不止于监控,夜莺 V6 来了!今天我们郑重发布夜莺 6.0 beta 版本,全面支持 Metrics、Logging、Tracing,向着构建开源、开放、完整的可观测性解决方案迈进。您可以借助夜莺 V6,接入和管理 Prometheus、ElasticSearch、Jaeger 多种数据源,实现数据的统一可视化、告警和分析。
🚀 可以在页面管理数据源了
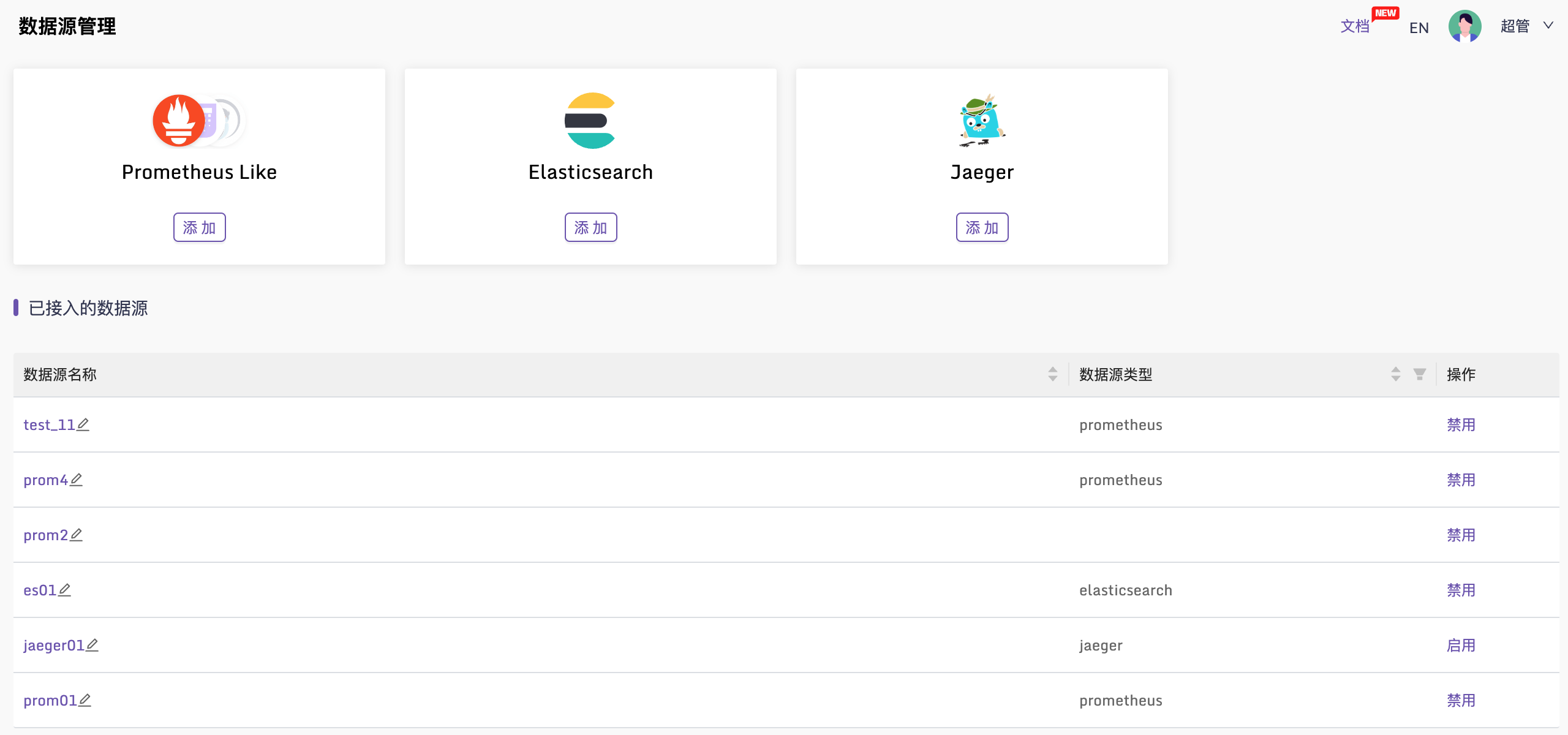
无需修改配置文件里的Clusters配置了,直接在页面就可以管理了。除了兼容 Prometheus 查询协议的数据源,也支持 Jaeger 和 ElasticSearch 作为数据源接入。
🚀 可以接入 ElasticSearch 数据源了
类似 Grafana 的配置体验,可以接入已有的 ElasticSearch 数据源,自然的,就可以在夜莺里查看 ElasticSearch 的数据了,监控大盘的图表数据也可以从 ElasticSearch 获取。
