AutoMQ 介绍
Apache Kafka 自诞生之日起,就以其卓越的设计和强大的功能,很快成为了流系统领域的事实标准。它不仅定义了现代流系统的架构,更以其独特的分布式日志抽象,为实时数据流的处理和分析提供了前所未有的能力。Kafka 的成功,在于它能够满足各种规模企业对于高吞吐量、低延迟数据处理的需求,经过多年的发展铸就了极其丰富的 Kafka 生态并被广泛应用于各种生产场景。 然而,随着云计算和云原生技术的飞速发展,Kafka 面临的挑战也日益严峻。传统的存储架构已难以适应云环境下用户对更优成本、弹性的诉求,这引发了大家对 Kafka 存储模型的重新思考。分层存储(Tiered Storage)一度被视为可能的解决方案,它试图通过将数据分层存储在不同的介质上,来降低成本并延长数据的生命周期。但实践表明,这种方法并没有彻底解决 Kafka 的痛点,反而增加了系统的复杂性和运维难度。 AutoMQ 是一个源代码开放的 Kafka 分叉项目,通过存算分离的方式将 Kafka 的存储层替换成了基于 S3 和 EBS 的共享存储架构,并且复用了 Kafka 100% 的计算层代码,保证了对 Kafka API 协议和生态的完全兼容。如下图所示,通过这种创新的共享存储架构,不仅获得了共享存储带来的技术和成本优势,彻底解决了原有 Kafka 在成本、弹性等方面的弊病,同时不会牺牲延迟。与其他流系统的对比
| 特性 | AutoMQ | Apache Kafka | Confluent | Apache Pulsar | Redpanda | Warpstream |
| Apache Kafka 兼容性[1] | 原生 Kafka | 原生 Kafka | 原生 Kafka | 非 Kafka | Kafka 协议兼容 | Kafka 协议兼容 |
| 是否开源 | 是 | 是 | 否 | 是 | 是 | 否 |
| 无状态 Broker | 是 | 否 | 否 | 是 | 否 | 是 |
| P99 延迟 | 单位数毫秒延迟 | 单位数毫秒延迟 | 单位数毫秒延迟 | 单位数毫秒延迟 | 单位数毫秒延迟 | > 1200毫秒 |
| 持续自平衡 | 是 | 否 | 是 | 是 | 是 | 是 |
| 扩展/缩减效率 | 以秒计 | 以小时/天计 | 以小时计 | 以小时计(缩减); 以秒计(扩展) | 以小时计 以秒计 (仅限企业版) | 以秒计 |
| Spot 实例支持 | 是 | 否 | 否 | 否 | 否 | 是 |
| 分区重新分配 | 以秒计 | 以小时/天计 | 以小时计 | 以秒计 | 以小时计 以秒计 (仅限企业版) | 以秒计 |
| 组件 | 代理 | 代理 ZooKeeper (非 KRaft) | 代理 ZooKeeper (非 KRaft) | 代理 ZooKeeper BookKeeper 代理 (可选) | 代理 | 代理元数据服务器 |
| 持久性 | 由 S3/EBS 保证[2] | 由 ISR 保证 | 由 ISR 保证 | 由 BookKeeper 保证 | 由 Raft 保证 | 由 S3 保证 |
| 跨可用区网络费用 | 否 | 是 | 是 | 是 | 是 | 否 |
[1] Apache Kafka 兼容性的定义来自这篇 博客。
[2] EBS 持久性:在 Azure、GCP 和阿里云上,区域 EBS 副本跨多个可用区。在 AWS 上,通过在不同可用区的 EBS 和 S3 Express One Zone 进行双写来确保持久性。
创新的存储架构
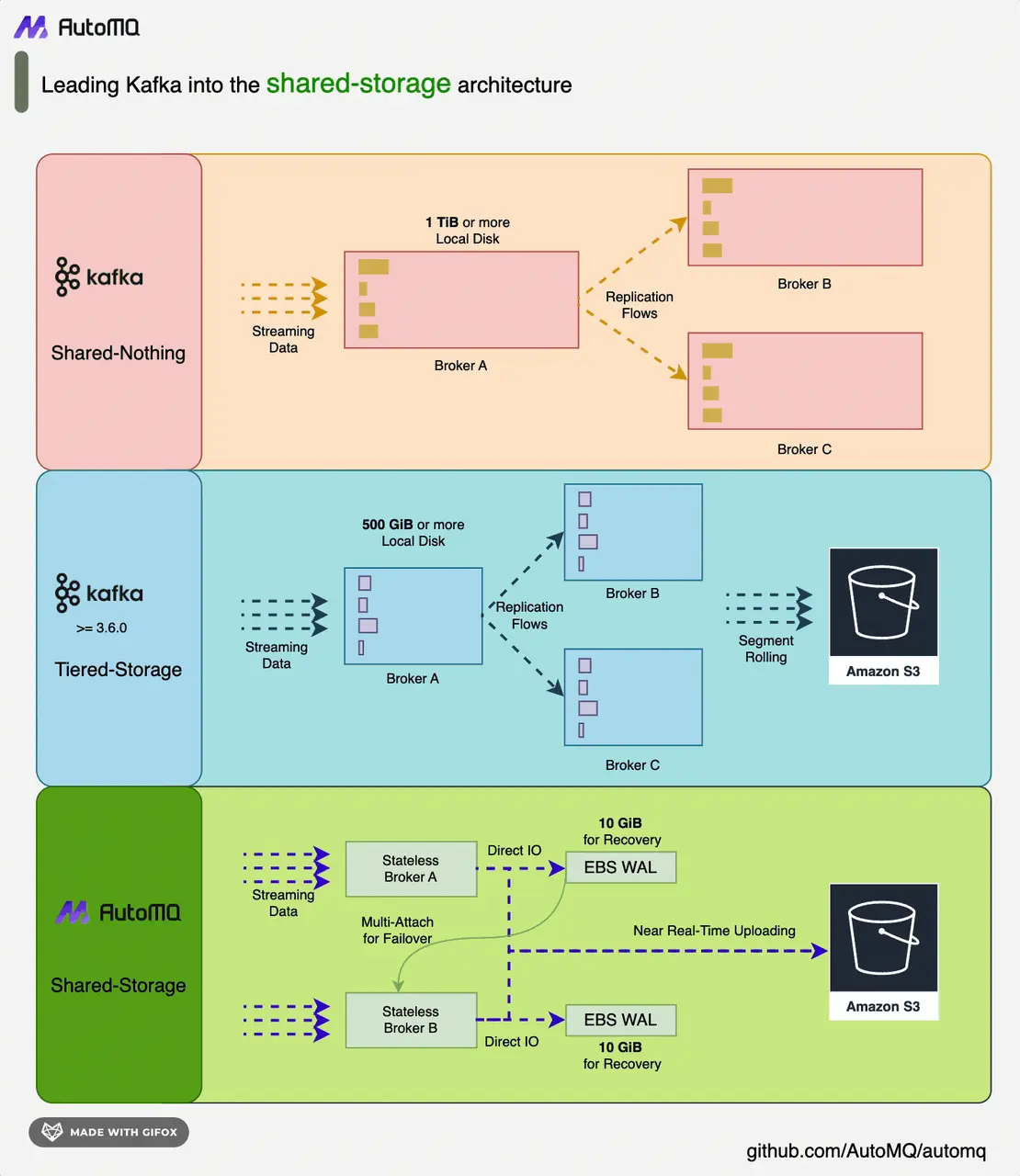
更新内容
- docs(metrics):完善遥测自述文件并删除未使用的组件 ,作者@SCNieh,PR # 1333
- fix(issues1334):修复流读取器无限循环 ,作者@superhx,PR # 1335
- fix(perf):增加管理客户端的请求超时时间 ,作者@Chillax-0v0,PR # 1336
- feat(core): 转发流 apis ,作者@ShadowySpirits,PR # 1338
- chore:设置整个仓库的代码所有者 ,作者@Chillax-0v0,PR # 1340
