Katalyst 是字节跳动对多年大规模业务云原生化场景中资源管理能力的抽象和总结,我们期望通过 Katalyst 的开源直接或间接的帮助用户做好资源管理,实现降本增效。
当下互联网应用以天为单位,在线业务的资源使用情况往往会随着访问数量的波动而变化,具备明显的潮汐特性。为了确保业务稳定性,业务方往往会参考高峰时段的资源使用情况来申请资源,但这部分资源在低峰时段容易被闲置。
如果可以把这些闲置资源暂时出让给优先级低的服务,当在线业务需要使用的时候及时将资源归还,形成在离线服务混部,就可以达到削峰填谷,节约成本#的效果。
字节跳动云原生混部实践
字节跳动业务规模庞大、业务类型多元,其中涵盖了包括微服务、推广搜服务、机器学习与大数据、存储在内的多种业务类型。通常来说,不同业务类型对底层基础设施会有不同的资源管理诉求,传统的管理模式是基于业务线或者服务类型切分资源池,实现定制化需求。
但切分资源池的做法容易形成资源孤岛,无法实现资源层面的灵活拆借,不利于全局资源利用效率的提升和业务成本的优化,加重集群运维的负担。
此外,由于不同类型业务的 SLO 要求、资源潮汐特性存在互补,基础设施团队期望充分利用这些特性,通过调度和管控等手段去优化资源效率,实现资源池的融合统一,帮助业务团队获得更低的资源成本和更强的弹性能力。

为实现资源统一托管,字节跳动从 2016 年就开始基于 Kubernetes 构建统一的基础设施。
到现阶段,字节内部已经基本完成全量微服务、推广搜服务以及大部分机器学习与大数据业务的云原生化改造。在此过程中,基础架构团队持续探索统一资源池下的资源优化手段,并逐渐形成了 “弹性伸缩” 和 “常态混部” 互相配合的资源池混部方案。
