除了大力投资 Open AI ,微软还亲自下场大搞 AI 。5 天前,微软开源了 Visual ChatGPT ,这个软件可以连接 ChatGPT 和一系列视觉模型,以实现在 ChatGPT 的聊天过程中发送和接收图像。
众所周知,尽管 ChatGPT 的功能非常强大,甚至可以用来写小说写论文,但目前也仅限于文字交流。但表情包早已成为日常文本聊天不可或缺的功能。
Visual ChatGPT 的出现,就像在以文字交流的 APP 中首次添加了表情包功能,而且还是根据用户输入的文本自动生成的“定制化表情包”,大大提升了 ChatGPT 的趣味性和应用领域。
一方面,ChatGPT(或 LLM)充当通用界面,提供对图像的理解和用户的交互功能。另一方面,基础图像模型通过提供特定领域的深入知识来充当背后的技术专家。
仓库中列出了技术架构及原理图:
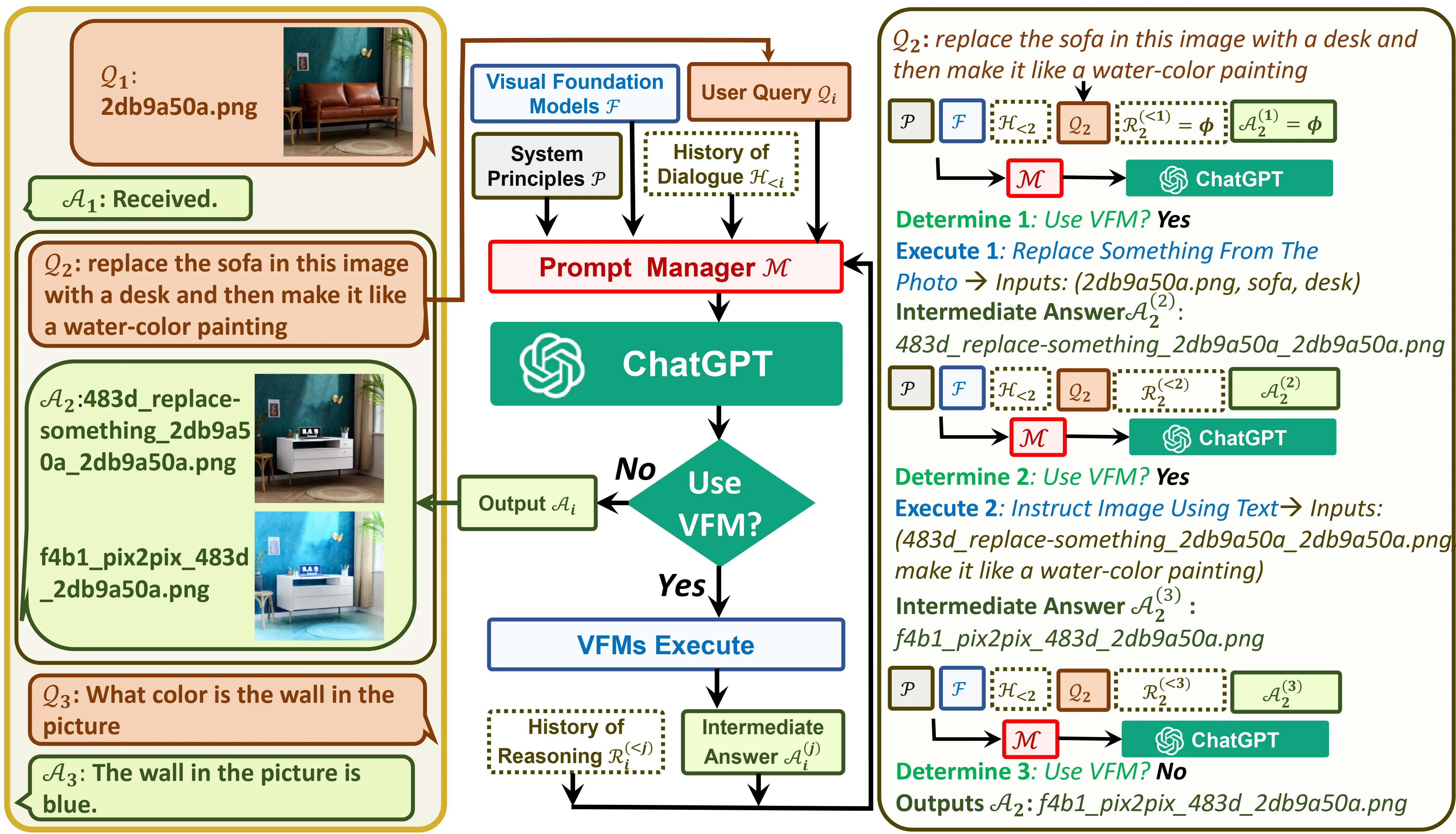
Demo 中共进行了三种不同类型的对话,分别是 Visual ChatGPT 接收用户的图像、Visual ChatGPT 根据用户的文本修改图像并发送给用户,以及 Visual ChatGPT 识别图片,并回答用户的提问。 Visual ChatGPT 会根据用户的输入,判断是否需要使用 VFM (Visual Foundation Model,视觉基础模型)来处理该问题。
