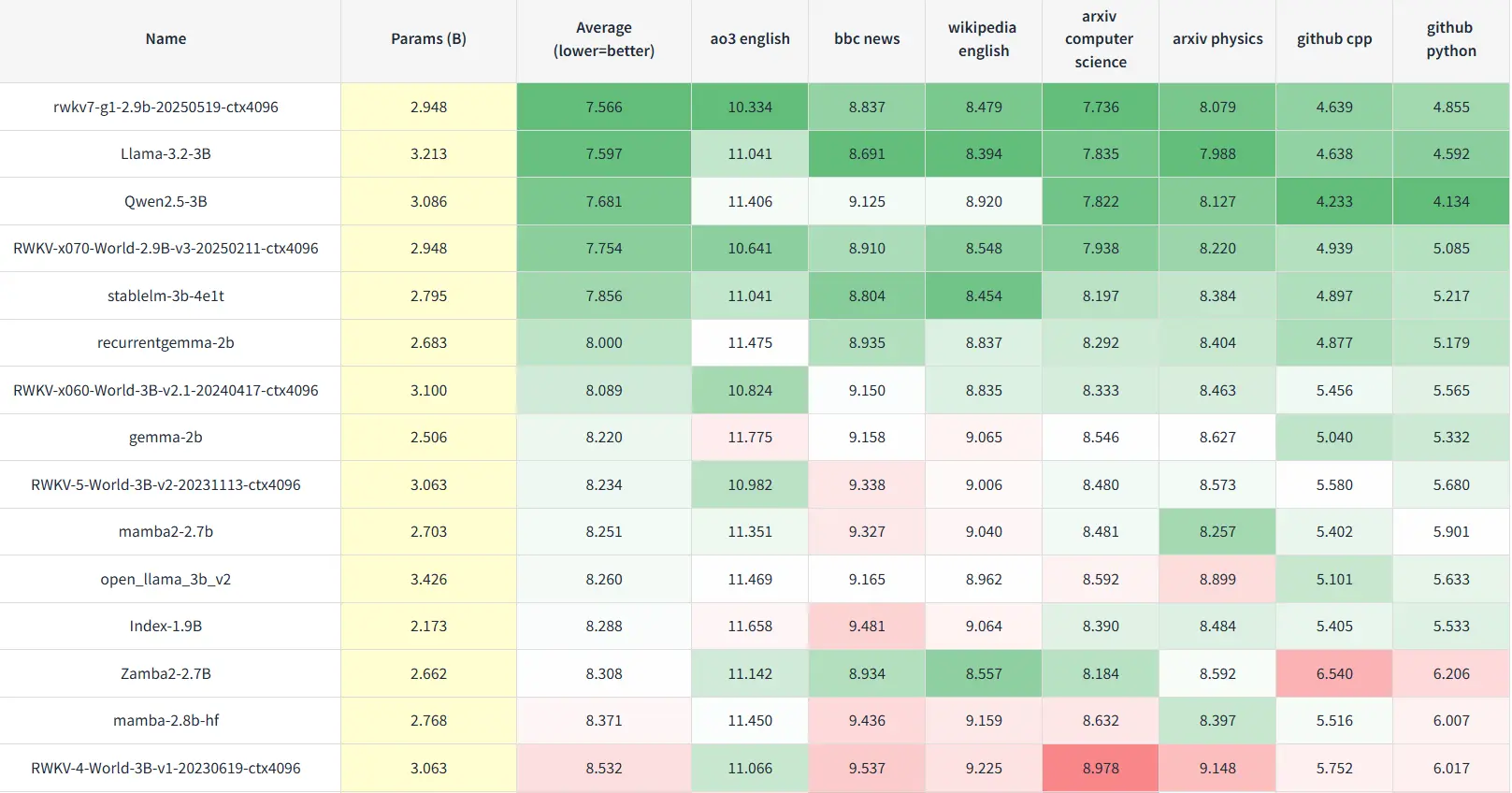
RWKV7-G1 2.9B 的英语和多语言能力显著强于同规模的开源模型:

此外,RWKV7-G1 2.9B 的 MMLU 准确度为 58%,比 RWKV-7 World 3B 的 54.56% 有继续提升。
RWKV-7 World 和 RWKV7 G1 系列均为预训练模型,没有针对任何评测进行数据调优 ,没有使用各类退火技巧 ,也没有做任何 SFT、RLHF 等 post-training。
无法作弊的评测
Uncheatable Eval 是"无法作弊的评测",它使用最新的论文和新闻文章等实时数据,评估开源大语言模型的真实建模能力和泛化能力。
G1 2.9B 的 Uncheatable Eval 综合得分在 3B 参数规模的开源模型中处于领先地位,超越 Qwen2.5 3B、Llama-3.2 3B 等知名模型。
模型使用体验实测
注意以下测试案例均基于 RWKV7 G1 2.9B 基底模型 ,后续我们会做 SFT(监督学习) 和 RL(强化学习) 等 post-training ,会显著增加模型的各种能力。
数学能力测试
我们从 HuggingFaceH4/MATH-500 数据集中选取了部分数学题目测试 RWKV7 G1 2.9B 模型。
MATH-500测试题涵盖以下数学领域:代数基础(Prealgebra)、代数(Algebra)、中级代数(Intermediate Algebra)、微积分预备(Precalculus)、数论(Number Theory)、计数与概率(Counting & Probability)、几何(Geometry),题目难度分为 1~5 共五级。
RWKV7 G1 2.9B 模型可以稳定回答许多难度 3 及以下的题目,最高可以正确回答难度 5 的问题。
数学题目建议把 Top-p和所有 Penalty 解码参数都设为 0。