- feat(core): 添加命令配置 ,作者@ShadowySpirits,PR # 1342
- fix(auto_balancer): 修复 broker 状态改变 ,作者@SCNieh,PR # 1339
- feat(metadata):为旧流添加缺失的标签 ,作者@superhx,PR # 1346
- fix(s3stream):改进网络速率限制器以提高精度 ,作者@SCNieh,PR # 1344
- fix(s3stream):修复变量拼写错误 ,作者@yx9o,PR # 1351
- docs(telemetry):通过以下方式简化 grafana 仪表板模板 ,作者@SCNieh,PR # 1354
- feat(shell): 删除 automq cli ,作者@ShadowySpirits,PR # 1355
- feat(core): 在控制器事件循环中记录块操作 ,作者@ShadowySpirits,PR # 1352
- fix(s3stream):暂时禁用百分位指标以解决性能问题 ,作者@SCNieh,PR # 1353
- perf(s3stream/allocator):增加 netty 分配器的主干大小 ,作者@Chillax-0v0,PR # 1364
- fix(issues1357):修复从快照加载时丢失的删除问题 ,作者@superhx,PR # 1358
- chore(log): 修复日志 ,作者@superhx,PR # 1365
- fix(s3stream):修复不匹配的占位符 ,作者@yx9o,PR # 1369
- feat(shell): 为 automq cli 添加基本命令 ,作者@ShadowySpirits,PR # 1370
- fix(issues1367):流读取器阻止添加无效块 ,作者@superhx,PR # 1372
-
chore(s3stream):添加
toString修复日志的方法 ,作者@Chillax-0v0,PR # 1381 - fix(cache):修复当用户读取速度快于预读时读头失败的问题 ,作者@superhx,PR # 1382
- fix(core):当附加非零序列号且生产者快照为空时,增加容忍延迟( #1377) ,作者@SCNieh,PR # 1384
-
refactor(s3stream):删除对
DefaultS3Client的依赖KafkaConfig,作者@Chillax-0v0,PR # 1388 - fix(issues604):修复响应大小不匹配的问题 ,作者@superhx,PR # 1392
- feat(tools/perf):在预热和追赶过程中调整发送速率 ,作者@Chillax-0v0,PR # 1395
- feat(s3stream): 添加新的对象存储摘要 ,作者@superhx,PR # 1396
- fix(action): 修复发布操作 ( #1398 ) ,作者@superhx,PR # 1399
- feat(core): 优化控制器事件循环中的块操作日志 ,作者@ShadowySpirits,PR # 1403
- fix(auto_balancer):删除不必要的地图副本 ,作者@SCNieh,PR # 1404
- feat(core): 使控制器构建器可扩展 ,作者@SCNieh,PR # 1406
-
perf(s3stream):减少锁定
StreamMetadataManager粒度 ,作者@lifepuzzlefun,PR # 1411 - fix(TimeIndex):等待最后一次追加完成后再通过以下方式获取流: ,作者@Chillax-0v0,PR # 1407
- feat(auto_balancer): opt 集群模型接口 ,作者@SCNieh,PR # 1414
-
chore(EventQueue):增加
EVENT_PROCESS_TIME_THRESHOLD_MICROSECOND至 5ms ,作者@Chillax-0v0,PR # 1412 - fix(cache):修复重新创建主题的缓存重用问题 ,作者@superhx,PR # 1417
- perf(matadata):使用时间轴对对象进行图像处理 ,作者@superhx,PR # 1419
