与其阻止爬虫机器人,不如主动把它们引进一个由AI生成的「废话迷宫」,让它们自我迷失。
Cloudflare近日推出名为「AI迷宫」(AI Labyrinth)的新工具,用以对付未经授权、到处抓取网页数据的爬虫机器人。这些爬虫通常抓取免费内容,以训练AI模型。

Cloudflare介绍称,当系统识别到异常爬虫行为时,「AI迷宫」就会启动,将这些机器人引向由AI自动生成的虚假页面。这些页面毫无实际价值,仅用于消耗机器人的时间与资源,令其陷入困惑,最终无法获取有效数据。
过去,网站管理员常用「robots.txt」文件引导机器人避开特定页面。但一些AI公司,例如Anthropic、Perplexity AI等,屡次被指控忽视这种协议,擅自抓取数据,导致网站与机器人之间形成技术上的持续对抗。
Cloudflare表示,每日大约有500亿次爬虫访问请求。尽管已开发多种拦截工具,但爬虫总能迅速适应并绕过防御措施。这次Cloudflare转变策略,不再直接拦截,而是通过生成迷宫般的虚假页面,让机器人陷入无用信息的循环,主动消耗自身的资源。
这种方法也被称作“下一代蜜罐陷阱”(Honeypot)。人类用户可以轻松识别并避免点击这些无价值链接,而机器人则毫无辨别能力,会持续抓取陷阱页面,越陷越深。Cloudflare由此可记录并分析机器人行为,快速识别新的爬虫模式,并不断优化防御措施。
据介绍,AI迷宫利用Workers AI和开源模型生成各种主题的独特HTML页面。Cloudflare并非按需生成内容,而是预先生成并筛选内容,确保其不存在XSS漏洞,并将其存储在R2中以加快检索速度。每个生成的页面都包含适当的元指令,以防止搜索引擎索引,从而保护合法的SEO工作。

这些Nofollow标签确保不遵守推荐指南的AI爬虫将被困在迷宫中,而遵守规则的爬虫则会安全地忽略蜜罐。重要的是,这些链接通过精心实现的属性和样式对普通访客不可见。除了保护网站内容外,AI迷宫还作为一种复杂的识别机制。当这些隐藏链接被点击时,Cloudflare可以自信地识别出自动化爬虫活动,并将这些宝贵的数据输入机器学习模型,以增强爬虫检测能力。这形成了一个有益的反馈循环,每次爬取尝试都有助于保护所有Cloudflare客户。
Cloudflare强调,为防止误导公众,这些生成的虚假内容虽基于真实科学事实,但与目标网站毫无关系,因此对爬虫训练AI模型毫无价值。
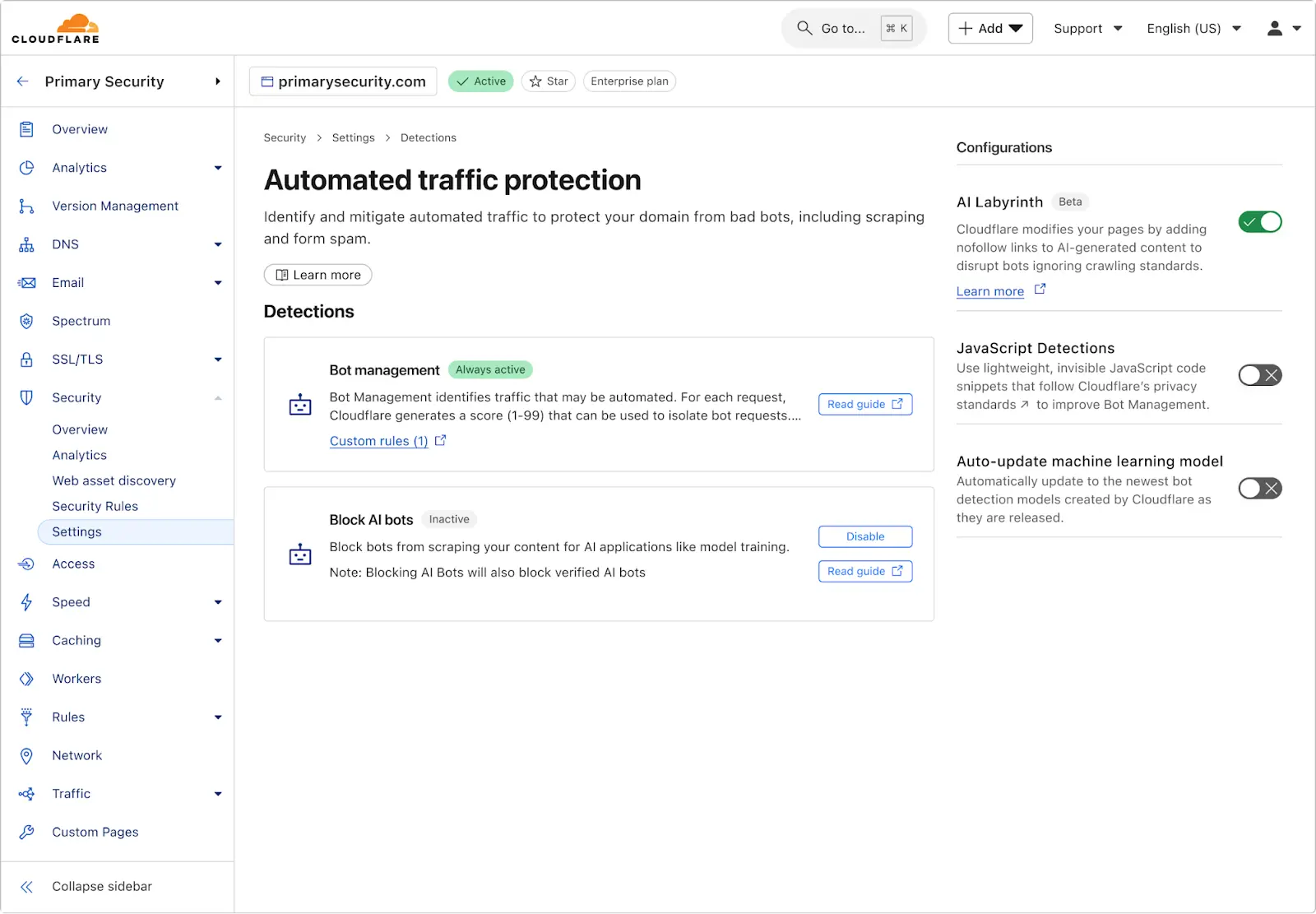
管理员只需在Cloudflare后台“机器人管理”界面启用该工具,即可简单使用。未来,Cloudflare还计划构建更加复杂庞大的虚假页面网络,使恶意爬虫彻底迷失其中,进一步加大爬虫成本与困难度。