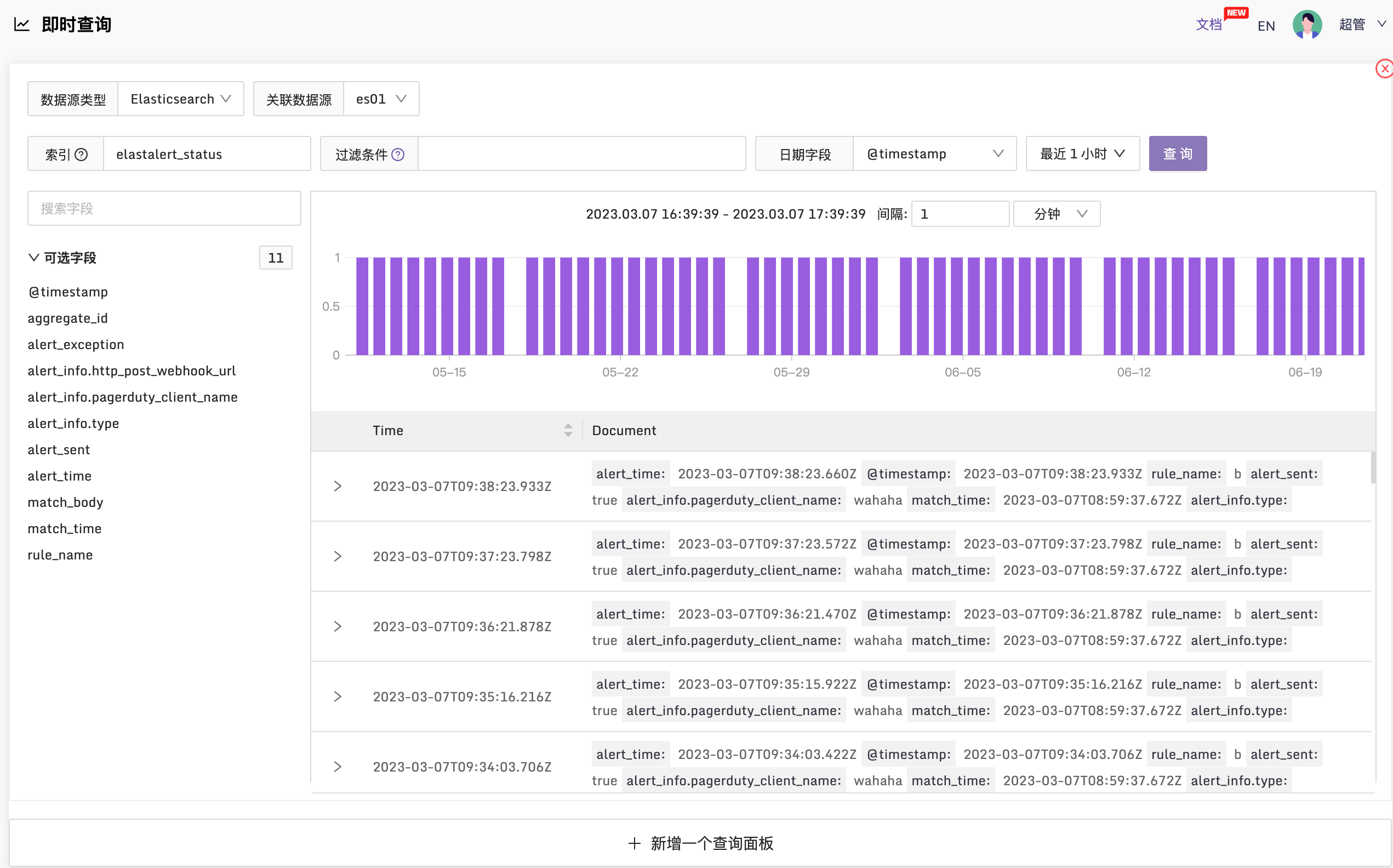
🚀 可以接入 Jaeger 数据源查看链路数据了
Jaeger 在 CNCF 蓝图中,是链路追踪的佼佼者,所以我们首先支持了 Jaeger,目前做到的效果是可以在夜莺里查看 Trace 甘特图和拓扑依赖。
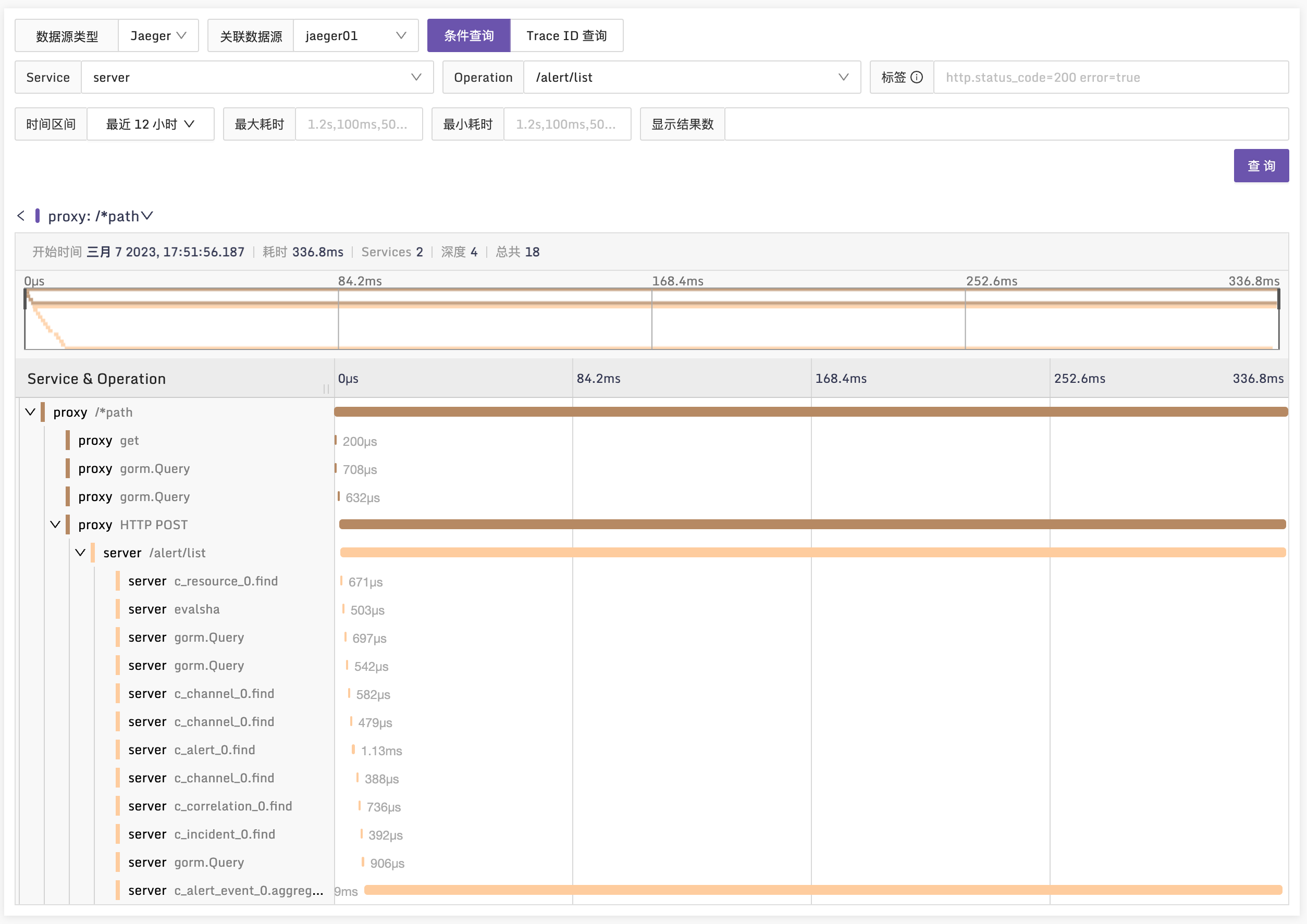
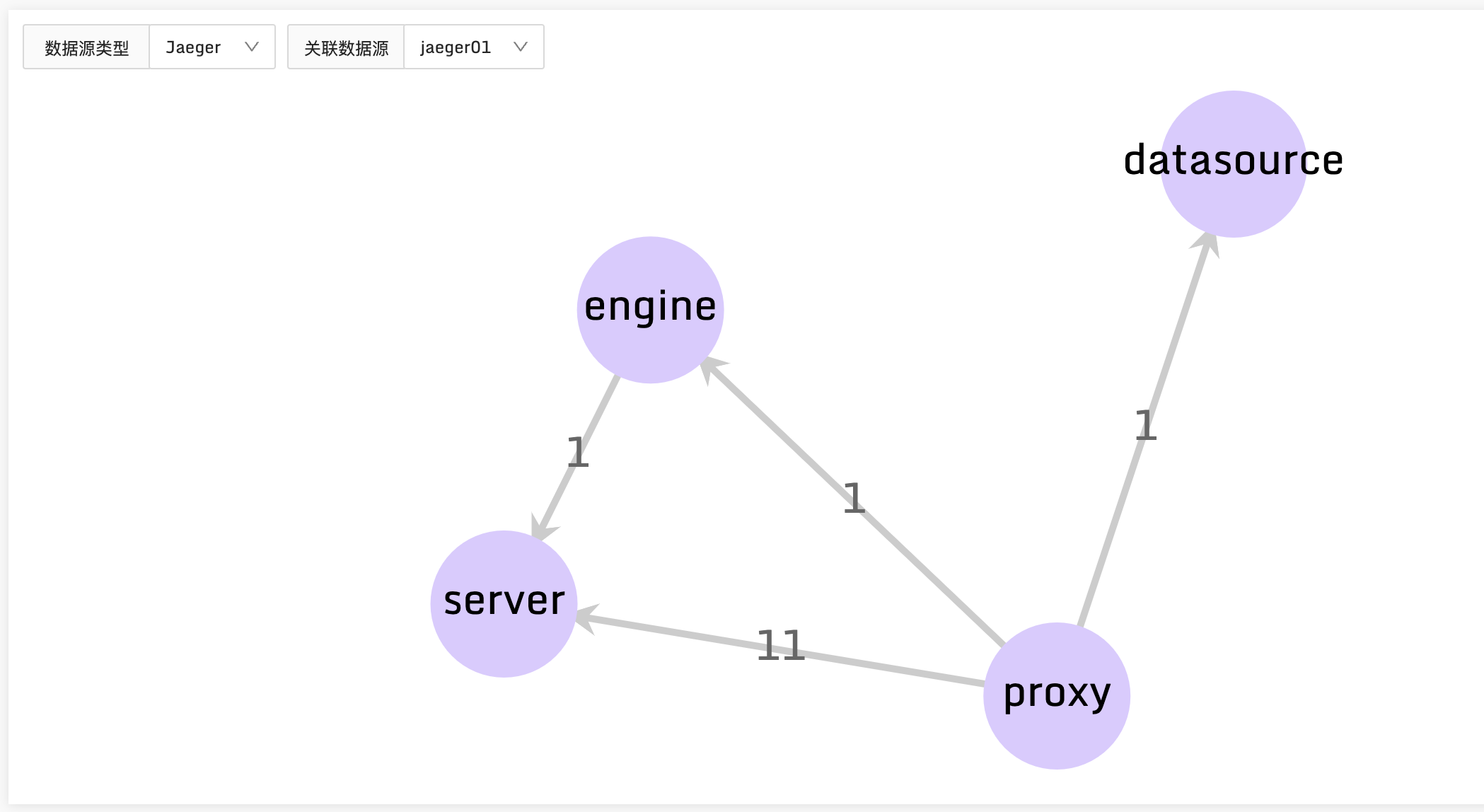
现在这个版本,可以把 metrics、logging、tracing 的数据都做到可视化了,只是数据串联方面还差一些,后续版本继续迭代优化,万里长征先走了一步。
🚀 架构做了简化
Nightingale 5.x 的版本,至少需要 n9e-webapi 和 n9e-server 两个模块,6.x 开始默认只需要一个模块了,就叫 n9e。我们先来回顾一下 5.x 的架构:
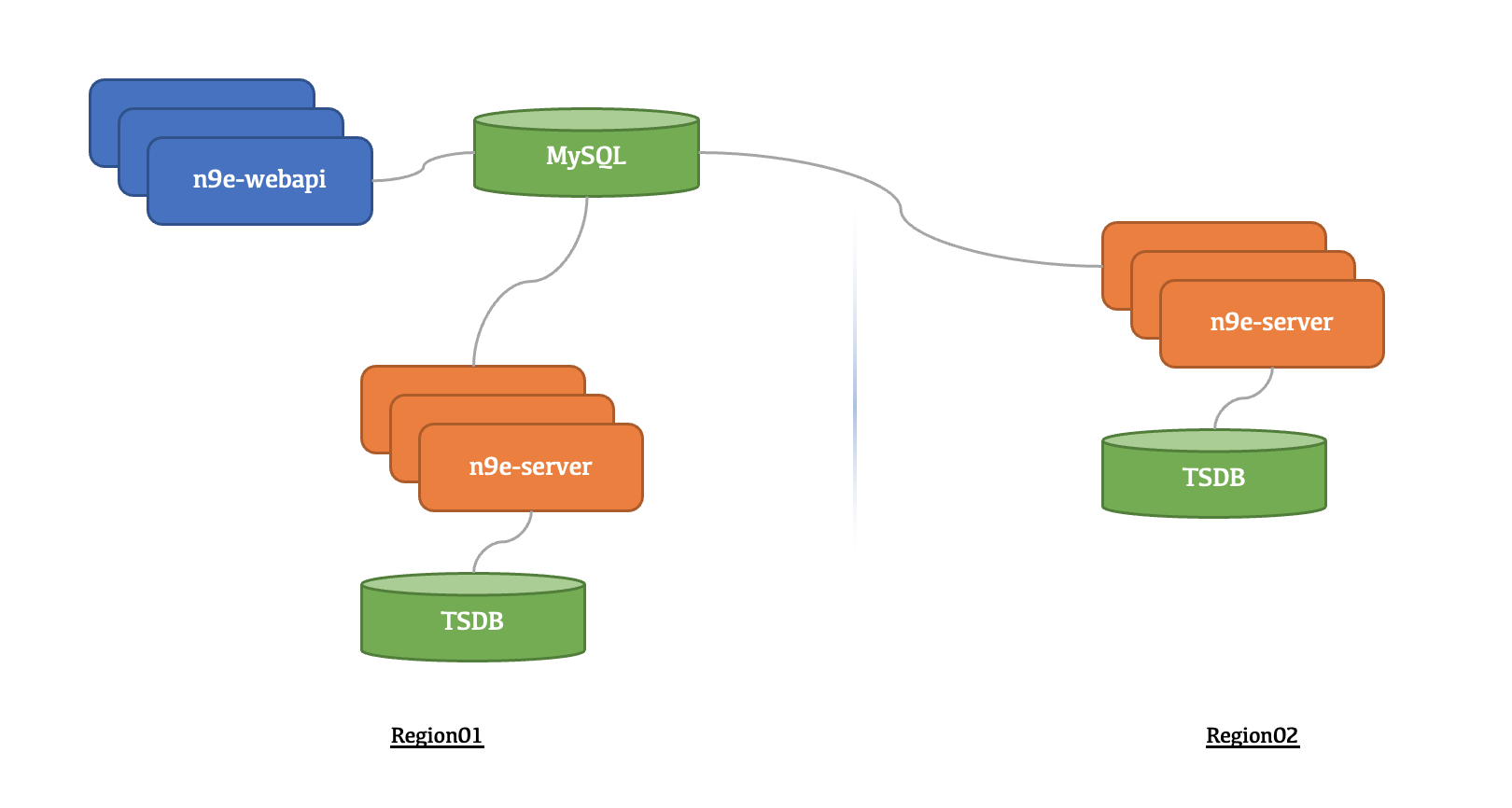
假设两个集群,Region01是中心机房,部署了一整套夜莺,Region02和Region01的网络链路不好,所以Region02单独搞了一套 TSDB,n9e-server 跟随 TSDB,所以 Region02 也部署了一套 n9e-server。图上其实少画了 Redis,n9e-webapi 和 n9e-server 都依赖 Redis,可以全局用一个 Redis,也可以每套 n9e-server 部署自己的 Redis。
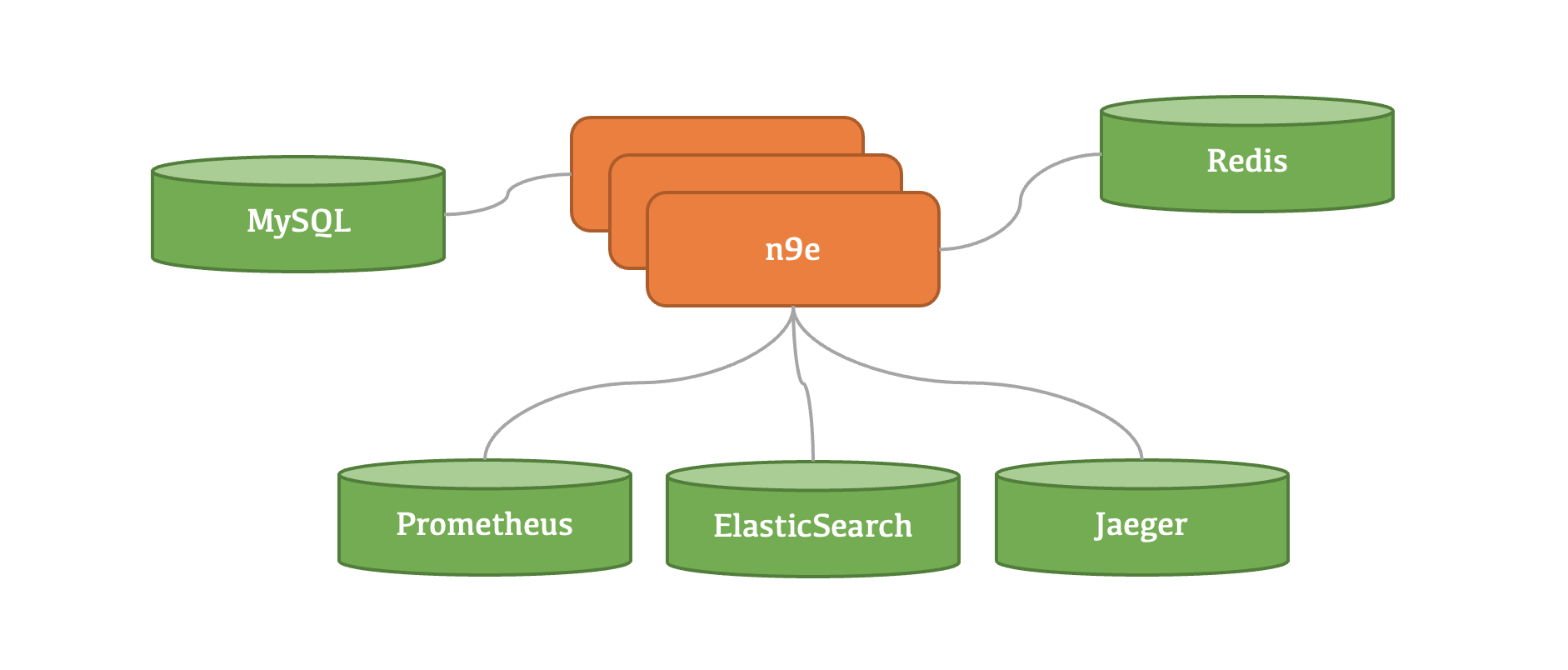
6.x 版本把 webapi、pushgateway、alerting 模块合并成一个n9e模块了,这个模块可以对接多个数据源,n9e模块也可以部署多个实例组成集群,架构上变简单了。