- feat(s3stream):为对象存储添加 aws s3 rangeRead 实现 ,作者@warr99,PR # 1416
- fix(metadata):修复元数据访问过期图像的问题 ,作者@superhx,PR # 1420
- fix(core):修复文件缓存意外截断 ,作者@ShadowySpirits,PR # 1421
- feat(core): 仅在活动控制器上报告 s3 对象编号 ,作者@SCNieh,PR # 1424
- perf(FileCache): 避免一次性驱逐太多块 ,作者@Chillax-0v0,PR # 1425
- feat: 从 apache kafka 3.8 0971924合并 ,作者@superhx,PR # 1427
- fix(docs):修复贡献指南 ,作者@jitokim,PR # 1428
- chore(examples):删除 TransactionProducer 中的硬编码值 ,作者@jitokim,PR # 1426
- fix(config):修复自动平衡器监听器名称的默认配置 ,作者@SCNieh,PR # 1429
- fix(tools/perf):丢弃无效的延迟值 ,作者@Chillax-0v0,PR # 1430
- test(s3stream):添加 objectStorage rangeRead 测试 ,作者@warr99,PR # 1423
- feat(s3stream):通过以下方式添加用于对象存储的 aws s3 写入实现 ,作者@warr99,PR # 1434
- fix(auto_balancer):修复版本 V0 的指标兼容性 ,作者@SCNieh,PR # 1433
- fix(auto_balancer):当侦听器名称未指定时匹配所有端点…通过 ,作者@SCNieh,PR # 1435
- feat(s3stream): 复合对象读写器 ,作者@superhx,PR # 1432
- feat(s3stream):通过以下方式添加 s3 多部分实现,用于对象存储 ,作者@warr99,PR # 1438
- feat(s3stream):复合对象通过添加对象属性 ,作者@superhx,PR # 1437
- fix(s3stream/wal):启动前检查块大小 ,作者@Chillax-0v0,PR # 1439
- feat(tools): 修复 StorageTool ,作者@ShadowySpirits,PR # 1442
- feat(s3stream): 通过以下方式压缩为复合对象 ,作者@superhx,PR # 1443
- feat(s3stream): 通过添加复合对象删除 ,作者@superhx,PR # 1444
- feat(s3stream):为对象存储添加 s3 删除实现 ,作者@warr99,PR # 1441
- perf(s3stream):避免在写入路径上创建非重用 TimerUtil 对象 ,作者@lifepuzzlefun,PR # 1447
- feat(s3stream): 对象存储编写者 ,作者@warr99,PR # 1445
- feat(s3stream): 添加流对象压缩 v1 触发器 ,作者@superhx,PR # 1448
- feat(issue1134):通过以下方式防止琐碎调度 ,作者@SCNieh,PR # 1449
- feat(auto_balancer):仅在必要时移动内部主题分区 ,作者@SCNieh,PR # 1450
- feat(s3stream):通过以下方式适应新的对象存储抽象 ,作者@superhx,PR # 1451
- feat(core): 通过以下方式实现代理和集群级别的配额 ,作者@ShadowySpirits,PR # 1440
- fix:通过流 e2e ,作者@superhx,PR # 1453
- feat:添加复合对象测试 ,作者@superhx,PR # 1454
- feat(s3stream): 通过以下方式集成复合对象 ,作者@superhx,PR # 1456
- fix(test):修复 e2e ,作者@superhx,PR # 1457
- test(s3stream):添加测试用例来验证对象末尾的读取行为 ,作者@warr99,PR # 1455