-
弹性伸缩:实现机器级别、Numa 级别的资源分时复用,结合业务指标和系统指标,共同指导业务实例的横向和纵向扩缩容策略,最终使得离线类服务以更加低廉的价格购买更多闲时资源,在线类服务以更加高昂的价格购买更多峰时资源,通过资源市场化运营的方式实现综合效率的提升。
-
混合部署:提供资源超卖的能力,充分利用集群中 “已经售卖但未充分使用的资源” 部署更多低优业务,同时在系统侧完善 CPU、内存、磁盘、网络等多维度的资源隔离机制,并且智能预测、感知各类服务的负载变化,结合服务的分级机制,通过分钟级的指标感知和调控策略,保证服务的稳定性。
该方案在链路上基于 Kubernetes 和 Yarn 两套体系实现联合管控,在单机上同时运行 Kubernetes 和Yarn的管控组件,配合中心协调组件对两套系统可见的资源量进行分配。在联合管控系统之上,团队基于服务资源画像实现实时的资源预估,在保证各类服务 SLA 要求的前提下,实现更加灵活和动态的资源分配。
在该资源池混部方案落地实践的过程中,基础设施团队完成了资源并池可行性的验证,完成了混部基础能力的构建,并且在部分核心业务集群实现了整机天级利用率从 23% 到 60% 的提升。
Katalyst:从内部验证到开源
在经历内部抖音、今日头条等大规模潮汐流量业务验证后,字节跳动的云原生混部实践已日臻完善。
为了帮助更多人了解大规模资源混部实践的工作原理,方便更多开发者用户体验这种开箱即用、一键式部署的资源管控能力,研发团队决定回馈社区,采用 Kubernetes Native 的方式重构并增强了资源管控系统的实现,提炼出资源管控系统 Katalyst 并正式开源。