当然,如果某个机房和中心机房之间网络链路不好,想在这个边远的机房下沉部署一套时序库+告警引擎,也是OK的。除了 n9e 模块,我们也单独提供了 n9e-pushgw(数据转发网关) 和 n9e-alert(告警引擎),这俩模块是可选的,平时都用不到,只是应对边远机房网络链路不好的情况。
🚀 可维护性提升
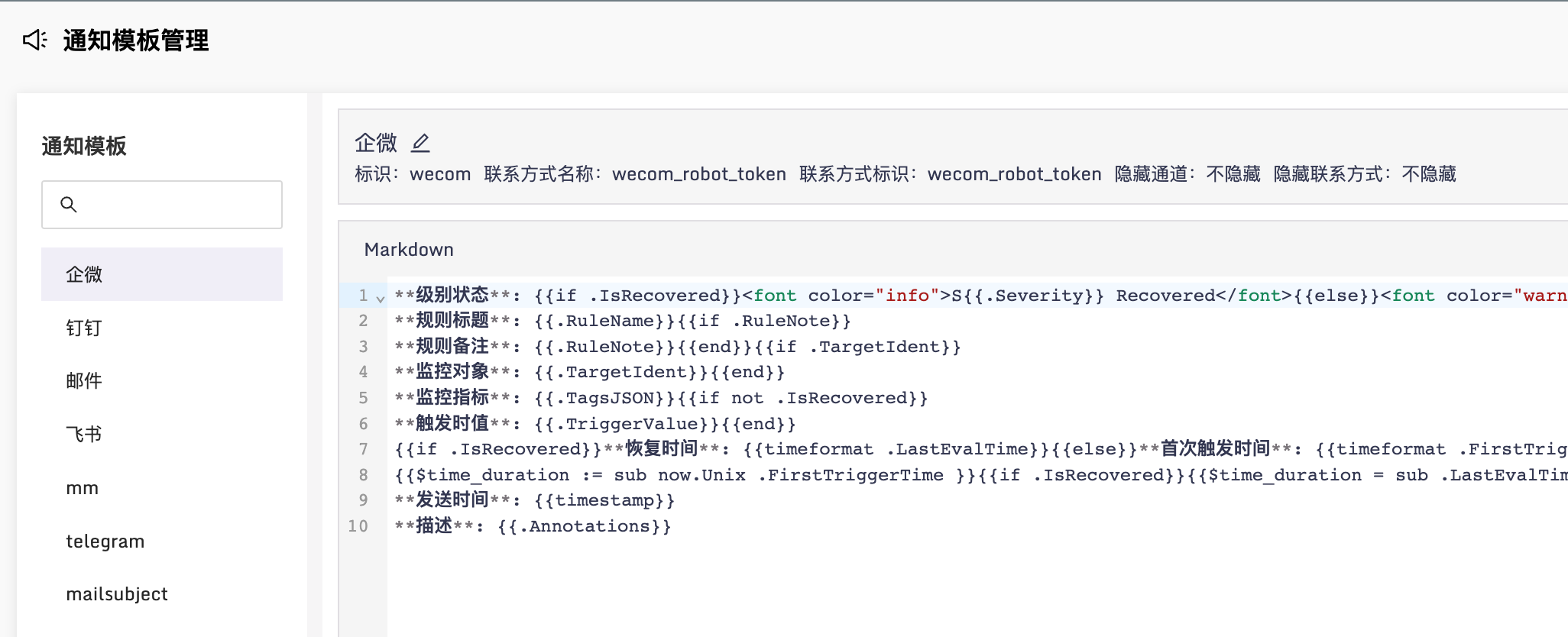
除了架构方面做了简化,降低了维护复杂度,很多配置也挪到页面上管理了。比如单点登录相关的配置、告警发送模板相关的配置:
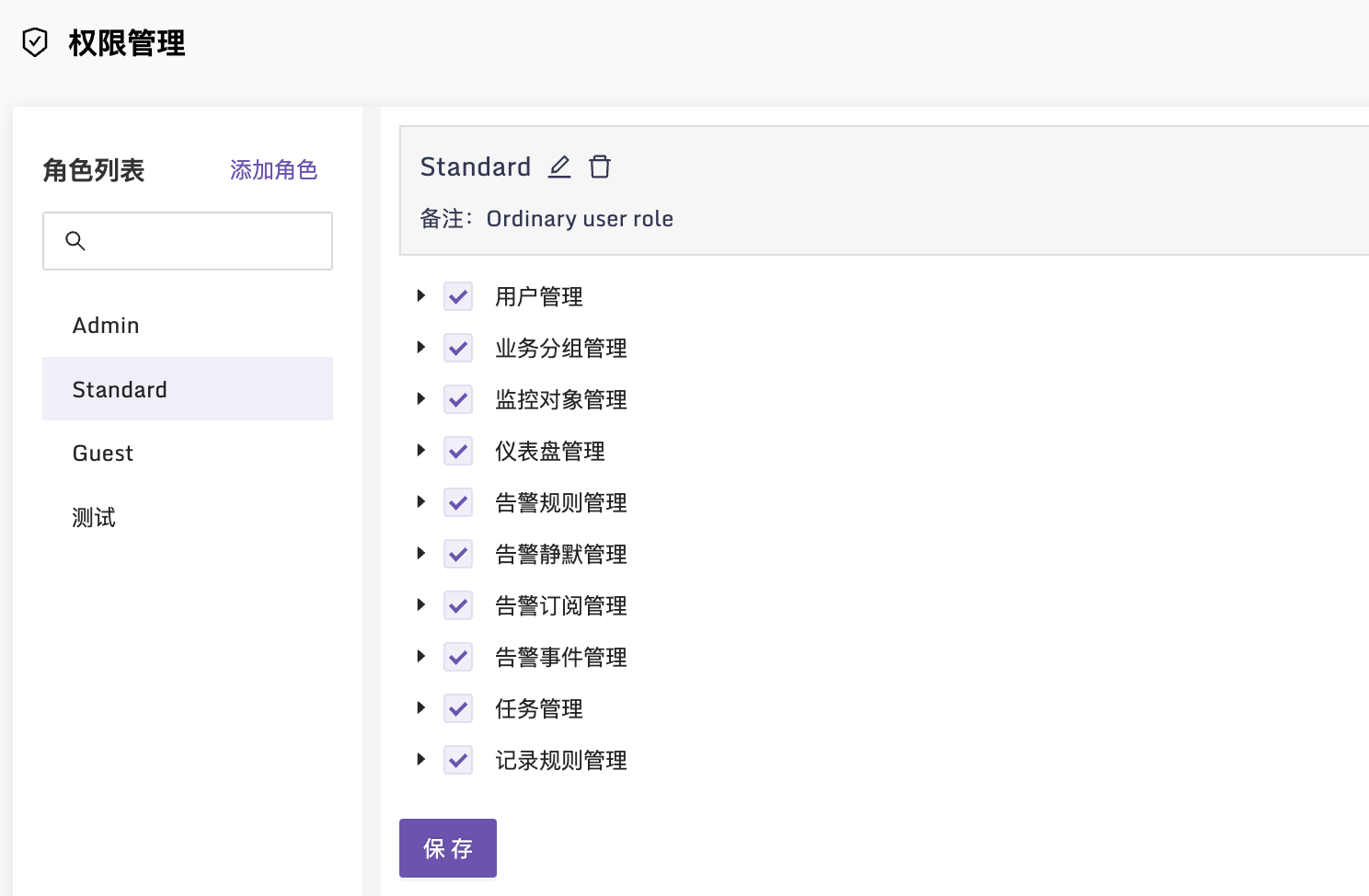
角色管理也挪到页面上了,不用像 5.x 的版本那样,只能通过修改数据库创建新的角色了。
🚀 增加了内置监控大盘
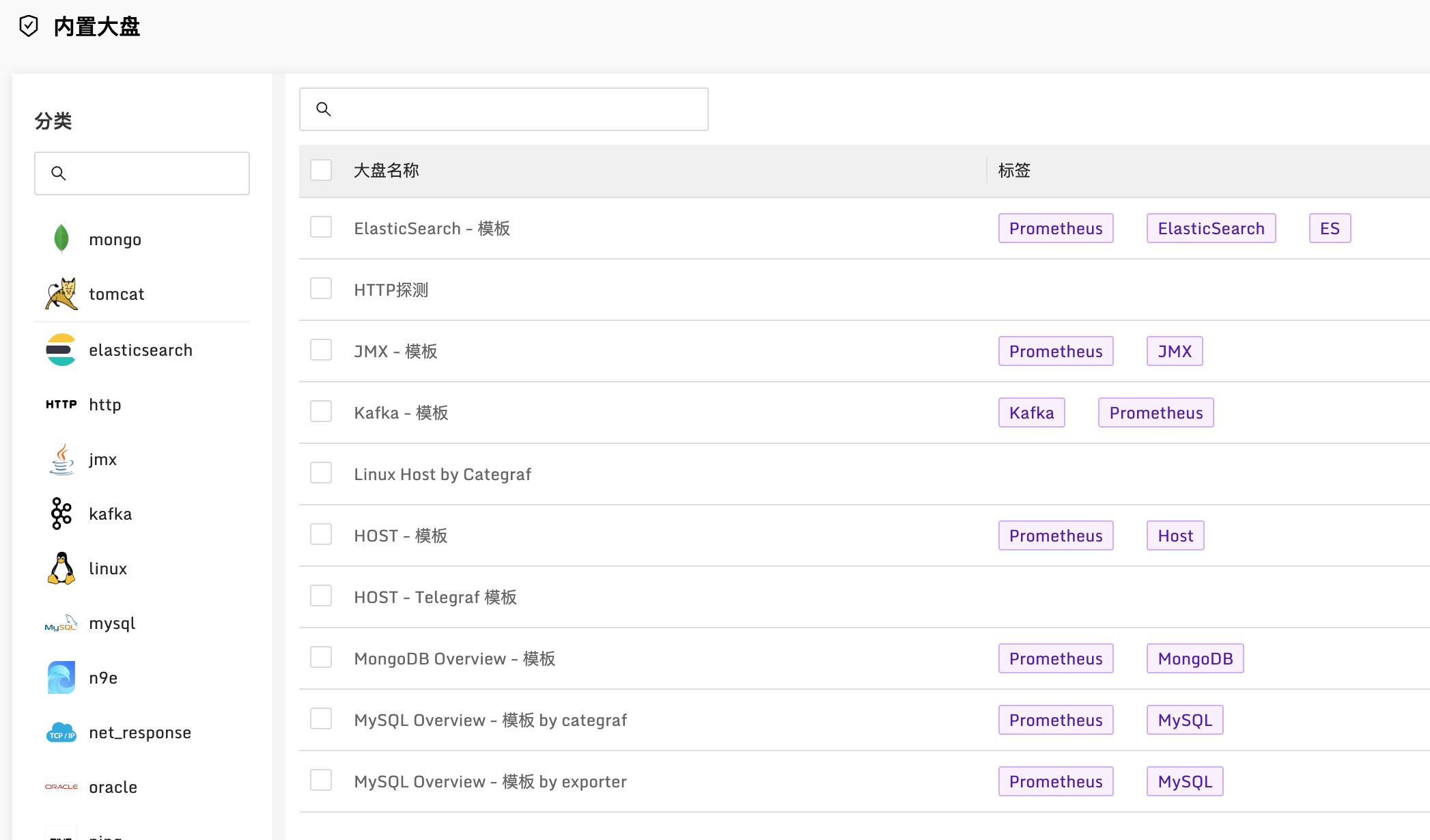
5.x 的版本其实就有内置监控大盘,但是必须把内置监控大盘导入到自己的业务组使用。6.x 开始,提供了内置大盘的浏览页面,可以不用导入自己的业务组直接使用。