- feat(auto_balancer):重构集群负载快照以实现更好的扩展…… ,作者@SCNieh,PR # 1459
- chore:更新 README.md ,作者@wensongz,PR # 1460
- refactor(license):通过以下方式将许可证文件组织在一起 ,作者@KaimingWan,PR # 1458
- chore:为 s3stream 添加自述文档 ,作者@daniel-y,PR # 1461
- feat(issue1462): 优化 Readme。 #1462来自 ,作者@vintagewang,PR # 1463
- feat(s3stream):通过以下方式实现 S3 Write-Ahead Log 的原型 ,作者@ShadowySpirits,PR # 1465
- feat(s3stream):消除对流范围偏移的依赖 ,作者@SCNieh,PR # 1466
- feat(metadata): 优化 streamsetobject 以支持大型集群 ,作者@superhx,PR # 1464
- fix(test):修复连接 e2e 任务超时 ,作者@superhx,PR # 1467
- fix(test):跳过不支持的测试 ,作者@superhx,PR # 1468
- fix(s3stream):确保 wal 标头关闭类型在启动时不正常 ,作者@lifepuzzlefun,PR # 1469
- chore(all): 适应 java21 ,作者@superhx,PR # 1471
- feat(s3stream): 通过以下方式实现 AcknowledgmentService ,作者@ShadowySpirits,PR # 1470
- feat(core):通过以下方式为 TelemetryManager 添加扩展点 ,作者@SCNieh,PR # 1472
- fix(auto_balancer):修复代理状态 ,作者@SCNieh,PR # 1480
- fix(auto_balancer):当没有分区时,从集群模型中删除分区…… ,作者@SCNieh,PR # 1484
- fix(auto_balancer):修复从集群中删除分区时出现 npe 的问题 ,作者@SCNieh,PR # 1486
- fix(api): 修复当遇到NOT_CONTROLLER时频道无法切换的问题 ,作者@superhx,PR # 1489
- fix(s3shell): 修复对象清理 ,作者@ShadowySpirits,PR # 1491
- fix(s3stream):修复当转到重试逻辑时 IO CompletableFuture 永远无法完成的问题 ,作者@lifepuzzlefun,PR # 1487
- build(aws):将 aws sdk 版本升级到 2.26.10 ,作者@SCNieh,PR # 1494
- build(netty):升级 netty 版本至 4.1.111 ,作者@SCNieh,PR # 1495
- refactor(s3stream):重构对象存储 ,作者@superhx,PR # 1498
- fix(s3stream):修复在 S3ObjectsImage 中更新 liveEpoch 时锁定保护 ,作者@lifepuzzlefun,PR # 1493
- build(gradle):通过以下方式启用 Gradle 包装器验证 ,作者@sullis,PR # 1496
- feat(auto_balancer): 每次优化后记录 broker 负载变化 ,作者@SCNieh,PR # 1497
- fix(metadata):防止常量实例重复释放 ,作者@SCNieh,PR # 1500
- refactor(config):通过以下方式提取 automq 配置 ,作者@superhx,PR # 1501
- fix(s3stream):修复 s3 就绪检查 ,作者@superhx,PR # 1502
- fix(s3stream):使用段唯一 ID 作为文件缓存键 ,作者@SCNieh,PR # 1504
- fix(s3stream):避免在打开流后立即进行压缩 ,作者@Chillax-0v0,PR # 1505