Katalyst 引申自单词 catalyst (音 [ˈkætəlɪst]),本意为催化剂。首字母修改为 K,寓意该系统能够为所有运行在 Kubernetes 体系中的负载提供更加强劲的自动化资源管理能力。
什么是 Katalyst
Katalyst 脱胎于字节跳动混部技术实践,同时也从资源、管控、调度等多个维度对资源管控能力进行了扩展和补充。它的主要特点包括:
- 完全孵化于超大规模混部实践,并在字节服务云原生化的进程中同步接管资源管控链路,真正实现内外技术体系的复用
- 搭载字节跳动内部的 Kubernetes 发行版 Enhanced Kubernetes同步开源,兼容性好,体验更多字节自研的核心功能
- 系统基于插件化模式构建,用户可以在 Katalyst Framework 之上自定制各类调度、管控、策略、数据等模块插件
- 提供一键式部署模版和详尽运维手册,降低外部用户的理解和接入使用成本
Katalyst 如何实现资源抽象
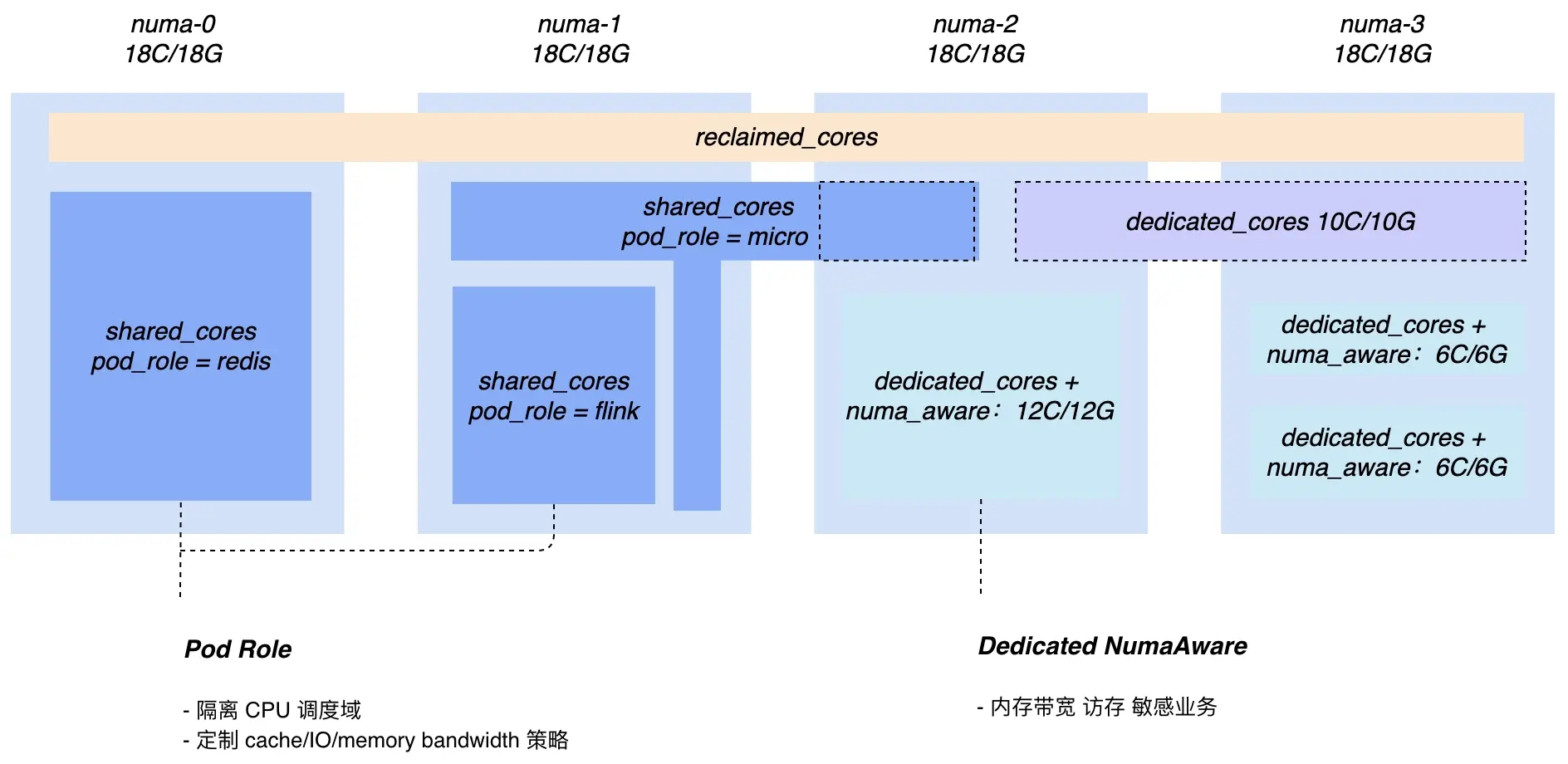
在资源层,Kubernetes 原生 QoS 分级无法满足大规模生产环境的要求,Katalyst 在此基础上进行了进一步的抽象。
Katalyst 以 CPU 为主维度,为应用提供了 system_core 系统核、dedicated_core 独占核、shared_core 共享核、reclaimed_core 回收核等多种不同等级,同时每种等级又辅助以多种 enhancement 机制(例如是否需要 numa node 绑定,是否需要网卡亲和或者带宽限制等),实现差异化的资源分配和管控策略。