欢迎夜莺社区的小伙伴一起共建共创,把内置监控大盘搞的多多的,为社区建设添砖加瓦,功在当代利在千秋!
🚀 增加了内置告警规则
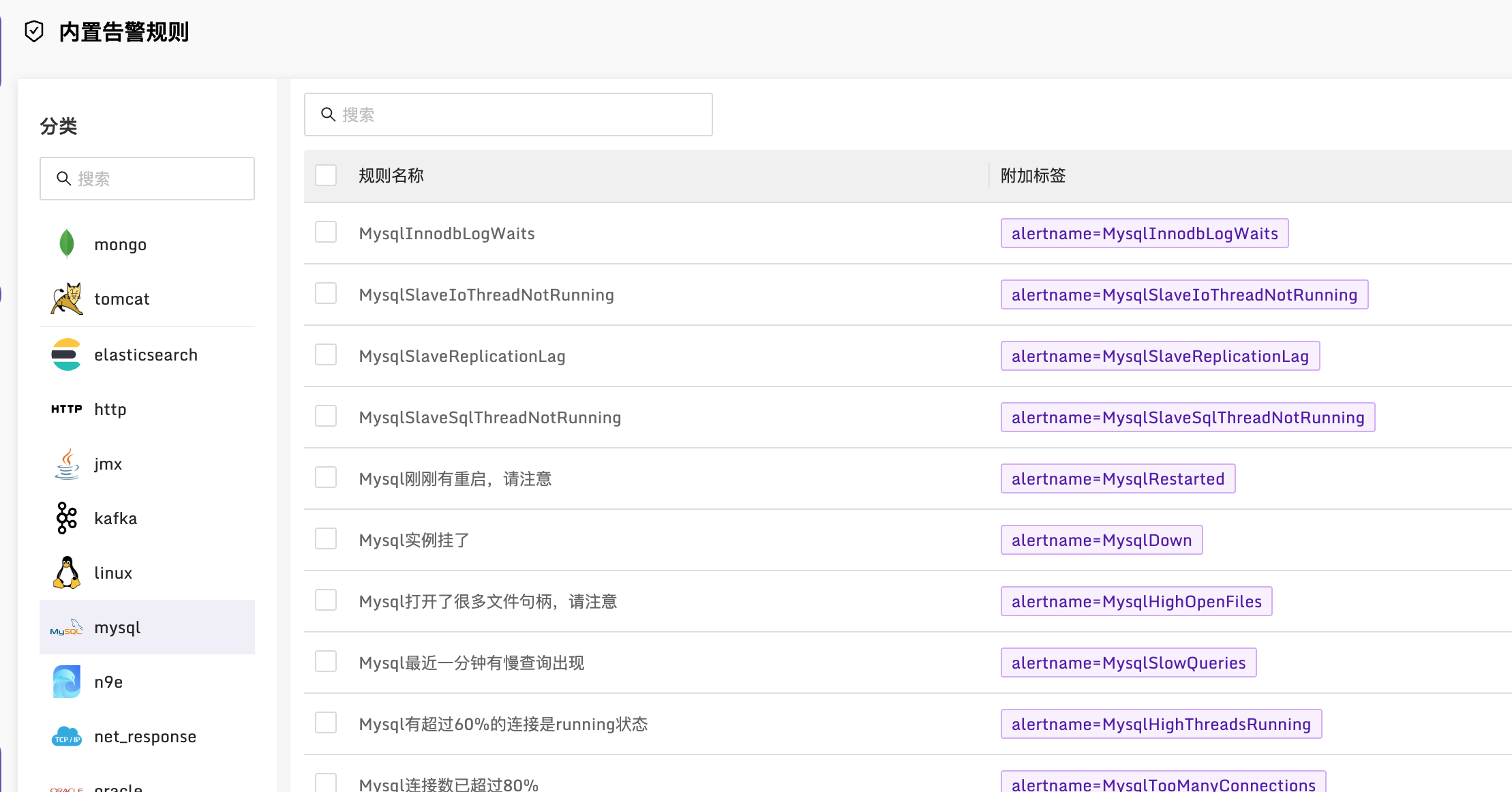
同理,也内置了各类组件的告警规则,极大的增加了便利性。当然了,我们也非全能,期待社区小伙伴一起共建共创,把内置告警规则也搞的多多的,如果不知道如何贡献,可以联系我们 🤝
🚀 继续优化了告警规则
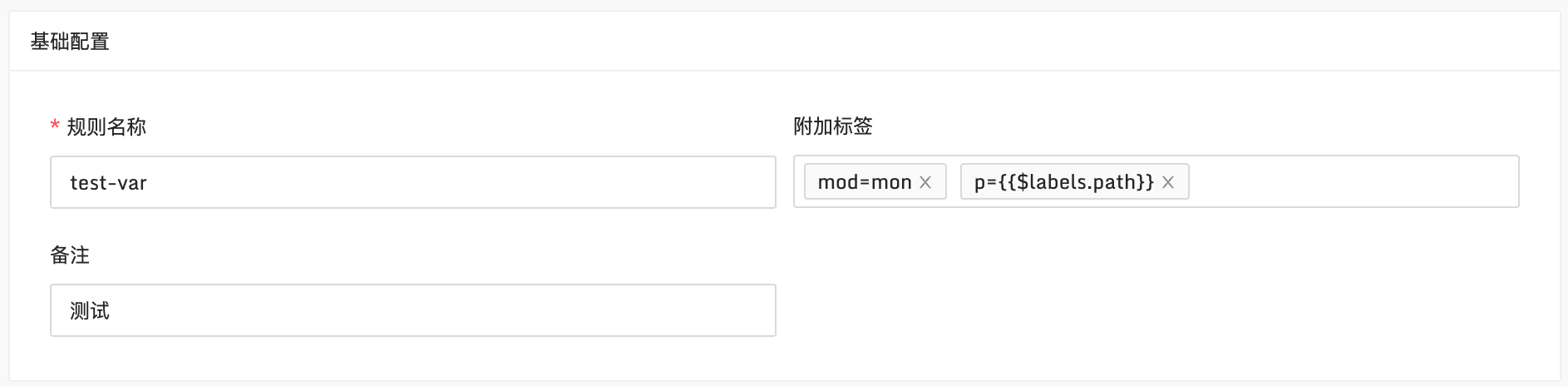
附加标签支持变量了,于是,我们可以对告警的vector的标签做一些二次处理。
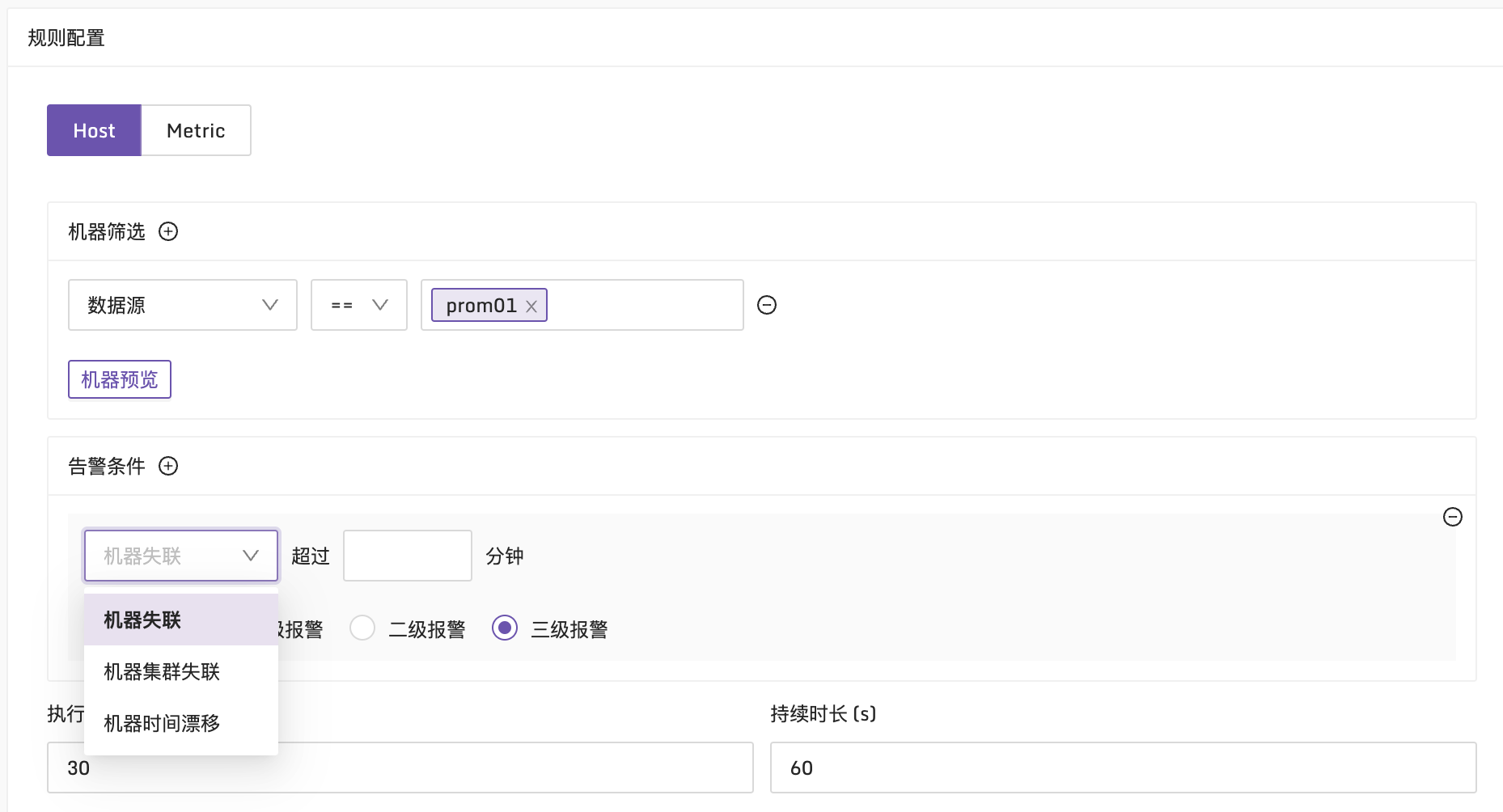
对于机器失联告警、机器时间偏移做了更好的实现。废弃了原本的 target_up 指标的生成逻辑,在告警规则里直接内置支持了机器失联告警和时间偏移告警,甚至,额外增加了机器失联比例告警。
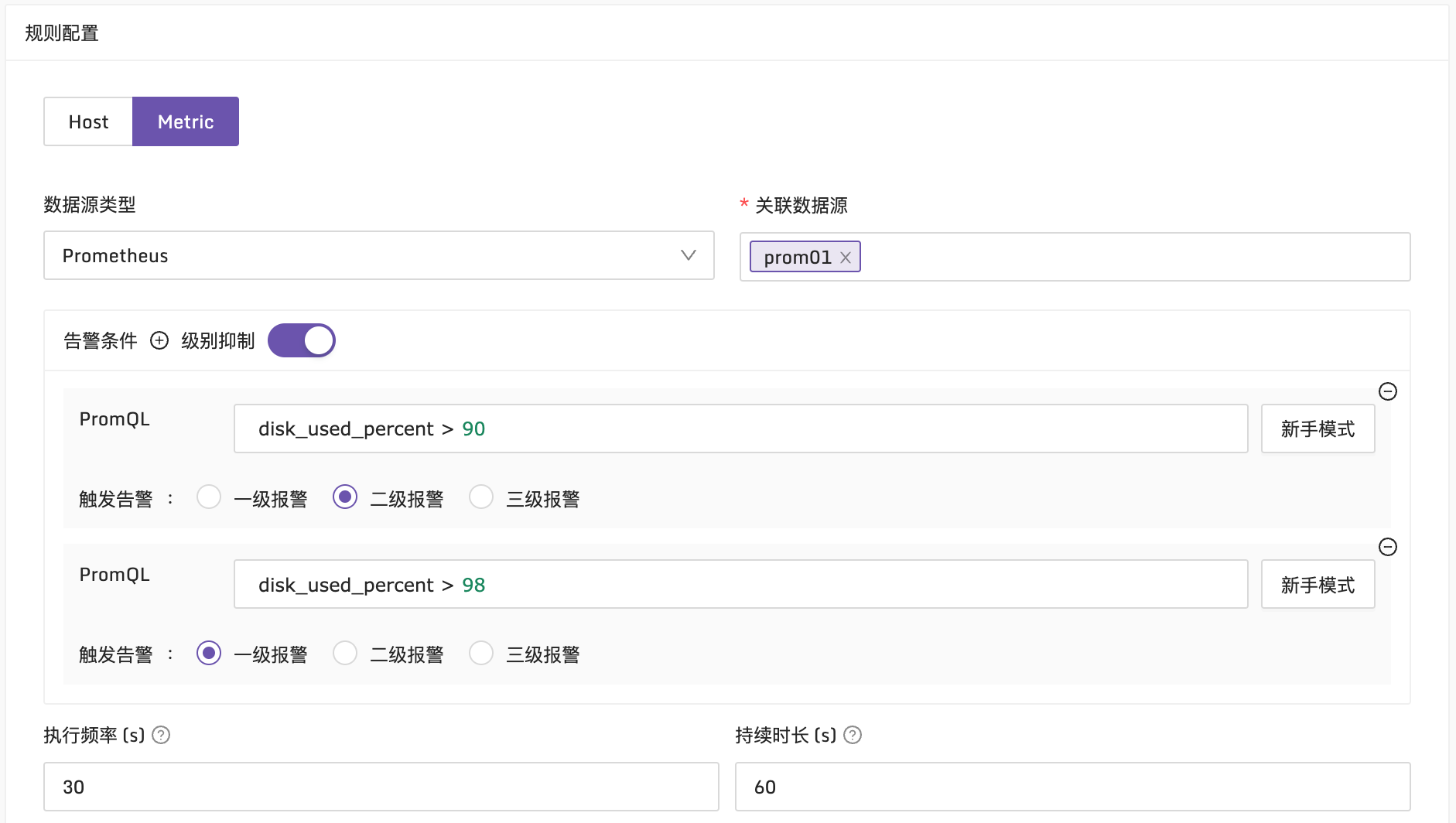