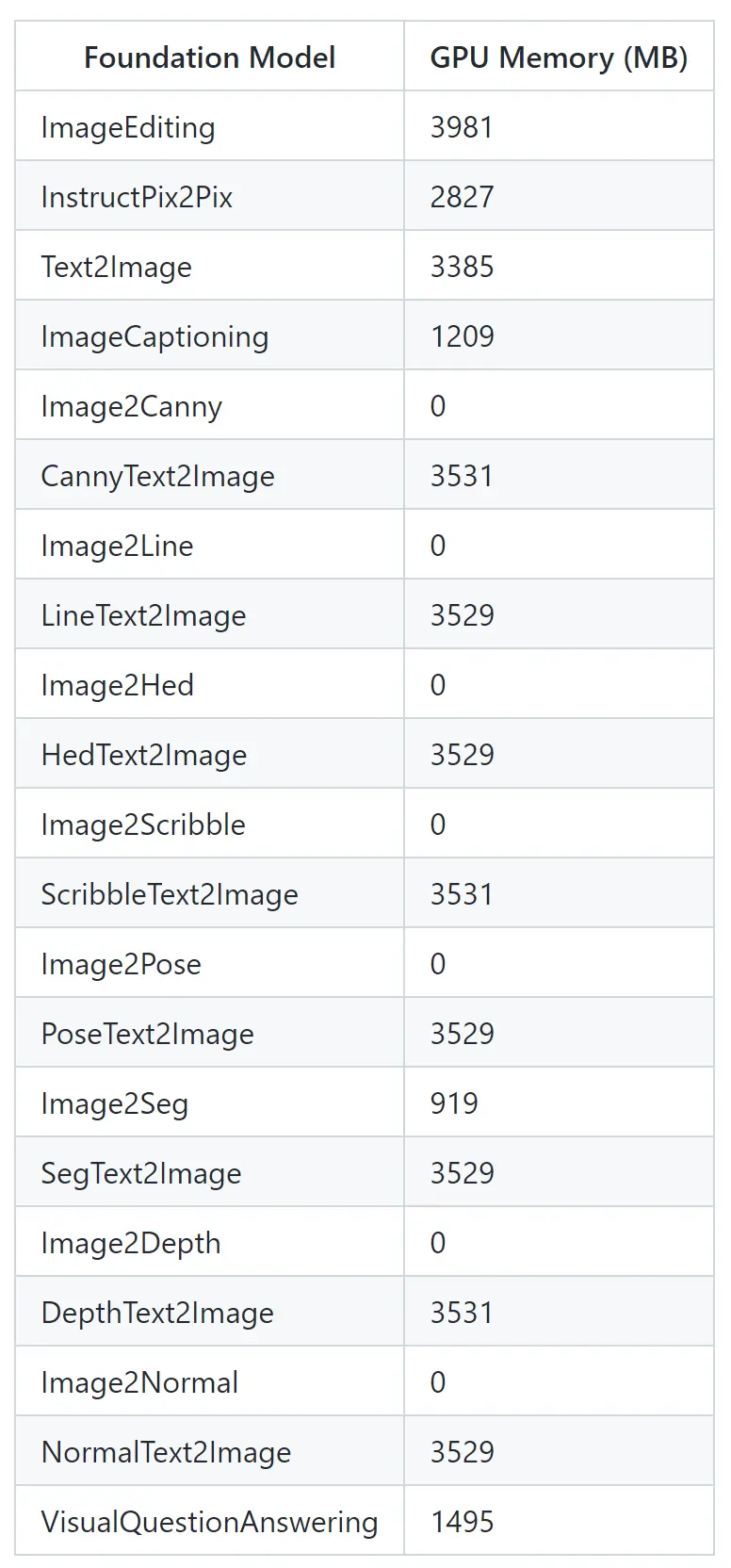
仓库中还给出了 Visual ChatGPT 所使用的图像模型和显存使用情况:
更详细的内容可以阅读 Visual ChatGPT 的 arxiv 论文:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
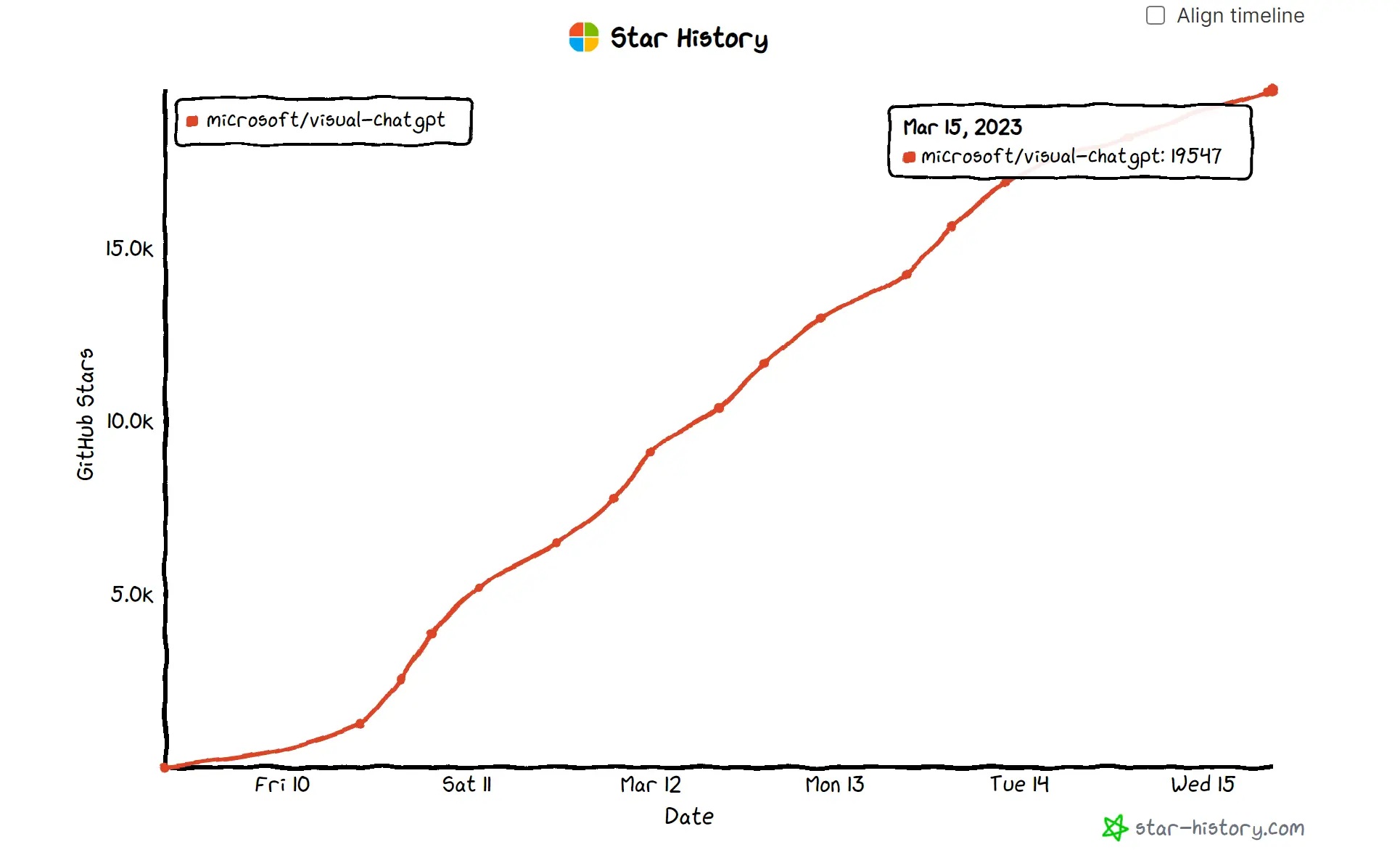
Visual ChatGPT 在 3月 10 日发布,截至 3 月 15 日早 9 点,该项目已暂获 19547 个 Stars ,可谓是火箭式上涨。