通过抽象资源模型,Katalyst 为用户提供了统一的资源入口,用户根据实际业务需求,将业务服务映射到对应的 QoS 和售卖模式上准确地表达自身的需求,最终实现从统一的资源池获取资源而不用关注底层资源池细节。
Katalyst 的架构设计
早期的混部架构存在几方面的问题:Kubernetes 和 Yarn 两套系统的联合管控虽然实现了在离线业务的常态混部,但是复杂的系统也使得维护成本变高。
另外这种架构也带来了额外的资源损耗,这些损耗一方面来自于联合管控模式下单机 Agent 组件资源占用,尤其在超大规模的集群中,这部分资源非常可观。此外,由于两套管控导致系统复杂度变高,系统交互过程中会产生多级资源漏斗,任何环节的异常都会导致资源丢失。
在 Katalyst 中,我们对整体的混部架构做了优化重构:
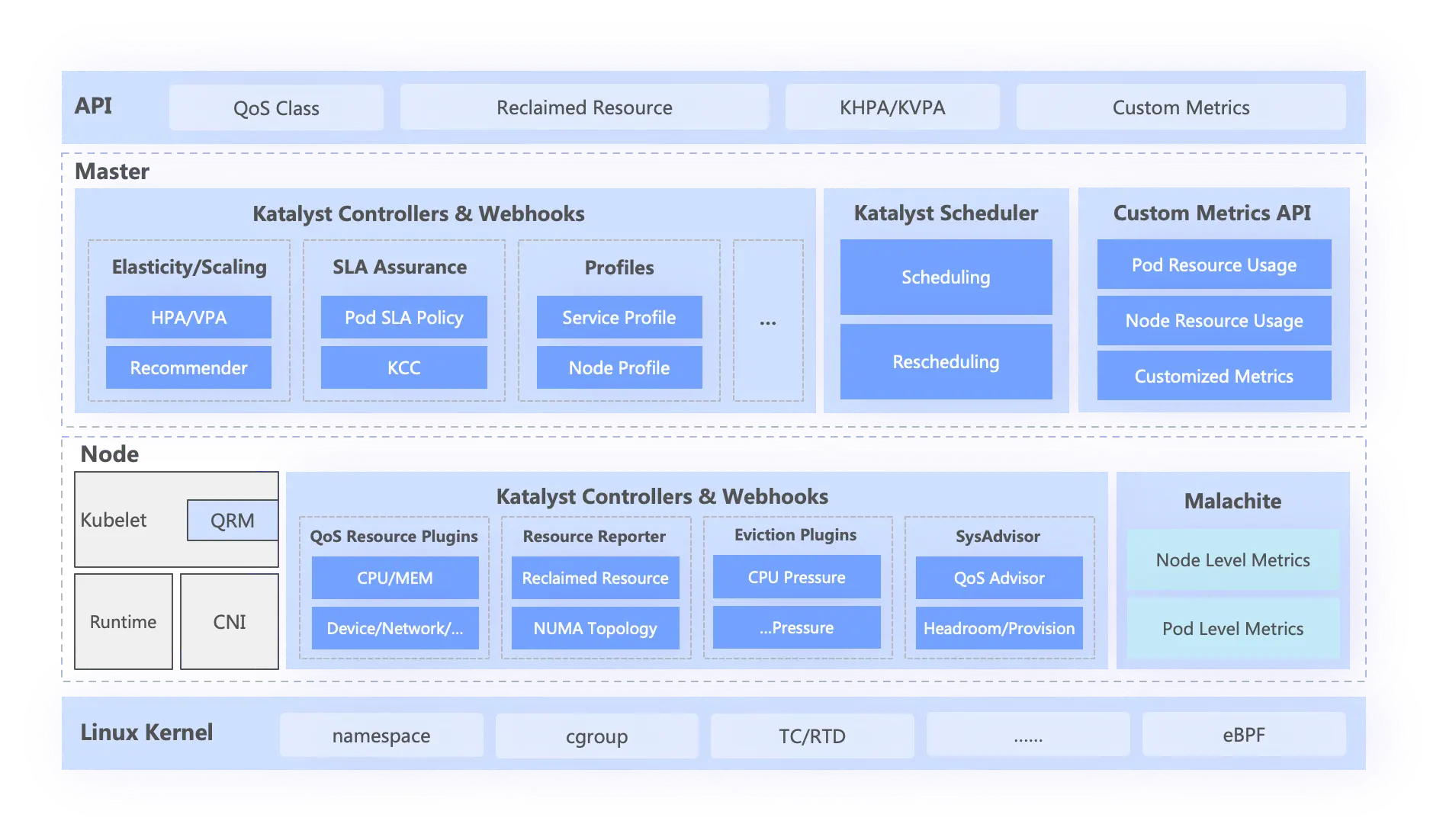
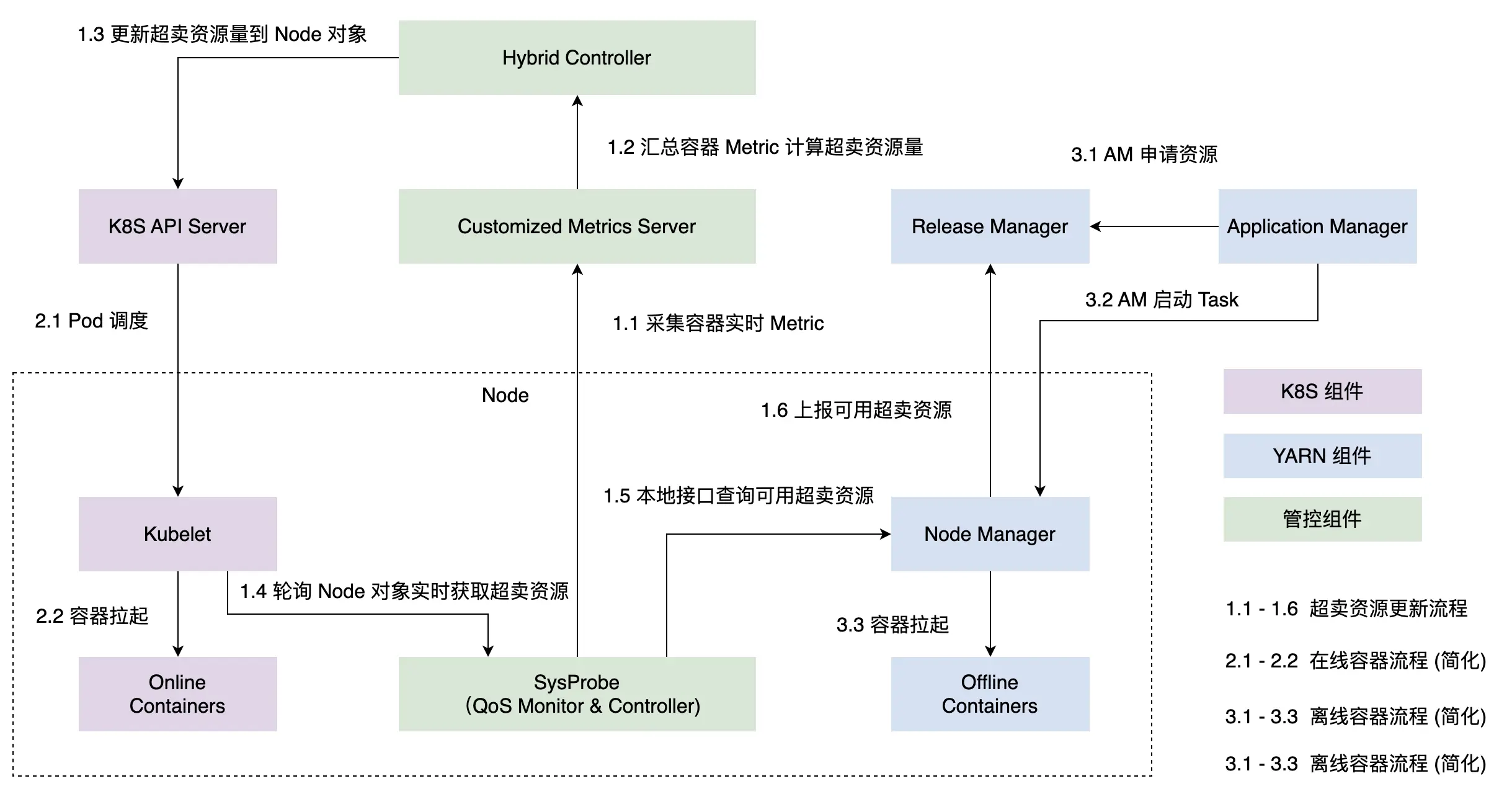
在管控层,我们将字节早期基于 Kubernetes 和 Yarn 两套体系的融合系统整合成一套基于 Kubernetes 的系统。
具体来说,我们在接入层同时保留了 Kubernetes 以及 Yarn 各自的 API 入口,底层系统的元数据管理和资源管控实现则统一收敛到基于 Kubernetes 的管控系统 Katalyst 上。
在调度层, Katalyst 在统一元数据的基础上实现了 “中心” 和 “单机” 互相协调的资源调度机制。
