腾讯宣布开源可控视频生成框架 MimicMotion,该框架可以通过提供参考人像及由骨骼序列表示的动作,来产生平滑的高质量人体动作视频。
公告称,大量的实验结果和用户调研表明MimicMotion在各种方面都显著优于以往的方法。目前模型及配套代码均已开源。
与以往的方法相比,MimicMotion具有以下几个亮点:
- 首先,通过引入了置信度感知的姿态引导信号,大幅提升了帧间一致性,使得产生的视频在时序上能够做到平滑自然。
- 其次,通过放大置信度感知的区域损失,显著减少了图像失真,使得局部画面如人体手部细节得到了大幅改善。
-
最后,通过结合扩散过程的渐进式潜在特征融合策略,MimicMotion能够在有限的算力资源内生成无限长的视频同时保证画面连贯。
主要优势:
- 生成结果细节更清晰 (尤其是手部细节);
- 生成视频时序平滑度更好,无明显闪烁;
- 能够生成长视频并且无明显跳变。
架构设计
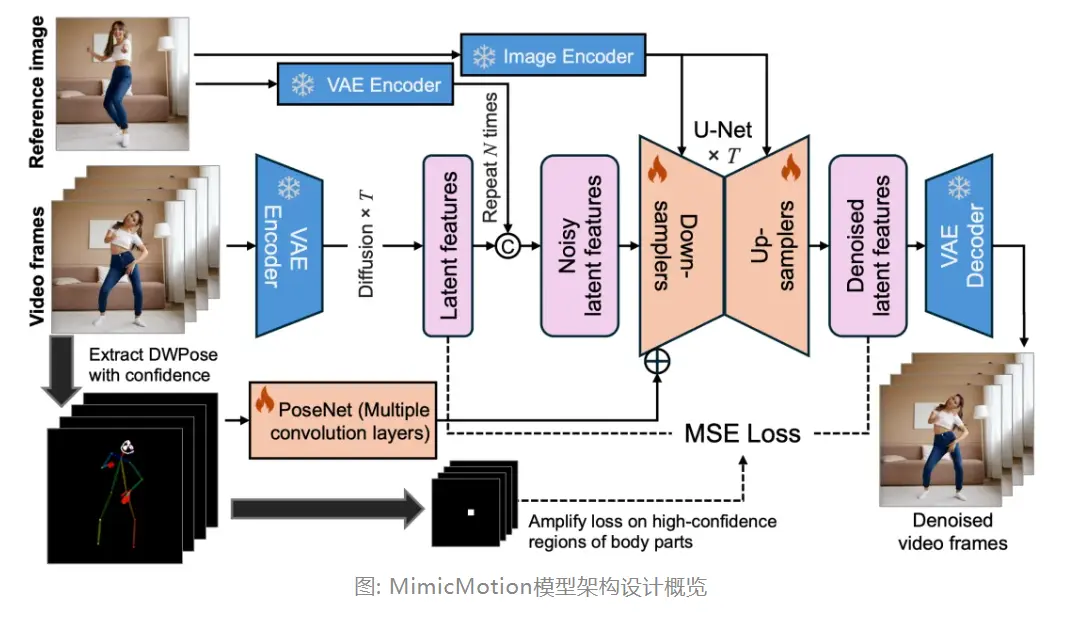
MimicMotion模型的核心结构是一个带有U-Net的隐空间视频扩散模型,用于在隐空间中进行逐步去噪。输入视频帧的VAE编码器和相应的解码器用于获取去噪视频帧,这些部分都加载了Stable Video Diffusion (SVD)预训练参数并将其冻结。VAE编码器独立地应用于输入视频的每一帧以及条件参考图像,基于逐帧操作,不考虑时间或跨帧交互。不同的是,VAE解码器处理经过U-Net时空交互的隐特征。为了确保生成流畅的视频,VAE解码器在空间层外加入了时间层,以镜像VAE编码器的架构。
除了输入视频帧之外,参考图像和姿态序列是模型的另外两个输入。参考图像通过两个独立的路径输入到扩散模型中。一个路径是将图像输入到U-Net的每个模块中。具体来说,通过类似CLIP的视觉编码器,提取图像特征并将其输入到每个U-Net模块的交叉注意力中,以最终控制输出结果。另一个路径针对输入的隐特征。与原始视频帧类似,输入的参考图像使用相同的冻结VAE编码器进行编码,以在隐空间中获得其表示。然后,单个参考图像的隐特征沿着时间维度复制,以与输入视频帧的特征对齐。复制的隐参考图像与隐视频帧沿通道维度连接在一起,然后一起输入到U-Net中进行扩散。
为了引入姿态的指导,PoseNet被设计为一个可训练的模块,用于提取输入姿态序列的特征,它由多个卷积层实现。不使用VAE编码器的原因是姿态序列的像素值分布与VAE自编码器训练的普通图像不同。通过PoseNet提取姿态特征,然后逐元素地添加到U-Net第一个卷积层的输出中。这样,姿态指导的影响可以从去噪的一开始就发挥作用。

MimicMotion在生成多种形式的人体动作视频上均具有良好的结果,包括半身动作、全身动作以及谈话动作视频。相比现有的开源方案如MagicPose、Moore-AnimateAnyone等;
MimicMotion具有以下几点优势:
1. 生成结果细节更加丰富且清晰,包括人体手部细节;
2. 帧间连续性更加优秀,画面无明显跳变;
3. 支持平滑的长视频生成。
在量化指标评估实验中,MimicMotion相比现有开源方案MagicPose、Moore-AnimateAnyone以及MuseV,在FID-VID及FVD测试指标上均取得了领先。
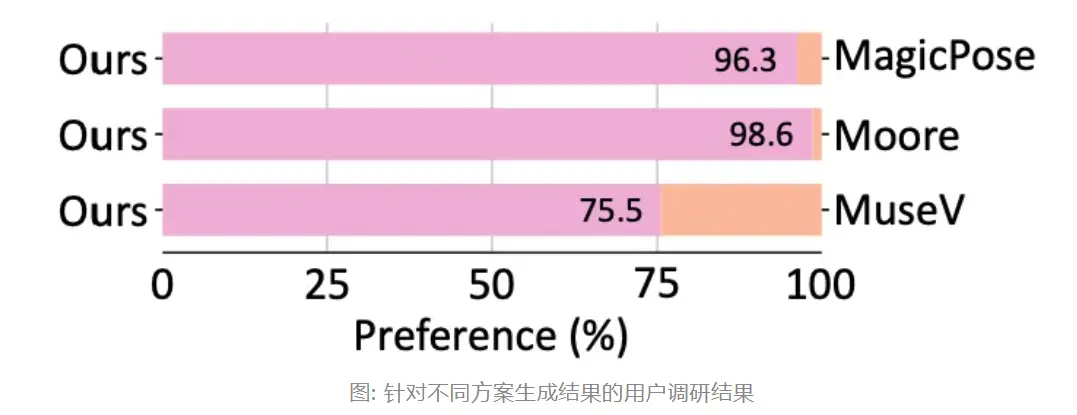
考虑生成结果对于用户的直观感受,在由36位人员参与的用户调研中,MimicMotion获得了75.5%以上的优胜率。
- 官方网站:https://tencent.github.io/MimicMotion
- 代码仓库:https://github.com/Tencent/MimicMotion
- 论文地址:https://arxiv.org/abs/2406.19680