简介:Jdao是一种创新的持久层解决方案。主要目的在于 减少编程量,提高生产力,提高性能,支持多数据源整合操作,支持数据读写分离,制定持久层编程规范。 灵活运用Jdao,可以在持久层设计上,减少30%甚至50%以上的编程量,同时形成持久层的统一编程规范,减少持久层错误,同时易于维护和扩展。
核心价值:
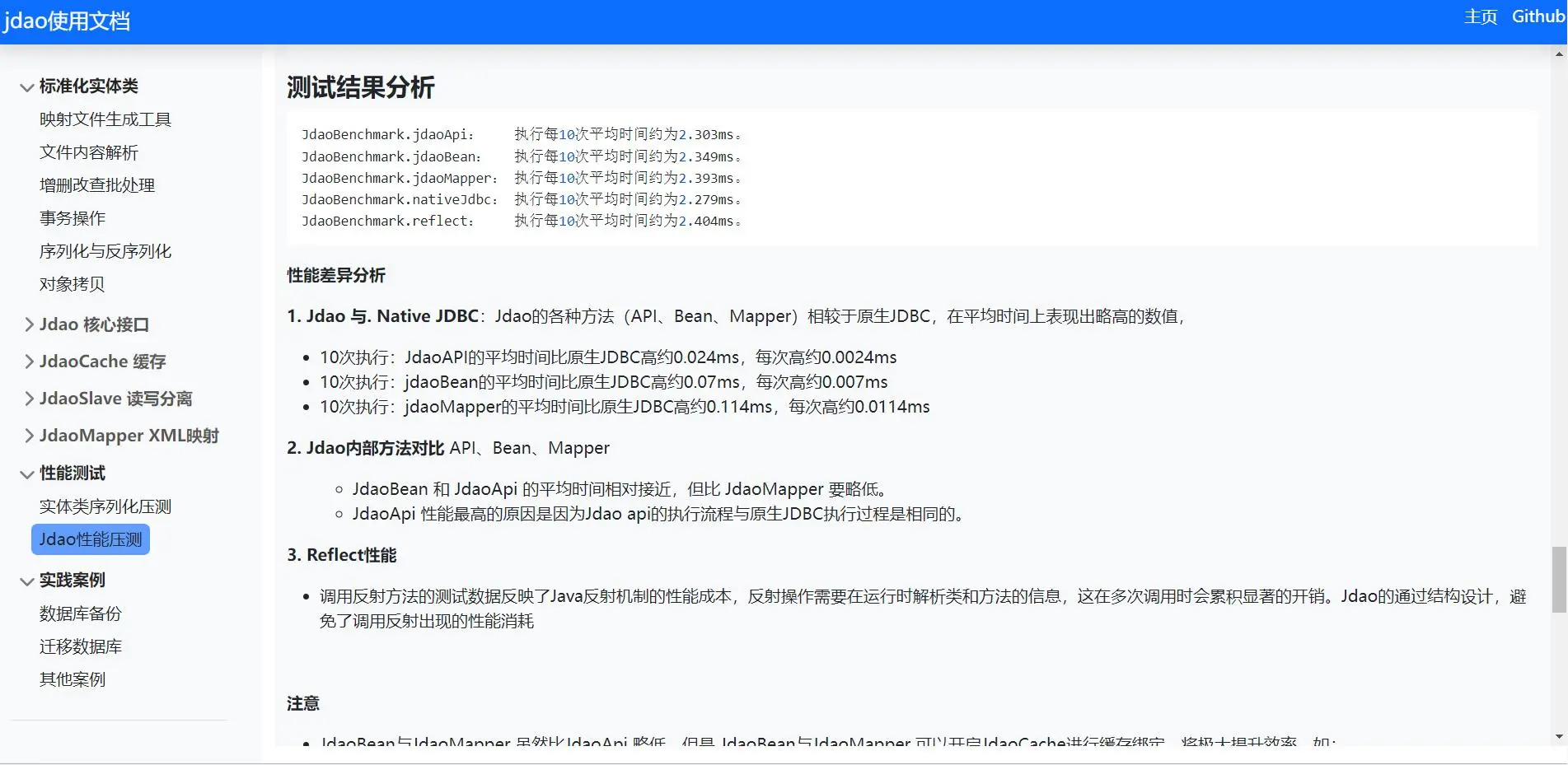
- 显著提升生产力: 减少30%-50%的编程工作量。
- 统一编程规范: 降低出错率,简化维护流程。
- 高性能: 支持高效序列化,速度提升近10倍,数据体积减小至20%。
- 多数据源整合: 支持数据读写分离及灵活的数据源管理。
- 高效安全的缓存机制: 查询效率提高400倍以上。
- 易于理解和使用: 即使初次接触也能迅速上手。
关键特性:
- 自动化表映射: 自动生成标准化实体类,类似Thrift/Protocol Buffers。
- 高效序列化: 实体类内置高速序列化机制。
- 数据读写分离: 支持多数据源配置,灵活管理读写负载。
- 智能缓存管理: 细致控制缓存策略,包括缓存时效,数据回收机制。
- 广泛兼容: 兼容所有遵循JDBC标准的数据库。
- 高级功能: 包括事务管理、存储过程和批处理等数据库高级功能
- SQL文件映射: 类似MyBatis,支持SQL与业务逻辑分离。
解决Hibernate与MyBatis痛点的新方案
- Hibernate普遍认为存在的问题
- 过度封装:hibernate提供了一层高级的抽象(包括HQL),这有助于开发者专注于业务逻辑而不是底层的SQL,这是一种更高级的编程模型 但它高度自动化虽然减少了对SQL的理解需求,同时却也掩盖底层数据库的具体行为,这可能导致性能瓶颈难以定位和优化
- 复杂性:配置和学习曲线陡峭,对于大型项目可能引入不必要的复杂度,尤其是当需要进行细粒度控制时。
- 性能问题:反射和代理机制在高并发场景下可能影响性能,尤其是在大规模数据处理时。
- MyBatis 普遍认为存在的问题
- SQL的维护:MyBatis 提供了通过 XML 配置文件将 SQL 与 Java 代码分离的功能,这种方式提高了灵活性,使开发者可以直接编写和优化 SQL。然而,将所有 SQL 都与代码分离,可能会导致大量的SQL配置。这无疑增加了配置的复杂度和维护的工作量。特别是在团队协作环境中, 过多的SQL或Xml文件还可能引发版本管理和合并冲突的问题。
- 重复工作:在 MyBatis 中,每个 DAO 都需要编写相似的 SQL 语句和结果映射逻辑。这种重复性工作不仅增加了开发时间,还容易引入错误,导致代码维护的复杂性增加。尤其是在处理常见的 CRUD 操作时,重复编写相似的 SQL 语句显得非常低效。
JDAO 的创新解决方案
融合优势 JDAO框架结合了Hibernate的抽象层次和MyBatis的灵活性,旨在提供一个既强大又直观的持久层解决方案。
-
- 标准化映射实体类,处理单表CRUD操作:90%以上的数据库单表操作,可用通过实体类操作完成。这些对单表的增删改查操作,一般不涉及复杂的SQL优化,由实体类封装生成,可以减少错误率,更易于维护。 利用缓存,读写分离等机制,在优化持久层上,更为高效和方便 标准化实体类的数据操作格式并非简单的java对象函数的拼接,而是更类似SQL操作的对象化,使得操作上更加易于理解。
- 复杂SQL的执行:在实践中发现,复杂SQL,特别是多表关联的SQL,通常需要优化,这需要对表结构,表索引性质等数据库属性有所了解。 而将复杂SQL使用 java对象进行拼接,通常会增加理解上的难度。甚至,开发者都不知道对象拼接后的最终执行SQL是什么,这无疑增加了风险和维护难度。 因此Jdao在复杂SQL问题上,建议调用Jdao的CURD接口执行,Jdao提供了灵活的数据转换和高效的javaBean映射实现,可以避免过渡使用反射等耗时的操作。
- 兼容myBatis映射文件: 对于复杂的sql操作,jdao提供了相应的crud接口。同时也支持通过xml配置sql进行接口映射调用,这点与mybatis特性相似,区别在于mybatis需要映射所有SQL操作。 而Jdao虽然提供了完整的sql映射接口,但是建议只映射复杂SQL,或操作部分标准实体类无法完成的CURD操作。 jdao的SQL配置文件参考mybatis配置文件格式,并实现新的解析器,使得配置参数在类型上的容忍度上更高,更灵活。(具体可以参考文档)
快速入门:
-
- 访问 GitHub 获取源码和示例。
- 查看 Demo 了解实际应用案例。