阈值告警也做了优化,一个告警策略里可以配置多个规则,指定不同的级别,而且支持级别抑制,高级别的告警抑制低级别的告警。
商业版本则更加强大,不止支持普通的阈值告警,还支持算法告警引擎、SLS告警引擎等。如有需要欢迎 联系我们,做产品交流、试用产品,合作共赢 :)
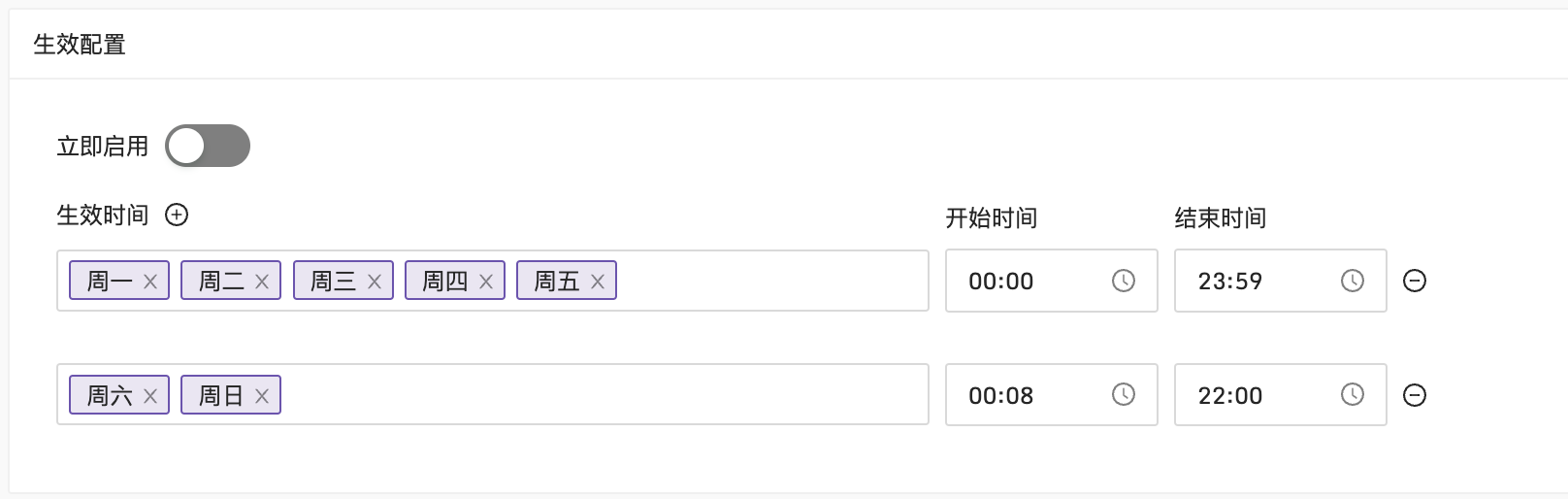
顺便介绍一下告警规则的多时间段配置,其实 5.15 版本就支持了,但是很多人不知道,借此机会也一并说一下。这个功能是社区提出的,对于一些特定的场景非常有用。
🚀 继续优化了屏蔽规则
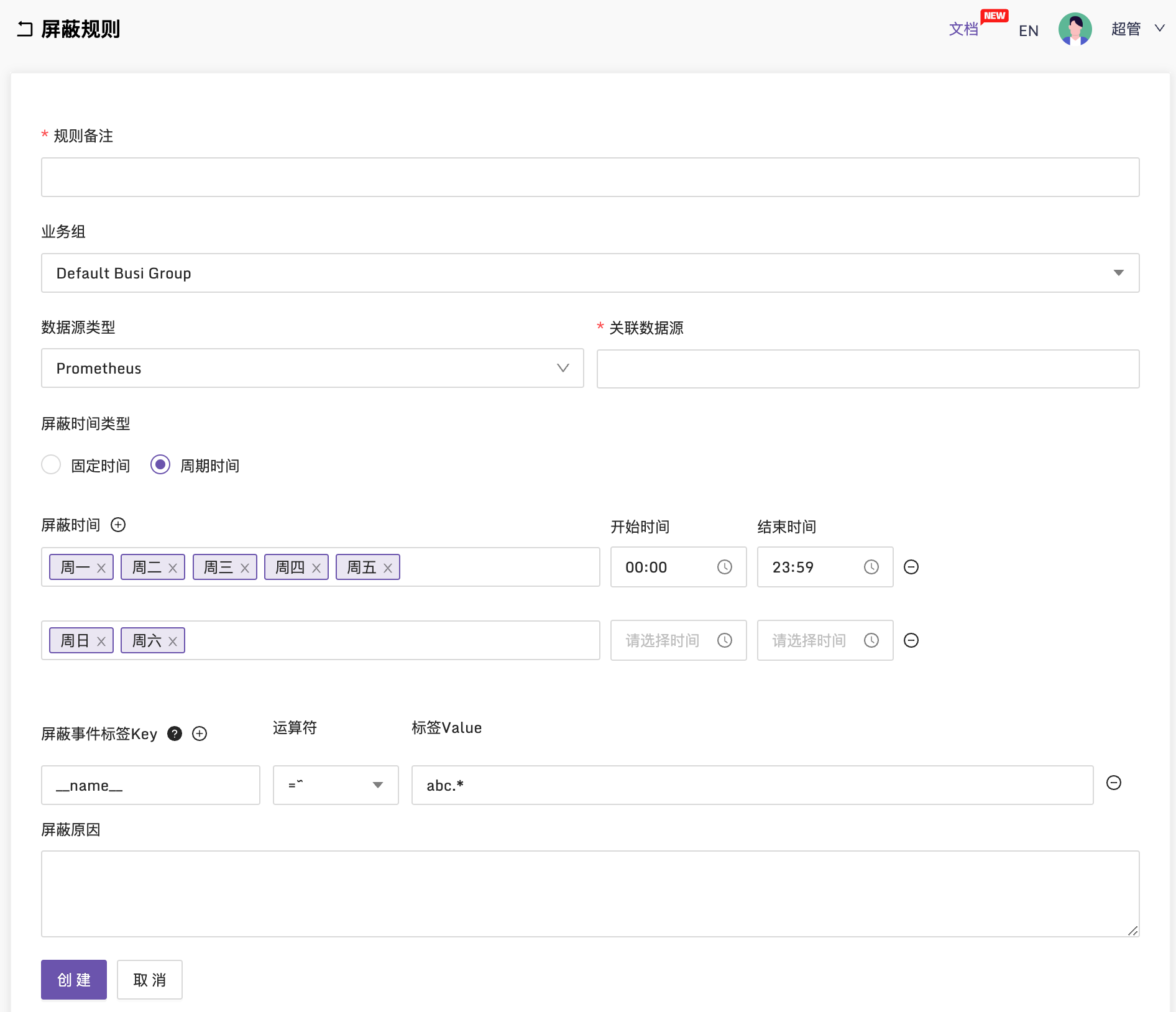
增加了大家心心念念的周期性屏蔽,惊不惊喜意不意外?看图就知道这个是啥意思了,我就不详细解释了。有没有感觉开源夜莺的一些功能已经比很多商业软件做的都好了 😎
🚀 继续优化了订阅规则
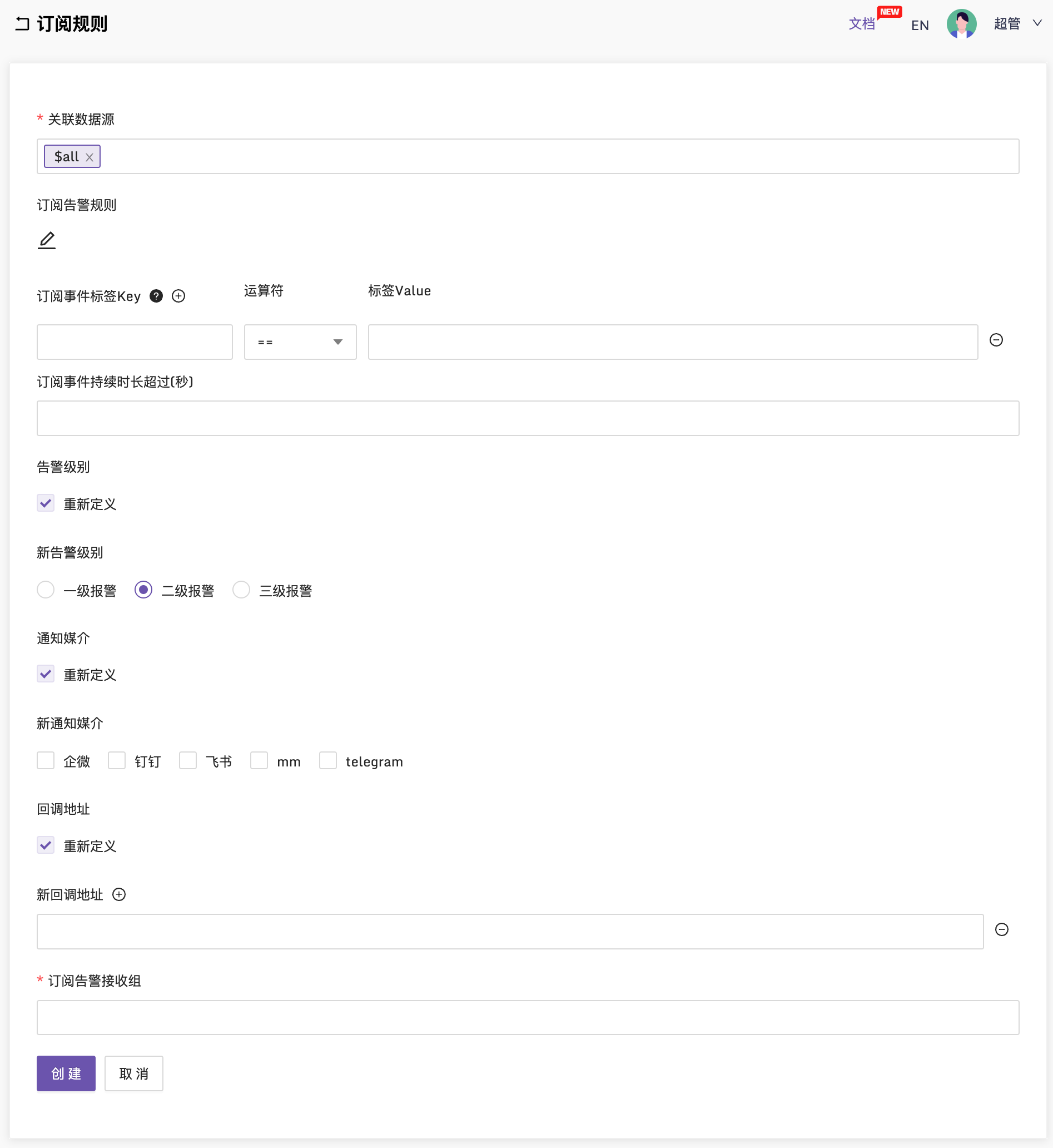
