GreptimeDB 是 Rust 实现的开源时序数据库,尤其关注可扩展性、分析能力和效率,专为云时代的基础设施而设计。
功能
- 提供可扩展到高可用分布式集群的独立二进制文件
- 优化处理时序数据的柱状布局
- 提供灵活的索引选项
- 利用弹性计算资源的分布式并行查询
- 提供用于高级分析场景的原生 SQL 和 Python 脚本
- 使用广泛采用的数据库协议和 API
- 适用于大量工作负载的可扩展表引擎架构
架构
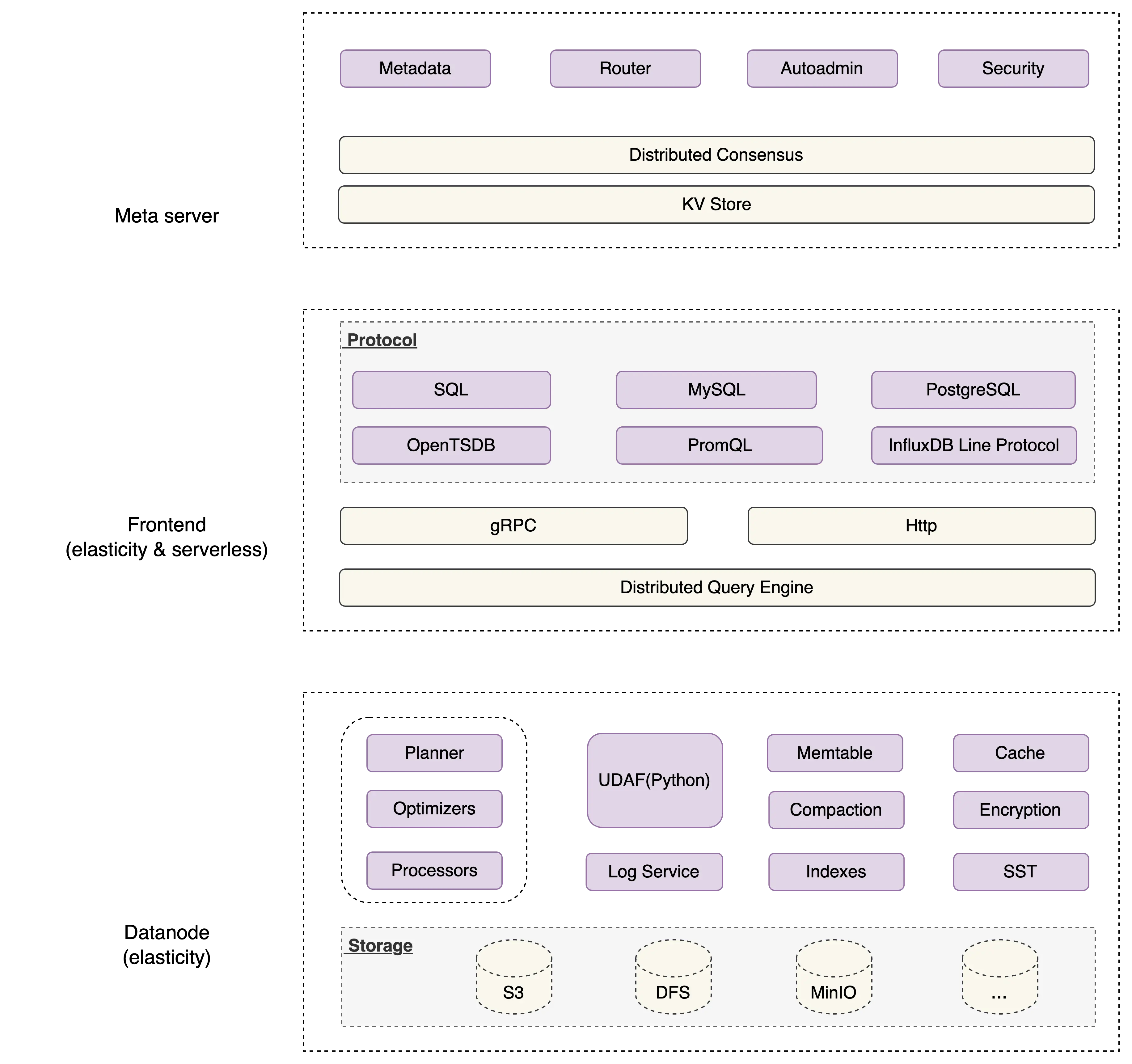
GreptimeDB 核心组件:
Frontend前端用于在各种协议中提供读写服务,将请求转发到DatanodeDatanode负责将数据存储到本地磁盘、S3 等持久化存储中Metaserver 后端负责协调Frontend和Datanode之间的操作
近日,GreptimeDB 发布了 0.1 版本,并在公告写道,自去年 11 月开源以来,已经近 4 个月,团队将之前设定的里程碑拆分成了 v0.1, v0.2 和 v0.3 三个小阶段,最终希望可以在 v0.3 交付一个单机可靠,分布式可用的产品。

以下内容摘录自 https://mp.weixin.qq.com/s/U0LdbvilVFpLBUK-zbRgrw。
GreptimeDB v0.1
Features
- Compaction
是的,作为一个 LSM Tree 架构怎能没有 Compaction,GreptimeDB 终于支持 Compaction 了。通过 Compaction 也支持了数据的基于 TTL 的淘汰。
- 支持对象存储
通过 OpenDAL, GreptimeDB 较容易地实现了对 S3 和 OSS 对象存储的支持。
- 支持使用 Python
引入 Python 脚本功能与 DataFrame API 以及第三方 Python 库的支持,可作为协处理器和用户自定义函数 (UDF) 使用。
- 原生支持 PromQL
PromQL 在云原生可观测领域已是公认使用最广泛的查询语言了。因此,尽管挑战很大,我们决定在 GreptimeDB 中原生支持 PromQL。目前我们已经初步实现了 PromQL 原生支持,尽管还不能通过官方兼容性测试中的所有 cases,但随着 GreptimeDB 0.1 版本发布,其已经初步可用。对于这个兼容性测试,我们计划在 GreptimeDB v0.2 版本中通过一半以上的 test cases,在 v0.3 版本中通过 70% 以上。
Protocol
- 新版高性能通信协议