在单机调度侧:Katalyst 搭载 Enhanced Kubernetes 里的扩展模块 QoS Resource Manager (QRM) 能够实现可插件化的微拓扑亲和性分配,并通过自定 CRD 将微拓扑上报到中心打通调度流程;在服务运行过程中,Katalyst 会持续观察 Pod 运行时系统指标,集合业务 QoS 要求和业务指标反馈进行预估,决策出 Pod 在各个资源维度上的分配量,通过 QRM reconcile 机制实时下发到 CRI。上述过程中的资源预估模型和 QRM 实现,都可以通过插件化的方式定制,使得资源调控的策略更加匹配不同业务场景的诉求。
在中心调度侧:Katalyst 基于原生 Scheduler Framework 扩展了更加丰富的调度能力,在调度过程中同时考虑不同 QoS 业务在同一个集群中运行时资源层应该如何分配及协作,配合单机调度实现更加细粒度的调度语义要求;同时,中心调度还会结合业务容器运行时的实时数据和服务画像,在全集群范围内实现动态的 Rebalance 策略,降低集群空置率,提升业务稳定性。
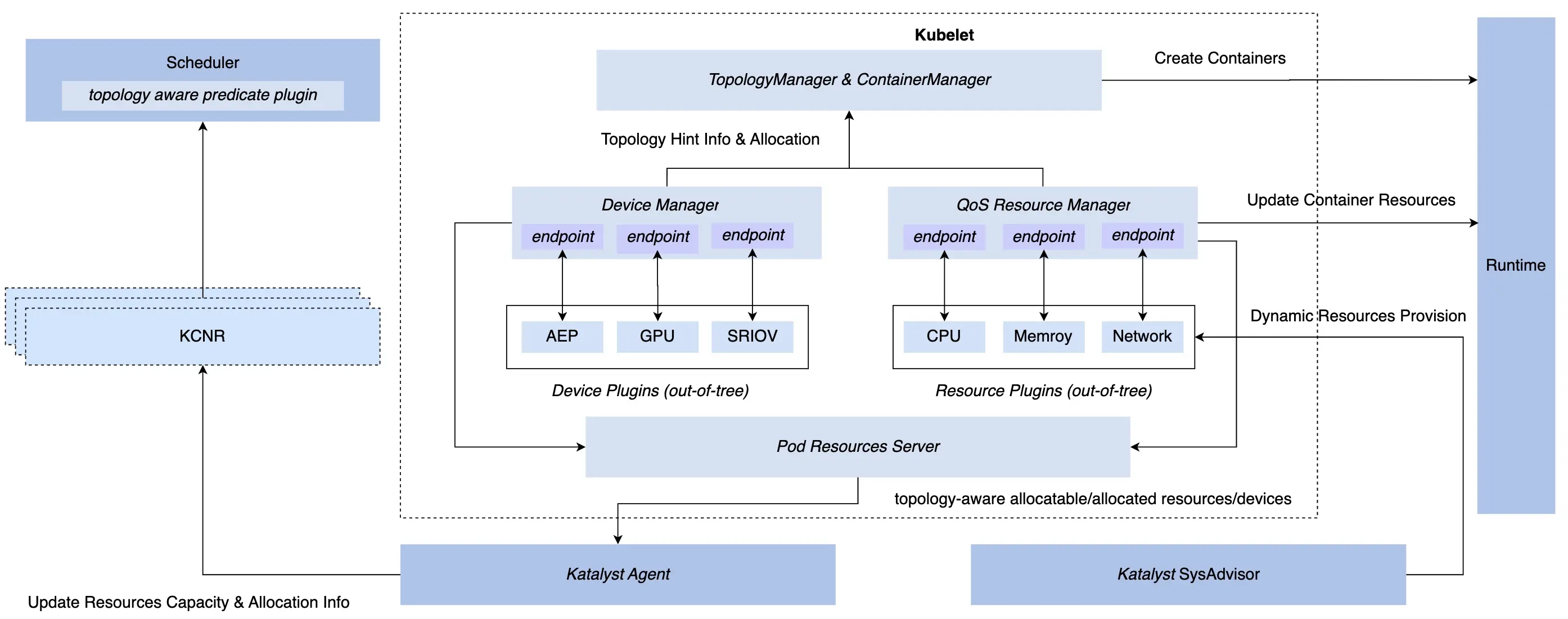
通过收敛资源管控,Katalyst 有效减少了系统运行中的资源损耗。此外,在联合管控体系下,Katalyst 将旁路异步管控的实现切换成基于标准 CRI 接口的同步管控实现,避免因为各种异步引发的 race 或者冲突,从而引发服务性能抖动。