- 阅读 使用文档 掌握详细用法。
- 浏览 官方网站 获得更多信息和支持。
程序简单介绍
使用Jdao,所有功能只需要4个入口,分别为:
1. Jdao
主要核心入口,提供以下功能:
- 设置数据源
- SQL CRUD 函数
2. JdaoCache
缓存入口,支持以下功能:
- 绑定或移除包、类等属性,开启或移除它们的查询缓存
3. JdaoSlave
读写分离操作入口,支持以下功能:
- 绑定或移除包、类等属性,开启或移除它们的读写分离操作
4. JdaoMapper
映射 SQL 与接口,支持以下功能:
- 直接调用 Jdao 接口操作 SQL
- 通过 XML 文件进行 SQL 映射
快速入门
1. 安装 jdao依赖包
# 使用 Maven 安装
<dependency>
<groupId>io.github.donnie4w</groupId>
<artifactId>jdao</artifactId>
<version>2.0.1</version>
<scope>compile</scope>
</dependency>
2. 配置数据源
Jdao.init(dataSource,Jdao.MYSQL);
// dataSource 为数据源
// Jdao.MYSQL 为数据库类型
3. 生成表标准化实体类
使用 Jdao 代码生成工具生成数据库表的标准化实体类。
4. 实体类增删改查等操作
//数据源设置
Jdao.init(dataSource,Jdao.MYSQL);
// 读取
Hstest t = new Hstest();
t.where(Hstest.ID.GT(1));
t.limit(20,10);
List<Hstest> list = t.selects(Hstest.Id);
for (Hstest hstest : list) {
System.out.println(hstest);
}
// [SELECT SQL] selectid from hstest where id> ? limit ?,? [1,10,10]
// 更新
Hstest t = new Hstest();
t.SetValue("hello world")
t.where(Hstest.ID.EQ(1));
t.update()
//[UPDATE SQL] update hstest set value=? where id=? ["hello world",1]
// 删除
Hstest t = new Hstest();
t.where(Hstest.ID.EQ(1));
t.delete()
//[DELETE SQL]delete from hstest where id = ? [1]
// 新增
Hstest hs = new Hstest();
hs.setRowname("hello world");
hs.setValue("123456789");
hs.insert();
//[INSERT SQL] insert to hstest (rowname,value) values(?,?) ["hello world","123456789"]
5. Jdao
CRUD操作
//查询,返回单条
Hstest hs =Jdao.executeQuery(Hstest.class,"select * from Hstestorder by id desc limit 1");
System.out.println(hs);
//insert
inti = Jdao.executeUpdate("insert into hstest2(rowname,value) values(?,?)", "helloWorld", "123456789");
//update
inti = Jdao.executeUpdate("update hstest set value=? where id=1", "hello");
//delete
inti = Jdao.executeUpdate("delete from hstest where id = ?", 1);
6. JdaoCache
配置缓存
//绑定Hstest.class启用缓存, 缓存时效为 100毫秒
JdaoCache.bindClass(Hstest.class,new CacheHandle(100));
Hstest t = new Hstest();
t.where(Hstest.ID.EQ(3));
Hstest hs = t.select();