订阅规则引入了“订阅事件持续时长超过(秒)”的配置,这个功能很酷,一定程度上可以实现告警升级的功能,不过相比完备的告警升级,还是差点意思,没有认领、排班之类的功能,如果想建立统一的告警事件中心,接收各类监控系统的告警事件,统一做告警降噪、认领、升级、排班、协同等功能,请使用我们的 FlashDuty,FlashDuty是SaaS版本的OnCall中心,有免费套餐可用~
另外,订阅规则可以重新定义回调地址,可以对一些特定的告警事件做自动化处理,比如把特定的告警事件发给FlashDuty~~
🚀 夜莺开源社区发展和治理
夜莺监控,于2022 年 5 月 11 日,正式托管于中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。在计算机学会的支持和带动下,在快猫星云和众多公司的持续投入下,和数千名社区用户的积极参与,截止当前,夜莺开源项目在 Github 上获得了 6K star,1K fork,近 100 位 Contributor,夜莺开源社区展现出了蓬勃的生机。
夜莺 V6,是夜莺监控往全栈可观测性解决方案迈进的关键一步,是夜莺项目管理委员会和夜莺开源社区共同努力的成果。
🚀 夜莺开源项目大事记
- 2020 年 3 月,夜莺监控由滴滴技术正式在 Github 开源,凭借其优秀的产品设计、灵活性架构和明确清晰的定位,夜莺监控快速发展为国内最活跃的企业级云原生监控方案。
- 2022 年 5 月 11 日,夜莺监控正式捐赠予中国计算机学会开源发展委员会 CCF ODC,为 CCF ODC 成立后接受捐赠的第一个开源项目。
- 2022 年 8 月 1 日,发布夜莺监控开源社区治理架构,并公示相关的任命和社区荣誉。
- 2023 年 3 月 9 日,夜莺 V6 全新发布,夜莺监控升级为开源观测平台。
🚀 交流和联系
V6 beta 版本,欢迎各位小伙伴安装试用 👉 部署指南 👈 可观测性这个事,我们是认真的!