最后,在一套管控体系下,我们还能够充分享受 Kubernetes 面向 API 设计的优势,通过自定义 CRD 的方式去解耦内部系统,泛化管控策略,使得系统能够通过插件化的方式更加灵活地系统迭代,真正实现了内外同源。
RoadMap
Katalyst 作为一个资源管理系统,在离线混部是其核心应用场景之一。除了抽象上述核心概念之外,我们还为 Katalyst 提供和规划了丰富的 QoS 能力:
- 精细化的资源出让策略:Katalyst 支持基于静态启发式、无监督算法、QoS Aware 的多种资源预估策略,更准确的计算和预测节点可出让资源量,进一步提高资源利用率。
- 多维度的资源隔离能力:基于 cgroup, rdt, iocost, tc 等能力,实现不同混部场景中对 cpu,内存,磁盘,网络等多种资源的有效隔离,保障在线业务的 QoS 不受影响。
- 多层级的负载驱逐策略:支持基于多种指标,多层级的驱逐策略,在保障在线业务 QoS 的同时也尽可能提高离线业务的 QoS。
除了混部场景,Katalyst 也提供一些增强的资源管理能力:
- 资源弹性管理:提供灵活可扩展的 HPA/VPA 资源弹性策略,帮助用户提高部署率和资源利用率。
- 微拓扑感知调度:感知节点上 CPU,内存,异构设备的微拓扑,基于更细粒度的微拓扑信息完成资源分配,满足高性能业务的 QoS 要求。
详细的功能规划请参考 roadmap。
虽然混部技术在字节内部已经经历了几次的技术迭代,但是一个通用、标准化的平台底座必然要经过各种场景的打磨,我们非常期待更多朋友加入到 Katalyst 开源社区中!
项目地址:github.com/kubewharf/katalyst-core