多语言能力
RWKV7-G1 2.9B 支持全球 100 多种自然语言,比同参数量的 Transformer 模型更强。
下面是 G1 2.9B 把中文诗句"清泉石上流"翻译为小语种的推理过程和翻译结果,翻译结果完全准确:

把中文翻译成其他五种语言:

代码能力
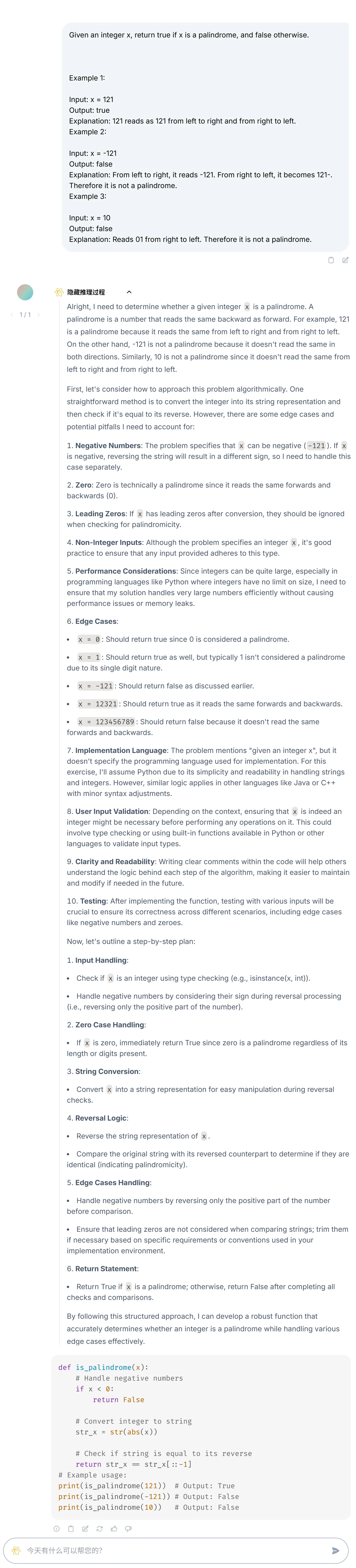
G1 2.9B 拥有良好的代码能力,比如刷 Leetcode Palindrome Number 题目:
或者写一个增强工作效率的脚本:

小说能力
G1 2.9B 直接续写传统小说或网文(使用 RWKV Runner 续写),有较好的网感和文风。
下图中黑色背景是用户输入的前文,其余为模型续写的段落:


常识和日常对话
日常对话或者一些常识问答,准确且干练:




模型试用
我们提供了多个 RWKV-7 模型的在线 demo,也提供移动端聊天 APP。
【推荐】用在线 demo(聊天模式)
为了方便社区体验 RWKV-G1 模型,我们提供了聊天模式的在线 demo。
- Hugging Face:https://huggingface.co/spaces/RWKV-Red-Team/RWKV-LatestSpace
- 魔搭 demo:https://modelscope.cn/studios/RWKV-Red-Team/RWKV-LatestSpace/summary
可在此体验已完成训练的 RWKV7-G1 系列模型。
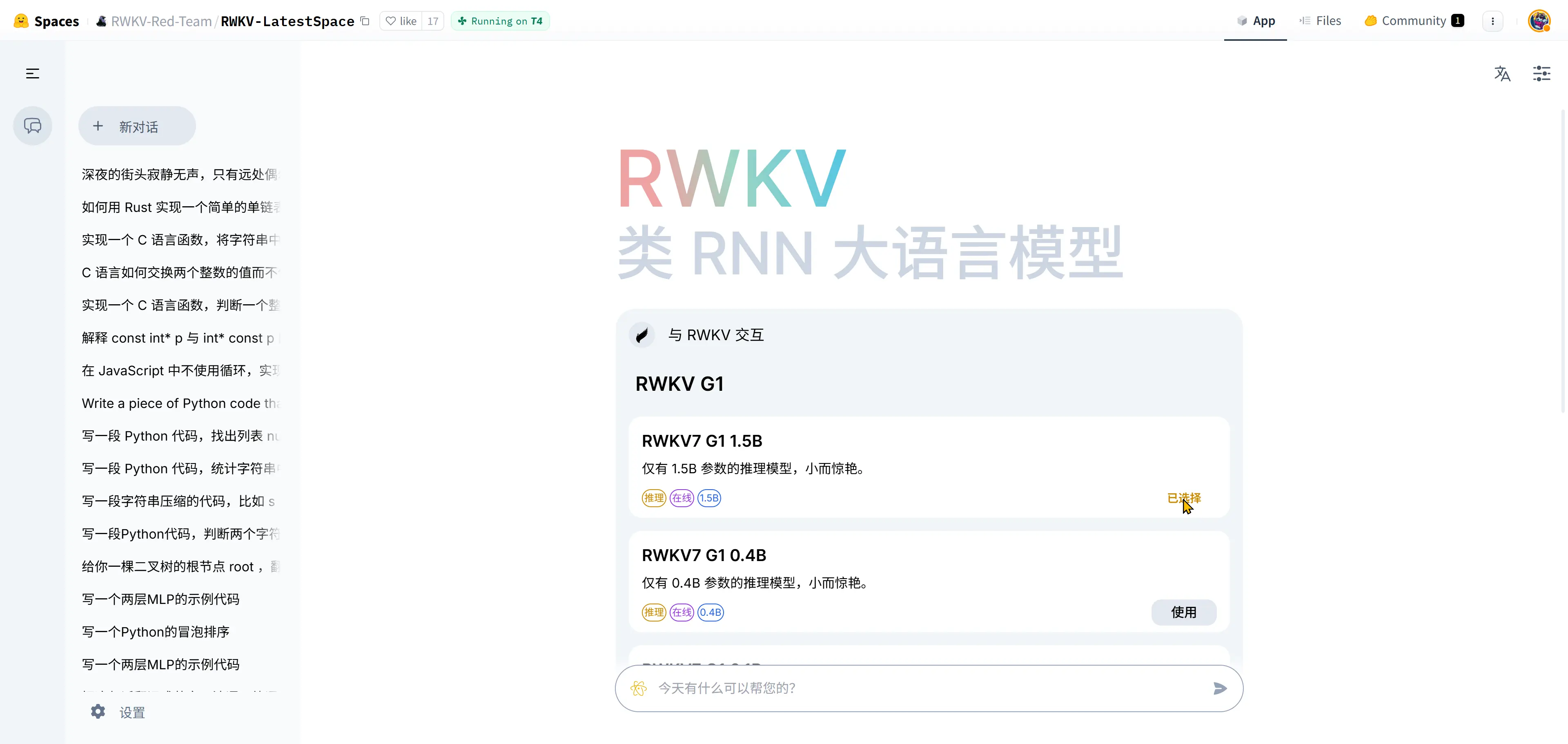
这个精美的 RWKV 对话界面由 RWKV 社区成员 @Leon 开发,并在 GitHub 仓库 web-rwkv-realweb 中开源。
使用在线 demo(续写模式)
可以在 RWKV 官方 Demo 中试用 RWKV7-G1 2.9B 模型:
- **Hugging Face Gradio Demo:**https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
RWKV7-G1 的整体 prompt 格式与 RWKV-7-World 模型类似,可选使用 <think> 标签开启 reasoning 功能:
User: 我可以抽干太平洋的水然后下去抓鱼吗?
Assistant: <think>
使用 RWKV 端侧聊天 APP
我们也开发了处于内测阶段的 RWKV 端侧聊天 APP(Android 和 iOS 版本),可在下列地址下载 APP:
- Android : https://www.pgyer.com/rwkvchat
- iOS (TestFlight) : https://testflight.apple.com/join/DaMqCNKh
贯彻开源开放的宗旨,RWKV 端侧聊天 APP 也已开源 ,在 GitHub rwkv_mobile_flutter 仓库中可以看到项目代码。
模型下载
下载已完成训练的 RWKV7-G1 模型:
- Hugging Face:https://huggingface.co/BlinkDL/rwkv7-g1/tree/main
- 魔搭社区:https://modelscope.cn/models/RWKV/rwkv7-g1/files
- WiseModel:https://wisemodel.cn/models/rwkv4fun/RWKV-7-G1/file
G1 7B 模型进度
我们已经准备更大更优的数据集 World v3.7,正在基于 World v3.7 数据集训练 RWKV7-G1 7B 模型。
加入 RWKV 社区
欢迎大家加入 RWKV 社区,可以从 RWKV 中文官网了解 RWKV 模型,也可以加入 RWKV 论坛、QQ 频道和 QQ 群聊,一起探讨 RWKV 模型。
- 📖 RWKV 中文文档:https://www.rwkv.cn
- 💬 RWKV 论坛:https://community.rwkv.cn/
- 🐧 QQ 频道:https://pd.qq.com/s/9n21eravc
- 📺 BiliBili 视频教程:https://space.bilibili.com/3546689096910933
欢迎大家基于 RWKV-7 进行创业、科研,我们也会为基于 RWKV 的项目提供技术支持。
如果您的团队正在基于 RWKV 创业或开展研究,请联系我们!(在"RWKV元始智能"微信公众号留言您的联系方式,或发送邮件到"[email protected]"。)