System.out.println(hs);
//返回缓存数据结果
Hstest t2 = new Hstest();
t2.where(Hstest.ID.EQ(3));
Hstest hs2 = t2.select();
System.out.println(hs2);
7. JdaoSlave
读写分离
JdaoSlave.bindClass(Hstest.class, DataSourceFactory.getDataSourceByPostgreSql(), DBType.POSTGRESQL);
//这里主数据库为mysql,备数据库为postgreSql,Hstest读取数据源为postgreSql
Hstest t = new Hstest();
t.where(Hstest.ID.EQ(3));
Hstest hs = t.select();
System.out.println(hs);
8. JdaoMapper
使用 XML 映射 SQL
<!-- MyBatis 风格的 XML 配置文件 -->
<mapper namespace="io.github.donnie4w.jdao.action.Mapperface">
<select id="selectHstestById" parameterType="int" resultType="io.github.donnie4w.jdao.dao.Hstest">
SELECT * FROM hstestWHERE id < #{id} and age < #{age}
</select>
</mapper>
//初始化数据源
Jdao.init(DataSourceFactory.getDataSourceBySqlite(), DBType.SQLITE);
//读取解析xml配置
JdaoMapper.build("mapper.xml");
JdaoMapper jdaoMapper = JdaoMapper.newInstance()
Hstest hs = jdaoMapper.selectOne("io.github.donnie4w.jdao.action.Mapperface.selectHstestById", 2, 26);
System.out.println(hs);
mapper 映射为java接口
public interface Mapperface {
List<Hstest> selectAllHstest();
List<Hstest> selectHstest(int id, int age);
Hstest selectHstestByMap(Map map);
List<Hstest> selectHstestByList(int id, int age);
Hstest[] selectHstestByList(List list);
Hstest selectHstestById(int id, int age);
List<Hstest> selectHstestById(Integer id, Integer age);
Hstest1 selectHstest1(int limit);
List<Hstest1> selectHstest1(long limit);
int insertHstest1(Hstest1 hs);
int updateHstest1(Hstest1 hs);
int deleteHstest1(Hstest1 hs);
}
@Test
public void selectMapperFace() throws JdaoException, JdaoClassException, SQLException {
JdaoMapper jdaoMapper = JdaoMapper.newInstance();
Mapperface mapper = jdaoMapper.getMapper(Mapperface.class);
List<Hstest> list = mapper.selectHstestById(Integer.valueOf(5), Integer.valueOf(20));
for (Hstest hs : list) {
System.out.println(hs);
}
Hstest hstest = mapper.selectHstestById(5, 20);
System.out.println(hstest);
}
更多详细信息和实践示例,请查阅 Jdao使用文档