- perf(s3stream):在 WAL io 执行器中使用 FastThreadLocal ,作者@lifepuzzlefun,PR # 1507
- feat(config):新的 bucket URI 配置 ,作者@superhx,PR # 1506
- fix(metadata): 修复快照后丢失的对象属性 ,作者@superhx,PR # 1508
- chore(test): 通过以下方式检查快照后的对象属性 ,作者@superhx,PR # 1509
- feat(s3stream):优化获取对象的性能 ,作者@SCNieh,PR # 1512
- perf(s3stream): 当压缩复合对象时批量删除对象 ,作者@lifepuzzlefun,PR # 1513
- feat(s3stream): 适应 bucket id ,作者@superhx,PR # 1514
- fix(s3stream):修复删除复合对象超出 S3 API 限制的问题 ,作者@lifepuzzlefun,PR # 1518
- fix:修复拼写错误 ,作者@szepeviktor,PR # 1516
- chore:通过以下方式引入 EditorConfig ,作者@szepeviktor,PR # 1511
- fix(s3stream):修复 streamsetobject 强制拆分失败问题 ,作者@lifepuzzlefun,PR # 1521
- fix(tool):修复生成 s3 url 工具区域 ,作者@lifepuzzlefun,PR # 1522
- fix(s3stream):优化 s3 请求异常的重试策略 ,作者@SCNieh,PR # 1524
- fix(issues1527):修复删除空列表 ,作者@superhx,PR # 1528
- fix(issue1526):避免在搜索完成之前完成未来 ,作者@SCNieh,PR # 1531
- fix(s3stream):避免使用 MAJOR_V1 紧凑复合对象本身 ,作者@lifepuzzlefun,PR # 1535
- feat(s3stream): 通过以下方式实现对象存储wal ,作者@ShadowySpirits,PR # 1538
- feat(config): 将自动平衡器默认平均偏差率降低至 0.1 ,作者@SCNieh,PR # 1543
- fix(config):修复 gcp bucket 解析问题 ,作者@warr99,PR # 1537
- fix(s3stream):复合对象使用保留大小 ,作者@superhx,PR # 1532
- fix(s3stream):通过 close 方法关闭所有执行器 ,作者@warr99,PR # 1529
- feat(e2e): kafka.py 除了 JVM 参数外,在启动时添加了额外的环境变量。 ,作者@llzcx,PR # 1536
- fix(issues1539):修复 auto-kafka-admin.sh 帮助信息。通过 ,作者@mapan1984,PR # 1541
- feat(s3stream): 重构配置 s3.wal.path ,作者@ShadowySpirits,PR # 1545
- feat(s3stream):通过以下方式在对象 WAL 恢复期间实现预读功能 ,作者@ShadowySpirits,PR # 1548
- fix(issue 1547):在 afterRead 中向 tryReadahead 添加异步回调。通过 ,作者@llzcx,PR # 1553
- feat(ci): 更新 github-release.yml ,作者@ShadowySpirits,PR # 1555
新贡献者
- @yx9o 在#1351中做出了第一笔贡献
- @jitokim 在#1428中做出了第一笔贡献
- @wensongz 在#1460中做出了第一笔贡献
- @vintagewang 在#1463中做出了第一笔贡献
- @sullis 在#1496中做出了第一笔贡献
- @szepeviktor 在#1516中做出了第一笔贡献
- @llzcx 在#1536中做出了第一笔贡献
- @mapan1984 在#1541中做出了第一笔贡献