基于 Arrow Flight RPC 构建,相比原来的 gRPC 私有协议,现在更加简洁高效,也很方便多种语言利用 Arrow Flight 的 SDK 直接与 GreptimeDB 通信。对 Stream 的支持也更方便。
文档见:https://docs.greptime.com/developer-guide/how-to/how-to-write-sdk
- MySQL & PostgreSQL 支持 TLS
为了数据的传输安全,MySQL 和 PostgreSQL 支持 TLS 是十分有必要的。另外与 HTTP 或 gRPC 不同,数据库协议有自己的 TLS 握手过程,因此我们在数据库这一层来支持了 TLS。
Clients
- 基于Arrow Flight RPC通信的Java SDK[1]
- 基于 Arrow Flight RPCGo SDK[2]正在开发
Refactor
- Datafusion &Arrow重构
GreptimeDB 最初重度使用了 Arrow2,但是 DataFusion 的 Arrow2 分支已不再维护,所以我们决定切换到 Arrow,这样我们就可以跟上最新的 DataFusion 版本了,这是一个具有巨大挑战的任务,很高兴我们顺利完成了。
除了以上列出的内容外,我们还有大大小小的 PRs 491 个,包括了各种功能准备,重构,bug 修复和文档完善等。另外,我们也将自己的一些经验回馈到开源社区,包括向 DataFusion[3],sqlness[4], Parquet2[5], Datafusion-Substrait[6], RustPython[7],OpenDAL[8] 等外部项目提交了贡献代码。
未来的计划
GreptimeDB
我们会按计划在 5 月份 release v0.3,目标是可达到单机可靠,分布式可用的程度。其中 “可靠” 主要体现在性能和稳定性上,但既然是单机,无论性能还是稳定性都是有一定上限,所以我们也会逐步完善分布式的版本。对于单机已经能满足要求的用户来讲,GreptimeDB v0.3 将会给到建议可用的单机版本。
而如果对可靠性和扩展性要求比较高的用户,我们也将在今年下半年完善分布式功能,计划年末提供分布式 GA ( General Availability ) 版本。
功能方面,我们还是会专注在数据的采集、存储和分析的生命周期,落地在用户实际场景问题,重点会在查询性能、存储降本和分布式方面,包括:
- PromQL 查询性能优化
- Python scripts 支持 MapReduce 框架,更高效地处理分布式计算
- 查询引擎的优化,向量化查询、智能索引和 Cost-Based Optimizer 等
- 存储和计算分离,存与算均可做到自动化伸缩
- 采用自适应压缩算法,一份数据支撑时序模型与分析模型的混合负载,降低存储成本